APNS开源包的内存泄露问题
APNS(全称:Apple Push Notification Service),主要是用于往苹果设备推送push消息通知!
基本流程:
今天要聊的问题集中在第4个环节,我们自己的服务器往苹果的消息中心推送通知。
现状:
历史原因,push的代码散落在各个应用中,随着新消息通道不断接入,开发、维护成本较高,开始考虑构建push中心,
封装dubbo接口对外提供服务,对外屏蔽各种差异,将所有的push业务逐步收扰到push中心。
过程漫长,开始接入的是个人业务,每天的调用量不大,服务器还表现正常;
8月底,BI的推送管理后台开始对接进来并发布上线,由于BI是针对各种营销活动批量推送的,一次任务少则几万,多则上千万,
此时服务器开始暴露一些问题。
下面开始介绍优化过程:
1)第一次线上问题暴露,现象:短信报警,查看dubbo注册中心无provider服务,登录线上机器,load飙高到了40,ps看了jvm进程在,但dubbo日志里,服务注册失败。
查看gc,一直触发Full gc,old空间却释放不了
解决:重启集群。之前的策略是发送过来的数据会封装到一个线程任务里,由ThreadPoolExecutor慢慢消化,怀疑一次发送的token过多(一次400),生产速度快于消费速度,导致对象积累。联系BI的稀土同学,将一次任务的数量调整为100,并且每次调用接口后休眠100ms。
2)另外查看了jvm的参数,修改启动脚本,将原来的堆大小由1G调整为2G,新生代由原来的300M调整为1G
-Xms2g -Xmx2g -Xmn1g -XX:+UseParallelOldGC
了解BI的机器配置,24核cpu 64G内存,配置很高但只有一台,采用的是dubbo默认的随机路由方式,1对多,担心负载不均衡,
注:线上dubbo注册中心观察过,并不是所有的机器同时宕机,而是一个逐步的过程
调整路由策略,改为轮询方式:
更多内容可以参考 dubbo的开发手册
<dubbo:reference id="***" interface="******" loadbalance="roundrobin" />
3)这次持续的时间长了点,不过在任务跑了4个小时后,系统的old区占用到70%多,开始担心一会Full GC是否会正常回收。
由于采用的是UseParallelOldGC 并行回收方式(适用于吞吐量大应用类型),不象CMS可以设置空间使用比例主动触发回收。
但我们可以通过dump内存快照方式手动触发一次Full GC
jmap -dump:live,format=b,file=heap.bin <pid>
开始安装mat插件,分析内存快照,具体可参考《MAT使用教程》
发现有大量的SSLSocketImpl实例对象无法回收,整个链路占了heap 50%+
4) 这个问题比较棘手,因为我们使用的是一个外部开源框架;
只能网上先查查资料,看看有没有其他人遇到过类似问题;
很不幸没有找到现成答案,幸运的是在github上找到了源代码。
https://github.com/fernandospr/javapns-jdk16
不过也只有代码,并没有过多文档介绍,不过这不重要
自己动手,丰衣足食。
分析代码,发现两处疑点:
a)NotificationThreads 里面会根据预传的线程数量,创建n个线程,每个线程负责往一定数量设备发送消息,主线程为了收集n个线程的最终发送结果,NotificationThreads继承了ThreadGroup,并将对象实例传到每个子线程构造器中,对主线程wait,当所有的子线程执行完毕后,通过notifyAll唤醒所有进程,继续后面的流程。
貌似没有什么明显问题,但是mat的分析结果ThreadGroup里面有大量其它线程,担心会有干扰。决定采用一种更靠谱更安全的方式,通过CountDownLatch来控制。
b)在子任务结束后(无论是正常结束还是非正常结束),在finally里面进行后续操作,关闭socket连接;
另外 对 countDownLatch数量减1
重新打包并上传maven仓库(注意:需要修改pom配置文件)
<dependency> <groupId>com.github.fernandospr</groupId> <artifactId>javapns-jdk16</artifactId> <version>2.3.1-SNAPSHOT</version> </dependency>
本地运行单元测试,可以成功推送消息
c)线上集群部署了一台机器,开始beta测试,运行一个1200W的推送任务
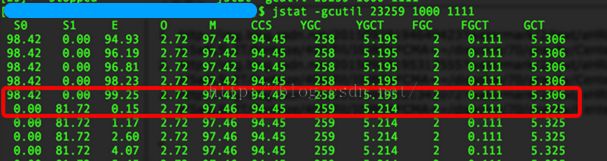
经过258次YGC后,年老代的空间使用率 依然很低,只有2%+
另外观察S0、S1、E发现,一次YGC后 to交换区基本能满足存放存活对象,不会有大量对象晋升到old区。
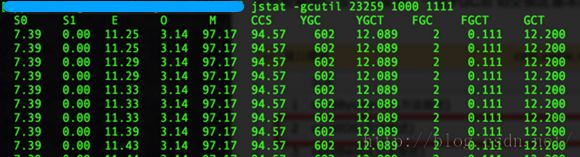
任务跑完后,gc情况,YGC 602次,没有触发Full GC

另外性能监控显示已经发送了800多万 条消息(注:图中统计的是接口调用次数,每次接口调用传100个用户token),响应时间正常。
总结:
a)线上报警,无论load彪的有多高,又或cpu使用率100%,千万不要慌,先保留一台问题机器,其它的机器全部重启,保证不影响外部使用
b)要从整个链路全面分析问题,多和身边的同事沟通讨论,也许会碰撞出灵感。
最后,非常感谢 错刀、金砖 ,处理过程中,提供了很多帮助!