EditPlus正则替换
/t 制表符.
/n 新行.
. 匹配任意字符.
| 匹配表达式左边和右边的字符. 例如, "ab|bc" 匹配 "ab" 或者 "bc".
[] 匹配列表之中的任何单个字符. 例如, "[ab]" 匹配 "a" 或者 "b". "[0-9]" 匹配任意数字.
[^] 匹配列表之外的任何单个字符. 例如, "[^ab]" 匹配 "a" 和 "b" 以外的字符. "[^0-9]" 匹配任意非数字字符.
* 其左边的字符被匹配任意次(0次,或者多次). 例如 "be*" 匹配 "b", "be" 或者 "bee".
+ 其左边的字符被匹配至少一次(1次,或者多次). 例如 "be+" 匹配 "be" 或者 "bee" 但是不匹配 "b".
? 其左边的字符被匹配0次或者1次. 例如 "be?" 匹配 "b" 或者 "be" 但是不匹配 "bee".
^ 其右边的表达式被匹配在一行的开始. 例如 "^A" 仅仅匹配以 "A" 开头的行.
$ 其左边的表达式被匹配在一行的结尾. 例如 "e$" 仅仅匹配以 "e" 结尾的行.
() 影响表达式匹配的顺序,并且用作表达式的分组标记.
/ 转义字符. 如果你要使用 "/" 本身, 则应该使用 "//".
正则表达式应用——删除空行 ^[ /t]*/n
表达式的分组使用()来标记. 表达式的分组可以被引用为 /0, /1, /2, /3, 等等. /0 表示被匹配的所有字符串. /1 表示被匹配的第一个分组, /2 表示第二个分组, 依此类推. 举例如下.
原文 查找 替换 结果
abc (ab)(c) /0-/1-/2 abc-ab-c
abc a(b)(c) /0-/1-/2 abc-b-c
abc (a)b(c) /0-/1-/2 abc-a-c
下面的方法将把html文件中类似于<str>的非html标记的尖括号替换掉。
例如,将<str>用下面方法替换的结果是:<str>
这里只提供了解决问题的思路。具体的应用,要看具体的情况。
查找内容:<([^/htbpl][^ >]*)>
替换内容:<\1>
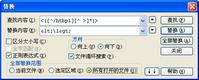
解释:<([^/htbpl][^ >]*)> ---要查找的尖括号包围的字串。
其中:(……) ---括号表示先把括号中的内容保存起来,待后面引用。
[^/htbpl] ----表示尖括号内第一个字符不是/、h(tml)、t(itle)、b(ody)等
[^ > ]* ----表示后面跟若干(*)个非(^)>、非空格的字符。
\1 ----editplus中的特殊用法,表示对原字符串中括号内字串的引用。等价于正则表达式中的$1。
EditPlus正则表达式替换字符串详解
网上搜集了些实例
正则表达式是一个查询的字符串,它包含一般的字符和一些特殊的字符,特殊字符可以扩展查找字符串的能力,正则表达式在查找和替换字符串的作用不可忽视,它能很好提高工作效率。
EditPlus的查找,替换,文件中查找支持以下的正则表达式:
Expression Description
\t Tab character.
\n New line.
. Matches any character.
| Either expression on its left and right side matches the target string.
For example, “a|b” matches “a” and “b”.
[] Any of the enclosed characters may match the target character.
For example, “[ab]” matches “a” and “b”. “[0-9]” matches any digit.
[^] None of the enclosed characters may match the target character.
For example, “[^ab]” matches all character EXCEPT “a” and “b”.
“[^0-9]” matches any non-digit character.
* Character to the left of asterisk in the expression should match 0 or more times.
For example “be*” matches “b”, “be” and “bee”.
+ Character to the left of plus sign in the expression should match 1 or more times.
For example “be+” matches “be” and “bee” but not “b”.
? Character to the left of question mark in the expression should match 0 or 1 time.
For example “be?” matches “b” and “be” but not “bee”.
^ Expression to the right of ^ matches only when it is at the beginning of line.
For example “^A” matches an “A” that is only at the beginning of line.
$ Expression to the left of $ matches only when it is at the end of line.
For example “e$” matches an “e” that is only at the end of line.
() Affects evaluation order of expression and also used for tagged expression.
\ scape character. If you want to use character “\” itself, you should use “\\”.
例子:
原始串
str[1]abc[991];
str[2]abc[992];
str[11]abc[993];
str[22]abc[994];
str[111]abc[995];
str[222]abc[996];
str[1111]abc[997];
str[2222]abc[999];
目标串:
abc[1];
abc[2];
abc[11];
abc[22];
abc[111];
abc[222];
abc[1111];
abc[2222];
处理:
查找串:str\[([0-9]+)\]abc\[[0-9]+\]
替换串:abc[\1]
【1】正则表达式应用——替换指定内容到行尾
原始文本如下面两行
abc aaaaa
123 abc 444
希望每次遇到“abc”,则替换“abc”以及其后到行尾的内容为“abc efg”
即上面的文本最终替换为:
abc efg
123 abc efg
解决:
① 在替换对话框,查找内容里输入“abc.*”
② 同时勾选“正则表达式”复选框,然后点击“全部替换”按钮
其中,符号的含义如下:
“.” =匹配任意字符
“*” =匹配0次或更多
注意:其实就是正则表达式替换,这里只是把一些曾经提出的问题加以整理,单纯从正则表达式本身来说,就可以引申出成千上万种特例。
【2】正则表达式应用——数字替换
希望把
asdadas123asdasdas456asdasdasd789asdasd
替换为:
asdadas[123]asdasdas[456]asdasdasd[789]asdasd
在替换对话框里面,勾选“正则表达式”复选框;
在查找内容里面输入“[0-9][0-9][0-9]”,不含引号
“替换为:”里面输入“[\0\1\2]”,不含引号
范围为你所操作的范围,然后选择替换即可。
实际上这也是正则表达式的使用特例,“[0-9]”表示匹配0~9之间的任何特例,同样“[a-z]”就表示匹配a~z之间的任何特例
上面重复使用了“[0-9]”,表示连续出现的三个数字
“\0”代表第一个“[0-9]”对应的原型,“\1”代表第二个“[0-9]”对应的原型,依此类推
“[”、“]”为单纯的字符,表示添加“[”或“]”,如果输入“其它\0\1\2其它”,则替换结果为:
asdadas其它123其它asdasdas其它456其它asdasdasd其它789其它asdasd
功能增强(by jiuk2k):
如果将查找内容“[0-9][0-9][0-9]”改为“[0-9]*[0-9]”,对应1 或 123 或 12345 或 …
大家根据需要定制
相关内容还有很多,可以自己参考正则表达式的语法仔细研究一下
【3】正则表达式应用——删除每一行行尾的指定字符
因为这几个字符在行中也是出现的,所以肯定不能用简单的替换实现
比如
12345 1265345
2345
需要删除每行末尾的“345”
这个也算正则表达式的用法,其实仔细看正则表达式应该比较简单,不过既然有这个问题提出,说明对正则表达式还得有个认识过程,解决方法如下
解决:
在替换对话框中,启用“正则表达式”复选框
在查找内容里面输入“345$”
这里“$”表示从行尾匹配
如果从行首匹配,可以用“^”来实现,不过 EditPlus 有另一个功能可以很简单的删除行首的字符串
a. 选择要操作的行
b. 编辑-格式-删除行注释
c. 在弹出对话框里面输入要清除的行首字符,确定
【4】正则表达式应用——替换带有半角括号的多行
几百个网页中都有下面一段代码:
\n
在替换对话框启用“正则表达式”选项,这时就可以完成替换了
【5】正则表达式应用——删除空行
启动EditPlus,打开待处理的文本类型文件。
①、选择“查找”菜单的“替换”命令,弹出文本替换对话框。选中“正则表达式”复选框,表明我们要在查找、替换中使用正则表达式。然后,选中“替换范围”中的“当前文件”,表明对当前文件操作。
②、单击“查找内容”组合框右侧的按钮,出现下拉菜单。
③、下面的操作添加正则表达式,该表达式代表待查找的空行。(技巧提示:空行仅包括空格符、制表符、回车符,且必须以这三个符号之一作为一行的开头,并且以回车符结尾,查找空行的关键是构造代表空行的正则表达式)。
直接在”查找”中输入正则表达式“^[ \t]*\n”,注意\t前有空格符。
(1)选择“从行首开始匹配”,“查找内容”组合框中出现字符“^”,表示待查找字符串必须出现在文本中一行的行首。
(2)选择“字符在范围中”,那么在“^”后会增加一对括号“[]”,当前插入点在括号中。括号在正则表达式中表示,文本中的字符匹配括号中任意一个字符即符合查找条件。
(3)按一下空格键,添加空格符。空格符是空行的一个组成成分。
(4)选择“制表符”,添加代表制表符的“\t”。
(5)移动光标,将当前插入点移到“]”之后,然后选择“匹配 0 次或更多”,该操作会添加星号字符“*”。星号表示,其前面的括号“[]”内的空格符或制表符,在一行中出现0个或多个。
(6)选择“换行符”,插入“\n”,表示回车符。
④、“替换为”组合框保持空,表示删除查找到的内容。单击“替换”按钮逐个行删除空行,或单击“全部替换”按钮删除全部空行(注意:EditPlus有时存在“全部替换”不能一次性完全删除空行的问题,可能是程序BUG,需要多按几次按钮)。
1.在汉化的时候,是否经常碰到这样的语句需要翻译:
Code:
“Error adding the post!”;
“Error adding the comment!”;
“Error adding the user!”;
如果有很多类似的文件一个一个翻译显然很累而且感觉很无聊。
其实可以这样处理,在Editplus里面用 替换 功能,在替换对话框选中“正则表达式”复选框:
查找原文件:
Code:
“Error adding ([^!|"|;]*)
替换成:
Code:
“在增加\1时发生错误
这样替换之后发生了什么?结果是:
Code:
“在增加the post时发生错误!”;
“在增加the comment时发生错误!”;
“在增加the user时发生错误!”;
ok,接下来你会怎么做?当然再替换一次把the post、the comment、the user替换成你要翻译的词。得到最后的结果:
Code:
“在增加帖子时发生错误!”;
“在增加评论时发生错误!”;
“在增加用户时发生错误!”;
2.要提取的单词在中间,比如:
Code:
can not be deleted because
can not be added because
can not be updating because
可以用这种方式:
在Editplus里面用 替换 功能,在替换对话框选中“正则表达式”复选框:
查找原文件:
Code:
can not be ([^ ]*) because
替换成:
Code:
无法被\1因为
这样替换之后发生了什么?结果是:
Code:
无法被deleted因为
无法被added因为
无法被updating因为
其余步骤如上。
在汉化量很大而且句式比较单调的情况下对效率的提高很明显!
解释一下:([^!|"|;]*) 的意思是 不等于 ! 和 ” 和 ; 中的任何一个,意思就是这3个字符之外的所有字符将被选中(替换区域);
\1 即被选中的替换区域所在的新位置(复制到这个新位置)。
3.经常手工清理一行一行地删除文本文件里面的空白行,其实可以交给Editplus更好的完成,在Editplus里面用替换功能,在替换对话框选中“正则表达式”复选框:
查找原文件:
Code:
^[ \t]*\n
替换部分为空就可以删除空白行了,执行一下看看:)
abandon[2'b9nd2n]v.抛弃,放弃
abandonment[2'b9nd2nm2nt]n.放弃
abbreviation[2bri:vi'ei62n]n.缩写
abeyance[2'bei2ns]n.缓办,中止
abide[2'baid]v.遵守
ability[2'biliti]n.能力
able['eibl]adj.有能力的,能干的
abnormal[9b'n0:m2l]adj.反常的,变态的
aboard[2'b0:d]adv.船(车)上
1.
查找: (^[a-zA-Z0-0\-]+)(\[*.*\]+)(.*)
替换: @@@@@”\1″,”\2″,”\3″,
效果:
@@@@@”abandon”,”[2'b9nd2n]“,”v.抛弃,放弃”,
@@@@@”abandonment”,”[2'b9nd2nm2nt]“,”n.放弃”,
@@@@@”abbreviation”,”[2bri:vi'ei62n]“,”n.缩写”,
@@@@@”abeyance”,”[2'bei2ns]“,”n.缓办,中止”,
@@@@@”abide”,”[2'baid]“,”v.遵守”,
@@@@@”ability”,”[2'biliti]“,”n.能力”,
@@@@@”able”,”['eibl]“,”adj.有能力的,能干的”,
@@@@@”abnormal”,”[9b'n0:m2l]“,”adj.反常的,变态的”,
@@@@@”aboard”,”[2'b0:d]“,”adv.船(车)上”,
2.
查找: \n
替换:
注: 要次替换内容为空
效果:
@@@@@”abandon”,”[2'b9nd2n]“,”v.抛弃,放弃”,@@@@@”abandonment”,”[2'b9nd2nm2nt]“,”n.放弃”,@@@@@”abbreviation”,”[2bri:vi'ei62n]“,”n.缩写”,@@@@@”abeyance”,”[2'bei2ns]“,”n.缓办,中止”,@@@@@”abide”,”[2'baid]“,”v.遵守”,@@@@@”ability”,”[2'biliti]“,”n.能力”,@@@@@”able”,”['eibl]“,”adj.有能力的,能干的”,@@@@@”abnormal”,”[9b'n0:m2l]“,”adj.反常的,变态的”,@@@@@”aboard”,”[2'b0:d]“,”adv.船(车)上”,@@@@@”abolish”,”[2'b0li6]“,”v.废除,取消”,@@@@@”abolition”,”[9b2'li62n]“,”n.废除,取消”
3.
查找: @@@@@
替换: \n
效果:
“abandon”,”[2'b9nd2n]“,”v.抛弃,放弃”,
“abandonment”,”[2'b9nd2nm2nt]“,”n.放弃”,
“abbreviation”,”[2bri:vi'ei62n]“,”n.缩写”,
“abeyance”,”[2'bei2ns]“,”n.缓办,中止”,
“abide”,”[2'baid]“,”v.遵守”,
“ability”,”[2'biliti]“,”n.能力”,
“able”,”['eibl]“,”adj.有能力的,能干的”,
“abnormal”,”[9b'n0:m2l]“,”adj.反常的,变态的”,
“aboard”,”[2'b0:d]“,”adv.船(车)上”,
“abolish”,”[2'b0li6]“,”v.废除,取消”,
4. 任务完成