交互式大数据处理模型-Google Dremel
背景
在大数据时代的背景下,数据是显得如此丰富和可爱。而理所当然的,大数据的存储和计算就是其相关业务的两大亮点了。总结业界一些处理大数据的方式,做了如下比较。此次,我主要介绍Google Dremel。值得一提的是,Drill是Dremel的开源版本,Google自己的OpenDremel也整合到了Drill中,不过Drill还在Apache孵化器里,得到阶段性的成果还需要一段时间。
Dremel是一种交互式的大数据处理模型,是Google在后Hadoop时代驱动大数据的新的三驾马车之一。Dremel得益于其列式存储结构和其并行查询的方式,能在秒级时间内内处理PB级的数据量。参考: http://www.csdn.net/article/2012-08-21/2808870-Google-Hadoop-versus-Dremel
论文: http://research.google.com/pubs/pub36632.html
数据模型
Dremel使用的数据模型是一种基于列的嵌套式数据模型。目前,业界大数据的结构化存储描述基本上都是嵌套式的,比如json、xml和protocol buffer等。而列式存储,也有比较多的相关理论支持。如下图所示,基于记录的存储方式,一条记录的各个列会连续地写在一起;而在列式存储方式中,记录结构会被转换成树状结构,不同记录的相同列的数据会写在一起(树结构对应于数据嵌套格式)。很显然,拆分过的列式存储方式更便于查询,尤其在查找字段较少的时候。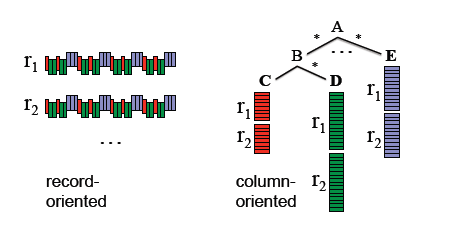
当然,好处显而易见,而问题也随之而来。怎样将记录拆分成列式存储的格式呢?又如何将列式存储的数据组装成原始的记录呢?又如何按照查询需要抽取指定字段组装原始记录而又保持原来的数据嵌套结构呢?在Dremel中,主要是结合Google Protocol Buffer来实现这些细节的。首先,我们看下Protocol Buffer的Schema和拆分之后的存储情况。
Figure: Nested data model schema and two sample records
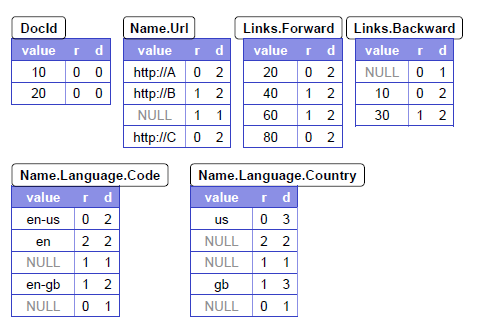
从上面可以看出,r1和r2的数据被拆分成字段存储,字段名称保持了嵌套结构。除了记录中的value以外,每个拆分后的字段还多了r和d两个量。这两个量是Google结合Protocol Buffer定义的辅助量:repetition levels & definition levels。值得注意的是,为了保证数据能够按照原有的结构重新组装成记录,在拆分存储字段时,会按照schema的定义,给没有定义的字段添加NULL值。这样做虽然浪费了一些存储空间,但却在另一方面为高效计算提供了条件,所以存储方面的浪费就不成问题了。况且,在实际应用中,Google也在存储细节上做了一些优化,具体不表。
- Repetition levels: 指定当前的value在schema中哪个级别的repeated字段里重复了(It tells us at what repeated field in the field's path the value has repeated)。
- Definition levels: 指定当前value所在的路径p上,有多少可以不定义的字段有记录了,即有多少repeated和optional字段存在(It specify how many fields in path p that could be undefined(repeated & optional) are actually present)。
举例来说。对于r值,我们选取Name.Language.Code字段:'en-us'是Code字段第一次出现在r1中,其路径Name.Language.Code上没有字段重复,则其r=0;'en'是Code字段重复出现,其路径Name.Language.Code上的Name和Language字段是repeated属性的(Code字段是required属性的,不能被算在r内),则r=2。对于d值,我们选取Name.Language.Country字段:'us'所在的路径为Name.Language.Country,而Name字段,Language字段和Country字段都是undefined类型(optional或者repeated属性)的,所以'us'对应的d=3;第一个'NULL'是r1中与Code字段'en'匹配的Country值,其路径Name.Language.Country中,Country没有出现,只有Name和Language出现,在出现的两个字段中,undefined类型的字段有2个,所以d=2。
我们可以发现,r=0是区分字段属于哪个记录的分界线;即从r=0的值起,后续的值是属于同一条记录的,直至下一个r=0的值。同一字段中的记录中,凡value不为null的值,其d的值一定是一样的。另外,一旦记录的schema定义完成,则字段的r和d的最大值就能确定下来,比如例子中的d值,只能是[0,3]。这些都是可以在实践过程中优化存储的点。
弄清楚repetition levels & definition levels后,就是记录的拆分和重组了。
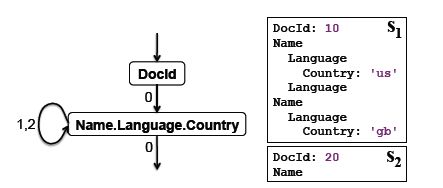
拆分记录的过程相对比较好理解。Google在论文中提到,写的过程会创建一颗由writer组成的树,树的结构和记录的schema相匹配。在写的过程中,按照特定的规则更新writer的状态。
同写的过程一样,读取的过程也有一颗由reader组成的树,树结构与记录的schema相匹配。但reader是可以在读取过程中指定的(指定哪些reader,就读哪些字段,个人这样理解)。在指定reader的时候,会生成一个包含指定reader的有限状态机(FSM),FSM会定义reader的跳转规则。Google论文中有提及,在跳转过程中,会利用到字段所定义的r值和reader自身当前的状态。
并行查询
讨论Dremel的查询,我们首先要名且其使用场景,Dremel主要用于一些数据分析的场景,只需要读取数据而不需要更新。Dremel所使用的查询语言是基于SQL的,专为列式存储做过优化的查询语言。每个SQL语句(以及一些相关的算术运算符)的输入是一组嵌套定义过的表以及这些表的schema,输出是格式相同的嵌套结构的表及其schema。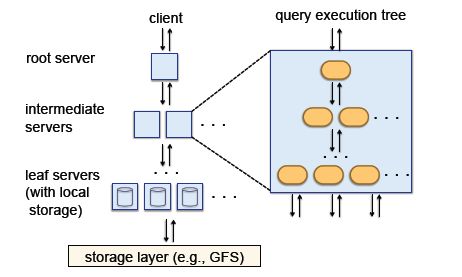
举例来说,root接收到查询
- SELECT A, COUNT(B) FROM T GROUP BY A
- SELECT A, SUM(c) FROM (R1 UNION ALL … Rn) GROUP BY A
- Ri = SELECT A, COUNT(B) AS c FROM Ti GROUP BY A
Dremel是一个多用户的系统,也就是说,通常情况下,Dremel需要同时执行多个查询请求。于是,Dremel的查询调度器应运而生。Dremel的查询调度器不仅仅是调度查询的执行,还为系统提供容错支持。当某一server的查询过于缓慢,或者某一数据块损坏时,查询调度器能及时调度其他server来顶替工作或者是重新选择需要处理的数据块备份。
除此之外,Dremel还提供一个参数设定,指定返回结果时所须扫描的数据比例。在某些场景下,我们的数据分析并不一定要求扫描全数据,在一个比较好的数学模型下,扫描部分数据所得结果也能反应真实情况。比如说,将这比例设置为80%的执行时间会比设定为100%时执行得快很多~~~实验数据
在Google的论文中,还提到了很多Google对于Dremel的测试情况,个人觉得还是有比较大的参考价值的。有时间再整理吧。暂时不表。参考
EMC的颜开童鞋和百度的某小哥对此也有分享,可以参考
http://www.yankay.com/google-dremel-rationale/
http://www.changshuai.org/2012/09/google%E4%B9%8B%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%88%A9%E5%99%A8%EF%BC%9Adremel/