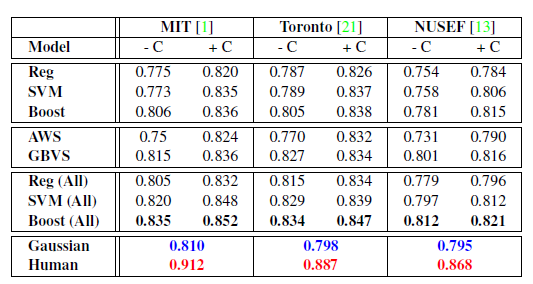
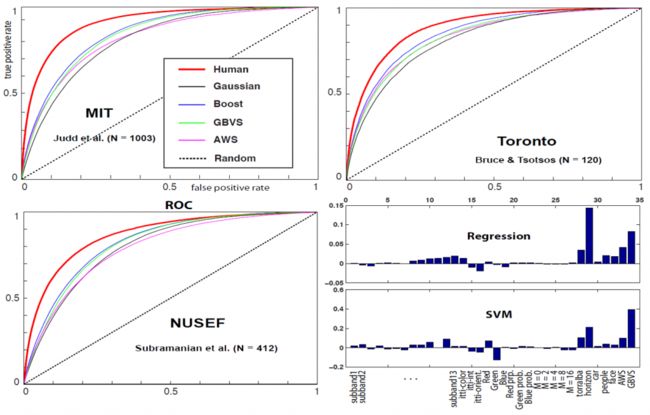
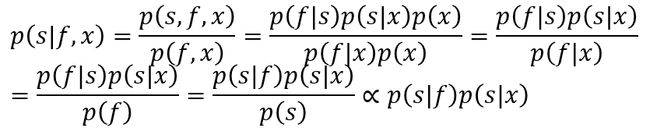- 以研发创新为驱动力,黄山谷捷助力新能源汽车产业高质量发展
L913197600
黄山谷捷制造科技
在新能源汽车产业蓬勃发展的浪潮中,车规级功率半导体作为驱动电机控制系统的核心部件,其性能与稳定性直接关系到汽车的动力输出、能效转化及安全性能。在这一关键领域,黄山谷捷股份有限公司(以下简称“黄山谷捷”或“公司”)以卓越的研发实力、精湛的生产工艺和严格的质量控制体系,成为行业内的佼佼者,特别是在功率半导体散热基板领域,更是树立了新的标杆。自2012年成立以来,黄山谷捷便深谙“科技是第一生产力”的真谛
- 探索创新科技: Lite-Mono - 简约高效的小型化Mono框架
杭律沛Meris
探索创新科技:Lite-Mono-简约高效的小型化Mono框架Lite-Mono[CVPR2023]Lite-Mono:ALightweightCNNandTransformerArchitectureforSelf-SupervisedMonocularDepthEstimation项目地址:https://gitcode.com/gh_mirrors/li/Lite-Mono如果你在寻找一个轻
- IGBT模块直流参数测试系统STD6500
tianshili029
晶体管参数测试系统半导体特性曲线图示仪
陕西天士立科技有限公司IGBT模块直流参数测试系统STD6500IGBT模块直流参数测试系统ST-DC6500基础信息开发背景:大功率IGBT和Diode模块j静态参数程控式设备技术标准:IEC60747-2/GB/T4023-1997半导体器件分立器件和集成电路第2部分(整流二极管)技术标准:IEC60747-9∶2007/GB/T29332-2012半导体器件分立器件第9部分(绝缘栅双极晶体管
- 中国为什么没有发展出具有影响力的宗教?
llSteven
关于这个话题,我就想笼统地随便聊聊,文章里的内容会稍显片面,有兴趣地小伙伴我们私底下聊,我就随便扯扯,说说有意思的。Reference我就不写了,麻烦!在中国,宗教在我们的历史进程中没有很大的影响。中国的传统宗教有两个,佛教和道教,但信仰者的比例很低。到了现在,可以说中国不是一个有宗教信仰的国家。或者我猜测,大多数人会说信仰科学。对比西方,相信大家都知道就不用多说了。说个有意思的,2012年的时候
- go语言安装快速入门
吉祥鸟hu
[TOC]go语言是什么Go是一个开源的编程语言,它能让构造简单、可靠且高效的软件变得容易。Go是从2007年末由RobertGriesemer,RobPike,KenThompson主持开发,后来还加入了IanLanceTaylor,RussCox等人,并最终于2009年11月开源,在2012年早些时候发布了Go1稳定版本。现在Go的开发已经是完全开放的,并且拥有一个活跃的社区如何安装环境笔者这
- “杜苏芮”是谁?“杜苏芮”到底有多可怕?
峡谷风6248
这两天,“杜苏芮”成为最热的词,那“杜苏芮”是谁?是明星吗?是唱歌的还是跳舞的还是演员、作家?“杜苏芮”到底有多可怕?“杜苏芮”感觉像人名,还和明星阿杜和苏芮的名字意外相似,但它与阿杜和苏芮没有半毛钱的关系。那“杜苏芮”到底是谁呢?“杜苏芮”是2012年太平洋台风季第六个被命名的风暴,其名字“杜苏芮”一名由韩国提供,意为秃鹫,猛禽,狼鹰的一种。网图侵删这个台风为什么叫“杜苏芮”?原来台风的命名是论
- 骑文探古访百村(5):里水镇孔西村
钮海津
祝孔后再辉煌口钮海津2012年12月21的报网消息云,“广东省民间遗产抢救工程这股暖风昨天吹到了孔西村,让这个历史悠久、民风淳朴的村落洋溢着冬日的暖意”。孔西村古建筑群,听说过,在佛山市南海区里水镇。找个时间去看看。看看还有没有这句“子曰”:君子谋道不谋食。耕也,馁在其中矣;学也,禄在其中矣。君子忧道不忧贫。翻译过来就是,老孔对地位高的人说:君子用心谋求大道而不费心思去谋求衣食。即使你亲自去耕田种
- “激情欠条”在司法实务中如何认定
57b86cbb560c
裁判要旨当事人之间仅有欠条的借贷关系,因不能充分提供其他条件或证据,法院应当对形成欠条的主客观条件进行综合考量,最终作出公正的判决。案情原告杨韦华与被告乔二广自初中时相识,自高中起建立恋爱关系,随后两人同居,对二人关系,原告父母并不赞同。原告杨韦华诉称:被告以做生意为名,向原告陆续借款50万元。2012年8月8日,被告向原告出示欠条,经多次追要无果,故诉至法院请求判令被告给付欠款50万元。为支持自
- TypeScript 快速入门
echozzi
1024程序员节
一、TypeScript是什么TypeScript是一种由微软开发的自由和开源的编程语言。于2012年推出。TypeScript是JavaScript的一个超集。为JavaScript添加了类型系统。TypeScript与JavaScript的区别TypeScriptJavaScriptJavaScript的超集用于解决大型项目的代码复杂性一种脚本语言,用于创建动态网页可以在编译期间发现并纠正错误
- 「经济学人」Streaming-video wars
英语学习社
GameofphonesHBOwillleadAT&T’schallengetoNetflixTimeWarner’scrownjewelmustscaleupwhilemaintainingqualityINLATE2012,justbeforethereleaseof“HouseofCards”,TedSarandos,chiefcontentofficerofNetflix,declared
- 大三时MySQL课程设计《MySQL集群的研究与实现》
weixin_30908941
数据库嵌入式php
河南中医学院《MySQL数据库管理》课程设计报告题目:MySQL集群的研究与实现完成日期:2012年12月31日目录1.课程设计题目概述.32.研究内容与目的.33.研究方法.43.1研究方法………………………………………………………………………..43.2实验方法…………………………………………………………………………53.3可行性分析..…………………………………………………………………………
- 秋色
可以轩主人
----2012年11月21日一语奇花花千色,两分秋水水清清。棋罢观花花不语,凝眸清水水盈盈。千色奇花秋零落,清清秋水冬作冰。人生世事如棋落,纵无风雨也无晴。图片发自App
- 7款Java 微服务框架
剑海风云
J2EEMiddleware#SpringBootjava微服务SpringbootQuarkusMicronautHelidonChronicle
1.微服务的历史微服务的概念源于21世纪初盛行的面向服务架构(SOA)。然而,“微服务”一词本身直到2012年左右才出现,当时它开始在软件架构活动和软件架构博客上被讨论。微服务的早期先驱包括Netflix、Amazon和eBay等公司。例如,2009年,Netflix开始从单体架构过渡到微服务架构,以更好地处理快速扩展的客户群。其他大公司也纷纷效仿,意识到单体架构模型在处理大规模复杂系统时存在局限
- 女儿的高考倒计时-113天
fyl_Lanny
重温那段难以忘怀的旧时光……2012、2、14周二多云今天下午,华把浙大和武大的报名材料都邮寄走了,梦的艺术特长生报考这件事总算全部结束了,接下来的就是等待各高校公布艺术特长生的签约消息了。明天是十五号,是大连理工大学公布艺术特长专业测试等级的日子,不知道梦会是A级还是B级?中午,我把大连理工大学在艺术特长生专业测试时发给考生的空白协议拿出来研究了一下,如果艺术特长专业测试等级为A级,考生得到的是
- 梯度提升机 (Gradient Boosting Machines, GBM)
ALGORITHM LOL
boosting集成学习机器学习
梯度提升机(GradientBoostingMachines,GBM)通俗易懂算法梯度提升机(GradientBoostingMachines,GBM)是一种集成学习算法,主要用于回归和分类问题。GBM本质上是通过训练一系列简单的模型(通常是决策树),然后将这些模型组合起来,从而提高整体预测性能。基本步骤初始模型:首先,我们用一个简单的模型(如一个常数值)作为预测模型,记为F0(x)F_0(x)F
- 小麦子的ScalersTalk第四轮新概念朗读持续力训练Day66 20121212
小麦_3982
练习材料:Lesson66Sweetashoney!In1963aLancasterbombercrashedonWallisIsland,aremoteplaceintheSouthPacific,alongwaywestofSamoa.Theplanewasn'ttoobadlydamaged,butovertheyears,thecrashwasforgottenandthewreckrem
- 每日一题 第三期 洛谷 国王游戏
娇娇yyyyyy
每日一题算法c++
[NOIP2012提高组]国王游戏题目描述恰逢H国国庆,国王邀请nnn位大臣来玩一个有奖游戏。首先,他让每个大臣在左、右手上面分别写下一个整数,国王自己也在左、右手上各写一个整数。然后,让这nnn位大臣排成一排,国王站在队伍的最前面。排好队后,所有的大臣都会获得国王奖赏的若干金币,每位大臣获得的金币数分别是:排在该大臣前面的所有人的左手上的数的乘积除以他自己右手上的数,然后向下取整得到的结果。国王
- 那些年路过的幸福(长篇小说)(第一百六十六章)
古不为
第一百六十六章你停一停再玩吧,没有煤球了2012年7月16日周一。晴云。午后一点的时候,阿女打回电话,她正坐在郑州开往神州的客车上,再有二十分钟就会到神州车站,让去接。江山两个外甥女阿宝、阿音也要跟着去接姐姐,就带上她们一起去。再坐到电脑跟前的时候,已是下午两点整了。账户A做了一把,相当成功。但是,由于看博客晚开仓10多个点,少赚1万元。定然也是命运安排,随他去吧!2012年7月17日周二。晴云。
- 十大机器学习算法-梯度提升决策树(GBDT)
zjwreal
机器学习GBDT机器学习梯度提升提升树梯度提升决策树
简介梯度提升决策树(GBDT)由于准确率高、训练快速等优点,被广泛应用到分类、回归合排序问题中。该算法是一种additive树模型,每棵树学习之前additive树模型的残差。许多研究者相继提出XGBoost、LightGBM等,又进一步提升了GBDT的性能。基本思想提升树-BoostingTree以决策树为基函数的提升方法称为提升树,其决策树可以是分类树或者回归树。决策树模型可以表示为决策树的加
- 痛快!女儿被“性侵”,母亲开挂报复!
新电影院
根前几天5G小妹给大家推了《摔跤吧!爸爸》,相信大家都在5ggg.net上面免费看了吧,那今天就来讲一个关于母亲的故事!2012年,印度发生了一起震惊世界的公交车轮奸案。印度大学生乔蒂晚上和男朋友看完电影,搭乘一辆公交回家。孰料在车上被6个男子殴打、轮奸。更残忍的是,他们还将铁棍捅进女孩的下体肠子都被拽出......犯案之后将一对男女抛出公交车13天后,乔蒂因抢救无效死亡而这仅仅是印度众多强奸案中
- 女儿像我——亲子检视第129天
小㼆的笔记
亲子打卡20201229打卡累计天数129天宣言#只有感觉好,才能做得好#姐姐闪光点⭐️准备元旦联欢晚会PPT和主持稿⭐️数学作业不会,自己对照作业帮弟弟闪光点⭐️复查眼睛很配合⭐️玩故宫立体图、玩停车、玩高射炮特别开心记录我在支持孩子方面的努力⛽️耐心待妞、陪儿⛽️与妞沟通疫情严峻,需要做好防护的问题计划我今天要做什么做PPT打印作业单,记录闪光点并将信息传递给女儿【反思】刚刚参加PPT组会,我
- 青岛鑫江东方城购物中心远程预付费电能管理系统的应用
weixin--ac508982
1.项目概况青岛鑫江东方城购物中心,位于青岛市黑龙江中路城阳段,西临黑龙江中路,东靠青银高速。项目总占面积17万平米,于2012年7月7日正式开业,共有2200余个停车位。广场分为地下一层和地上五层,共约600个大小商户,其中主力店包括华润超市、苏宁电器、迪卡侬、星烨国际影城、缤纷东方冰场、迪畅KTV、东方美食城、海洋贝贝儿童乐园、城市英雄电玩城等。约有三分之二采用插卡预付费电表,商户充值电费时均
- 220124周复盘
福州张三疯
第66天日更,截止90天目标第69天完成情况如下:1、11点前睡(32/90)11点10分睡觉2、KEEP或跑步(59/90)1下俯卧撑3、每天一P(14/90)完成14张PPT一、八大关注进行周检视1、健康本周平均入睡22:10分,平均早起7点02分俯卧撑6天2、事业本周工作重心主要可以分为两大块找IT工作:找it会议两场,创商中心做了第一次的培训捷源工作:1、未收款跟进2、音响单子两块3、效能
- C#中两个问号的含义
weixin_30363981
测试
stringstrParam=Request.Params["param"]??"";取??左边的值,如果??左边的值为null则取右边的值转载于:https://www.cnblogs.com/shadowtale/archive/2012/10/19/2731152.html
- 金马营:身高不足1米7,他却用电影改变国家
金马营
“一个演员,能改变一个国家吗?”这是2012年《时代》杂志对印度演员阿米尔·汗的评论。阿米尔·汗用他的一部部电影将这个问号化为大写的句号、感叹号。去年《摔跤吧,爸爸》票房12.9亿,豆瓣评分9.1,口碑、票房双丰收。这一次,米叔的新电影《神秘巨星》上映。依然直指印度最尖锐的社会问题,没有尬舞,每一个转折起落都扣人心弦,笑点和泪点兼备,非常阿米尔·汗的风格。15岁的尹西娅考试马马虎虎,却有唱歌的天赋
- 2019-5-26晨间日记
516aeeeed40c
今天是什么日子起床:6.30就寝:10.30天气:阴心情:烦燥纪念日:2012.任务清单昨日完成的任务,最重要的三件事:出门走走,买想吃的东西,想见到你改进:脾气改不了习惯养成:喝水,跑步周目标·完成进度每天坚持练功学习·信息·阅读看电影写观后感健康·饮食·锻炼坚持减肥人际·家人·朋友同事关系还好家人关系欠佳工作·思考三个月后是走是留最美好的三件事1.有了很爱很爱的他2.躺在床上3.玩着手机思考·
- 鞠婧祎:曾遭遇数月之久的群嘲,今新剧《嘉南传》大受好评
慕容小微
2012年,18岁的鞠婧祎参加了女生派成都地区的竞选,并在比赛中被评选为人气美女。次年,鞠婧祎听说丝芭在选拔女团成员,她也兴冲冲地报了名。但是当她看到会议厅里坐着很多穿着粉色系小裙子,说话都是娇嗲地吐出软糯之音的女选手之后,她打了退堂鼓:我完蛋了,我还是走吧。于是鞠婧祎就象走过场似地说完自我介绍后就走了。没承想,正跟朋友吃着饭呢,一通电话进来了:你的初审过了,你需要回来一下。就这样,鞠婧祎成为了女
- AMD GCN GPU微架构简介
jack_201316888
硬件架构微架构
AMDGCN(GraphicsCoreNext)微架构介绍AMDGCN(GraphicsCoreNext)是AMD公司推出的一种用于图形处理单元(GPU)的微架构。自2012年首次推出以来,GCN架构已成为AMD图形处理器的核心技术之一,广泛应用于桌面显卡、笔记本电脑以及游戏主机(如PlayStation和Xbox)等设备中。本文将详细介绍GCN微架构的设计理念、主要特性及其演变历程。设计理念GC
- 间隔年 の 2012 | 东南亚 (一)南宁
looynne
引我不是易安于现状之人。这些年走过的地方,从未认真记录,实在是羞于分享年少轻狂之认知。然几近不惑,回顾每一段历程,怕再不提笔,终将忘却。“Welovetheplacewehate,thenhatetheplacewelove;Weleavetheplacewelove,thenspendalifetimetryingtoregainit."曾对生我养我之地又爱又恨,时刻想要逃离。走过千山万水顿悟,
- 《机器学习》—— XGBoost(xgb.XGBClassifier) 分类器
张小生180
机器学习人工智能
文章目录一、XGBoost分类器的介绍二、XGBoost(xgb.XGBClassifier)分类器与随机森林分类器(RandomForestClassifier)的区别三、XGBoost(xgb.XGBClassifier)分类器代码使用示例一、XGBoost分类器的介绍XGBoost分类器是一种基于梯度提升决策树(GradientBoostingDecisionTree,GBDT)的集成学习算
- TOMCAT在POST方法提交参数丢失问题
357029540
javatomcatjsp
摘自http://my.oschina.net/luckyi/blog/213209
昨天在解决一个BUG时发现一个奇怪的问题,一个AJAX提交数据在之前都是木有问题的,突然提交出错影响其他处理流程。
检查时发现页面处理数据较多,起初以为是提交顺序不正确修改后发现不是由此问题引起。于是删除掉一部分数据进行提交,较少数据能够提交成功。
恢复较多数据后跟踪提交FORM DATA ,发现数
- 在MyEclipse中增加JSP模板 删除-2008-08-18
ljy325
jspxmlMyEclipse
在D:\Program Files\MyEclipse 6.0\myeclipse\eclipse\plugins\com.genuitec.eclipse.wizards_6.0.1.zmyeclipse601200710\templates\jsp 目录下找到Jsp.vtl,复制一份,重命名为jsp2.vtl,然后把里面的内容修改为自己想要的格式,保存。
然后在 D:\Progr
- JavaScript常用验证脚本总结
eksliang
JavaScriptjavaScript表单验证
转载请出自出处:http://eksliang.iteye.com/blog/2098985
下面这些验证脚本,是我在这几年开发中的总结,今天把他放出来,也算是一种分享吧,现在在我的项目中也在用!包括日期验证、比较,非空验证、身份证验证、数值验证、Email验证、电话验证等等...!
&nb
- 微软BI(4)
18289753290
微软BI SSIS
1)
Q:查看ssis里面某个控件输出的结果:
A MessageBox.Show(Dts.Variables["v_lastTimestamp"].Value.ToString());
这是我们在包里面定义的变量
2):在关联目的端表的时候如果是一对多的关系,一定要选择唯一的那个键作为关联字段。
3)
Q:ssis里面如果将多个数据源的数据插入目的端一
- 定时对大数据量的表进行分表对数据备份
酷的飞上天空
大数据量
工作中遇到数据库中一个表的数据量比较大,属于日志表。正常情况下是不会有查询操作的,但如果不进行分表数据太多,执行一条简单sql语句要等好几分钟。。
分表工具:linux的shell + mysql自身提供的管理命令
原理:使用一个和原表数据结构一样的表,替换原表。
linux shell内容如下:
=======================开始
- 本质的描述与因材施教
永夜-极光
感想随笔
不管碰到什么事,我都下意识的想去探索本质,找寻一个最形象的描述方式。
我坚信,世界上对一件事物的描述和解释,肯定有一种最形象,最贴近本质,最容易让人理解
&
- 很迷茫。。。
随便小屋
随笔
小弟我今年研一,也是从事的咱们现在最流行的专业(计算机)。本科三流学校,为了能有个更好的跳板,进入了考研大军,非常有幸能进入研究生的行业(具体学校就不说了,怕把学校的名誉给损了)。
先说一下自身的条件,本科专业软件工程。主要学习就是软件开发,几乎和计算机没有什么区别。因为学校本身三流,也就是让老师带着学生学点东西,然后让学生毕业就行了。对专业性的东西了解的非常浅。就那学的语言来说
- 23种设计模式的意图和适用范围
aijuans
设计模式
Factory Method 意图 定义一个用于创建对象的接口,让子类决定实例化哪一个类。Factory Method 使一个类的实例化延迟到其子类。 适用性 当一个类不知道它所必须创建的对象的类的时候。 当一个类希望由它的子类来指定它所创建的对象的时候。 当类将创建对象的职责委托给多个帮助子类中的某一个,并且你希望将哪一个帮助子类是代理者这一信息局部化的时候。
Abstr
- Java中的synchronized和volatile
aoyouzi
javavolatilesynchronized
说到Java的线程同步问题肯定要说到两个关键字synchronized和volatile。说到这两个关键字,又要说道JVM的内存模型。JVM里内存分为main memory和working memory。 Main memory是所有线程共享的,working memory则是线程的工作内存,它保存有部分main memory变量的拷贝,对这些变量的更新直接发生在working memo
- js数组的操作和this关键字
百合不是茶
js数组操作this关键字
js数组的操作;
一:数组的创建:
1、数组的创建
var array = new Array(); //创建一个数组
var array = new Array([size]); //创建一个数组并指定长度,注意不是上限,是长度
var arrayObj = new Array([element0[, element1[, ...[, elementN]]]
- 别人的阿里面试感悟
bijian1013
面试分享工作感悟阿里面试
原文如下:http://greemranqq.iteye.com/blog/2007170
一直做企业系统,虽然也自己一直学习技术,但是感觉还是有所欠缺,准备花几个月的时间,把互联网的东西,以及一些基础更加的深入透析,结果这次比较意外,有点突然,下面分享一下感受吧!
&nb
- 淘宝的测试框架Itest
Bill_chen
springmaven框架单元测试JUnit
Itest测试框架是TaoBao测试部门开发的一套单元测试框架,以Junit4为核心,
集合DbUnit、Unitils等主流测试框架,应该算是比较好用的了。
近期项目中用了下,有关itest的具体使用如下:
1.在Maven中引入itest框架:
<dependency>
<groupId>com.taobao.test</groupId&g
- 【Java多线程二】多路条件解决生产者消费者问题
bit1129
java多线程
package com.tom;
import java.util.LinkedList;
import java.util.Queue;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.loc
- 汉字转拼音pinyin4j
白糖_
pinyin4j
以前在项目中遇到汉字转拼音的情况,于是在网上找到了pinyin4j这个工具包,非常有用,别的不说了,直接下代码:
import java.util.HashSet;
import java.util.Set;
import net.sourceforge.pinyin4j.PinyinHelper;
import net.sourceforge.pinyin
- org.hibernate.TransactionException: JDBC begin failed解决方案
bozch
ssh数据库异常DBCP
org.hibernate.TransactionException: JDBC begin failed: at org.hibernate.transaction.JDBCTransaction.begin(JDBCTransaction.java:68) at org.hibernate.impl.SessionImp
- java-并查集(Disjoint-set)-将多个集合合并成没有交集的集合
bylijinnan
java
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.ut
- Java PrintWriter打印乱码
chenbowen00
java
一个小程序读写文件,发现PrintWriter输出后文件存在乱码,解决办法主要统一输入输出流编码格式。
读文件:
BufferedReader
从字符输入流中读取文本,缓冲各个字符,从而提供字符、数组和行的高效读取。
可以指定缓冲区的大小,或者可使用默认的大小。大多数情况下,默认值就足够大了。
通常,Reader 所作的每个读取请求都会导致对基础字符或字节流进行相应的读取请求。因
- [天气与气候]极端气候环境
comsci
环境
如果空间环境出现异变...外星文明并未出现,而只是用某种气象武器对地球的气候系统进行攻击,并挑唆地球国家间的战争,经过一段时间的准备...最大限度的削弱地球文明的整体力量,然后再进行入侵......
那么地球上的国家应该做什么样的防备工作呢?
&n
- oracle order by与union一起使用的用法
daizj
UNIONoracleorder by
当使用union操作时,排序语句必须放在最后面才正确,如下:
只能在union的最后一个子查询中使用order by,而这个order by是针对整个unioning后的结果集的。So:
如果unoin的几个子查询列名不同,如
Sql代码
select supplier_id, supplier_name
from suppliers
UNI
- zeus持久层读写分离单元测试
deng520159
单元测试
本文是zeus读写分离单元测试,距离分库分表,只有一步了.上代码:
1.ZeusMasterSlaveTest.java
package com.dengliang.zeus.webdemo.test;
import java.util.ArrayList;
import java.util.List;
import org.junit.Assert;
import org.j
- Yii 截取字符串(UTF-8) 使用组件
dcj3sjt126com
yii
1.将Helper.php放进protected\components文件夹下。
2.调用方法:
Helper::truncate_utf8_string($content,20,false); //不显示省略号 Helper::truncate_utf8_string($content,20); //显示省略号
&n
- 安装memcache及php扩展
dcj3sjt126com
PHP
安装memcache tar zxvf memcache-2.2.5.tgz cd memcache-2.2.5/ /usr/local/php/bin/phpize (?) ./configure --with-php-confi
- JsonObject 处理日期
feifeilinlin521
javajsonJsonOjbectJsonArrayJSONException
写这边文章的初衷就是遇到了json在转换日期格式出现了异常 net.sf.json.JSONException: java.lang.reflect.InvocationTargetException 原因是当你用Map接收数据库返回了java.sql.Date 日期的数据进行json转换出的问题话不多说 直接上代码
&n
- Ehcache(06)——监听器
234390216
监听器listenerehcache
监听器
Ehcache中监听器有两种,监听CacheManager的CacheManagerEventListener和监听Cache的CacheEventListener。在Ehcache中,Listener是通过对应的监听器工厂来生产和发生作用的。下面我们将来介绍一下这两种类型的监听器。
- activiti 自带设计器中chrome 34版本不能打开bug的解决
jackyrong
Activiti
在acitivti modeler中,如果是chrome 34,则不能打开该设计器,其他浏览器可以,
经证实为bug,参考
http://forums.activiti.org/content/activiti-modeler-doesnt-work-chrome-v34
修改为,找到
oryx.debug.js
在最头部增加
if (!Document.
- 微信收货地址共享接口-终极解决
laotu5i0
微信开发
最近要接入微信的收货地址共享接口,总是不成功,折腾了好几天,实在没办法网上搜到的帖子也是骂声一片。我把我碰到并解决问题的过程分享出来,希望能给微信的接口文档起到一个辅助作用,让后面进来的开发者能快速的接入,而不需要像我们一样苦逼的浪费好几天,甚至一周的青春。各种羞辱、谩骂的话就不说了,本人还算文明。
如果你能搜到本贴,说明你已经碰到了各种 ed
- 关于人才
netkiller.github.com
工作面试招聘netkiller人才
关于人才
每个月我都会接到许多猎头的电话,有些猎头比较专业,但绝大多数在我看来与猎头二字还是有很大差距的。 与猎头接触多了,自然也了解了他们的工作,包括操作手法,总体上国内的猎头行业还处在初级阶段。
总结就是“盲目推荐,以量取胜”。
目前现状
许多从事人力资源工作的人,根本不懂得怎么找人才。处在人才找不到企业,企业找不到人才的尴尬处境。
企业招聘,通常是需要用人的部门提出招聘条件,由人
- 搭建 CentOS 6 服务器 - 目录
rensanning
centos
(1) 安装CentOS
ISO(desktop/minimal)、Cloud(AWS/阿里云)、Virtualization(VMWare、VirtualBox)
详细内容
(2) Linux常用命令
cd、ls、rm、chmod......
详细内容
(3) 初始环境设置
用户管理、网络设置、安全设置......
详细内容
(4) 常驻服务Daemon
- 【求助】mongoDB无法更新主键
toknowme
mongodb
Query query = new Query(); query.addCriteria(new Criteria("_id").is(o.getId())); &n
- jquery 页面滚动到底部自动加载插件集合
xp9802
jquery
很多社交网站都使用无限滚动的翻页技术来提高用户体验,当你页面滑到列表底部时候无需点击就自动加载更多的内容。下面为你推荐 10 个 jQuery 的无限滚动的插件:
1. jQuery ScrollPagination
jQuery ScrollPagination plugin 是一个 jQuery 实现的支持无限滚动加载数据的插件。
2. jQuery Screw
S