Boost和AdaBoost算法原理简介
本文主要参考:
1):《AdaBoost分类算法》http://wenku.baidu.com/link?url=udZ32_5hjlVNuqOAhuCEDPpHcQTEwEAxBiPkkPmPSMKqVLEslUXtpWLnX8gfgvfiZirOkJnqSQm1JnTUTM8WaPCaTMA_x6b_-xQEuWl_hcy
2): Adaboost 算法及原理
http://wenku.baidu.com/link?url=JU_2YZXEvCj5Sxv3i5Os8WHCo9rDfKxIZhZOKR9LnHo1aO4Sd0JiMTLClvGqsY172bptf6vfnDRd8BPKcZ3te3c8AYfROKGQQ4HF78zIhju
1.名词解释
Boost(推进),adaboost(adapt boost)自适应推进算法:Adaboost算法是机器学习中一种比较重要的特征分类算法,已被广泛应用人脸表情识别、图像检索等应用中。就目前而言,对Adaboost算法的研究以及应用大多集中于分类问题,在一些回归问题上也有所应用。Adaboost主要解决的问题有: 两类问题、多类单标签问题、多类多标签问题、回归问题。
2.算法发展简介
2.1 强学习算法和弱学习算法
在机器学习领域,Boosting算法是一种通用的学习算法,这一算法可以提升任意给定的学习算法的性能。其思想源于1984年Valiant提出的”可能近似正确”-PAC(Probably Approximately Correct)学习模型,在PAC模型中定义了两个概念-强学习算法和弱学习算法。其概念是: 如果一个学习算法通过学习一组样本,识别率很高,则称其为强学习算法;如果识别率仅比随机猜测略高,其猜测准确率大于50,则称其为弱学习算法。
2.2boost模型发展
1989年Kearns and Valiant研究了PAC学习模型中弱学习算法和强学习算法两者间的等价问题;
即任意给定仅仅比随机猜测稍好(准确率大于0.5)的弱学习算法,是否可以被提升为强学习算法?若两者等价,则我们只需寻找一个比随机猜测稍好的若学习算法,然后将其提升为强学习算法,从而不必费很大力气去直接寻找强学习算法。
就此问题,Schapire于1990年首次给出了肯定的答案。他主持这样一个观点:
任一弱学习算法可以通过加强提升到一个任意正确率的强学习算法,并通过构造一种多项式级的算法来实现这一加强过程,这就是最初的Boosting算法的原型。
Boosting是一种将弱分类器通过某种方式结合起来得到一个分类性能大大提高的强分类器的分类方法。该方法可以把一些粗略的经验规则转变为高度准确的预测法则。强分类器对数据进行分类,是通过弱分类器的多数投票机制进行的。该算法是一个简单的弱分类算法提升过程,这个过程通过不断的训练,以提高对数据的分类能力。
Freund于1991年提出了另外一种效率更高的Boosting算法。但此算法需要要提前知道弱学习算法正确率的下限,因而应用范围十分有限。
2.3adaboost出现
1995年,Freund and Schapire改进了Boosting算法,取名为Adaboost算法,该算法不需要提前知道所有关于弱学习算法的先验知识,同时运算效率与Freund在1991年提出的Boosting算法几乎相同。Adaboost即Adaptive Boosting,它能
1):自适应的调整弱学习算法的错误率,经过若干次迭代后错误率能达到预期的效果。
2):它不需要精确知道样本空间分布,在每次弱学习后调整样本空间分布,更新所有训练样本的权重,把样本空间中被正确分类的样本权重降低,被错误分类的样本权重将会提高,这样下次弱学习时就更能更关注这些被错误分类的样本。该算法可以很容易地应用到实际问题中,因此,已成为目前最流行的Boosting算法。
AdaBoost算法的核心思想是针对同一个训练集训练出不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个性能更加强大的分类器(强分类器)。
2.4 Boosting与AdaBoost算法的训练
Boosting分类方法,其过程如下所示:
1)先通过对N个训练数据的学习得到第一个弱分类器h1;
2)将h1分错的数据和其他的新数据一起构成一个新的有N个训练数据的样本,通过对这个样本的学习得到第二个弱分类器h2;
3)将h1和h2都分错了的数据加上其他的新数据构成另一个新的有N个训练数据的样本,通过对这个样本的学习得到第三个弱分类器h3;
4)最终经过提升的强分类器h_final=Majority Vote(h1,h2,h3)。即某个数据被分为哪一类要通过h1,h2,h3的多数表决。
上述Boosting算法,存在两个问题:
①如何调整训练集,使得在训练集上训练弱分类器得以进行。
②如何将训练得到的各个弱分类器联合起来形成强分类器。
针对以上两个问题,AdaBoost算法进行了调整:
①使用加权后选取的训练数据代替随机选取的训练数据,这样将训练的焦点集中在比较难分的训练数据上。
②将弱分类器联合起来时,使用加权的投票机制代替平均投票机制。让分类效果好的弱分类器具有较大的权重,而分类效果差的分类器具有较小的权重。
AdaBoost算法的具体描述如下:
假定X表示样本空间,Y表示样本类别标识集合,假设是二值分类问题,这里限定Y={-1,+1}。令S={(Xi,yi)|i=1,2,…,m}为样本训练集,其中Xi∈X,yi∈Y。
①:始化m个样本的权值,假设样本分布Dt为均匀分布:Dt(i)=1/m,Dt(i)表示在第t轮迭代中赋给样本(xi,yi)的权值。
②:令T表示迭代的次数。
 )
)
下面copy自:浅谈 Adaboost 算法
四 Adaboost 举例
也许你看了上面的介绍或许还是对adaboost算法云里雾里的,没关系,百度大牛举了一个很简单的例子,你看了就会对这个算法整体上很清晰了。
下面我们举一个简单的例子来看看adaboost的实现过程:

图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1
其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
也许你对上面的ɛ1,ɑ1怎么算的也不是很理解。下面我们算一下,不要嫌我啰嗦,我最开始就是这样思考的,只有自己把算法演算一遍,你才会真正的懂这个算法的核心,后面我会再次提到这个。
算法最开始给了一个均匀分布 D 。所以h1 里的每个点的值是0.1。ok,当划分后,有三个点划分错了,根据算法误差表达式![]() 得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式
得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式 的可以算出来为0.42. 然后就根据算法 把分错的点权值变大。如此迭代,最终完成adaboost算法。
第二步:

根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:

得到一个子分类器h3
整合所有子分类器:

因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。
五 Adaboost 疑惑和思考
到这里,也许你已经对adaboost算法有了大致的理解。但是也许你会有个问题,为什么每次迭代都要把分错的点的权值变大呢?这样有什么好处呢?不这样不行吗? 这就是我当时的想法,为什么呢?我看了好几篇介绍adaboost 的博客,都没有解答我的疑惑,也许大牛认为太简单了,不值一提,或者他们并没有意识到这个问题而一笔带过了。然后我仔细一想,也许提高错误点可以让后面的分类器权值更高。然后看了adaboost算法,和我最初的想法很接近,但不全是。 注意到算法最后的表到式为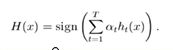 ,这里面的a 表示的权值,是由
,这里面的a 表示的权值,是由![]() 得到的。而a是关于误差的表达式,到这里就可以得到比较清晰的答案了,所有的一切都指向了误差。提高错误点的权值,当下一次分类器再次分错了这些点之后,会提高整体的错误率,这样就导致 a 变的很小,最终导致这个分类器在整个混合分类器的权值变低。也就是说,这个算法让优秀的分类器占整体的权值更高,而挫的分类器权值更低。这个就很符合常理了。到此,我认为对adaboost已经有了一个透彻的理解了。
得到的。而a是关于误差的表达式,到这里就可以得到比较清晰的答案了,所有的一切都指向了误差。提高错误点的权值,当下一次分类器再次分错了这些点之后,会提高整体的错误率,这样就导致 a 变的很小,最终导致这个分类器在整个混合分类器的权值变低。也就是说,这个算法让优秀的分类器占整体的权值更高,而挫的分类器权值更低。这个就很符合常理了。到此,我认为对adaboost已经有了一个透彻的理解了。
六 总结
最后,我们可以总结下adaboost算法的一些实际可以使用的场景:
1)用于二分类或多分类的应用场景
2)用于做分类任务的baseline
无脑化,简单,不会overfitting,不用调分类器
3)用于特征选择(feature selection)
4)Boosting框架用于对badcase的修正
只需要增加新的分类器,不需要变动原有分类器
由于adaboost算法是一种实现简单,应用也很简单的算法。Adaboost算法通过组合弱分类器而得到强分类器,同时具有分类错误率上界随着训练增加而稳定下降,不会过拟合等的性质,应该说是一种很适合于在各种分类场景下应用的算法。