Linux路由应用-使用策略路由实现访问控制
原文链接:http://blog.csdn.net/dog250/article/details/6685633 (高手博客)
一般而言,访问控制并不是路由模块完成的,而是防火墙的职责,如果你使用Linux的,这是iptables的职责。然而有时候,特别是在策略很多的情况下,使用iptables会极大降低网络性能,这是Netfilter的filter表的本质决定的,具体的优化参见《 Linux的Netfilter框架深度思考-对比Cisco的ACL》。
Linux有一个很实用的特性可以在某些情形下代替iptables,从而实现访问控制。本文给出一个方法,说明如何使用策略路由来控制数据访问的入口网卡,具体来讲就是:只有通过特定的网卡才能访问机器上的某一个地址。具体来讲,Linux服务器有如下配置:eth0:192.168.1.1/24
eth1:192.168.2.1/24
eth2:172.16.1.1/24
lo:127.0.0.1
只能通过eth0访问192.168.1.1这个地址,而不能通过eth1或者eth2访问,甚至本机都不能访问192.168.1.1。
但是在探讨如何做之前,首先要明白一些理论知识,这样才能知其然且知其所以然。
1.完成这个需求必须要明白的背景知识
1.1.Linux路由查找流程
所有的路由器设计都要遵循以下规则:IF 目的地址配置在本机
THEN 本机接收
ELSE
查找路由表并在找到路由的情况下转发
END
当然Linux也不能例外,但是Linux并没有将这这两种情况进行区分,而是使用“多张路由表”将二者统一了起来。在Linux中,内置了三张路由表:
local,main,default,其中local路由表的优先级最高,并且不能被替换,在有数据包进来的时候,首先无条件的查找local路由表,如果找到了路由,则数据包就是发往本机的,如果找不到,则接着在其它的路由表中进行查找。使用ip route ls table local命令可以看到local表的内容,比如机器的eth0网卡上配有192.168.0.7,则在local表中会有如下的路由:
local 192.168.0.7 dev eth0 proto kernel scope host src 192.168.0.7
值得注意的是,local表中的路由是可以删除的。路由的src项指的是当数据包从本机发出时,在local表中找到了源地址的路由,首选的源ip地址
在local表和main表之间,可以插入251张策略路由表,因此如果有策略路由表的话,如果local表中没有找到路由,则会查找策略路由表。
总结一下本节的内容,Linux内置了三张路由表,其中local路由表优先级最高且不可替换,它完成“IF 目的地址配置在本机 THEN 本机接收”这个逻辑,在local表之后,可以配置多张策略路由表,策略路由的知识本文不谈,但是基本就是根据源地址,目的地址,出接口,入接口等元素来决定数据包在路由前是否进入该张策略路由表,本质上是一种过滤行为(然则结果是可以缓存的,其要点就在于此!)。
1.2.bind地址/no-bind地址
有一个问题,那就是如果一个数据包从本机发出,如何确定其源地址,这个问题如果搞不明白,就可能面临很多奇怪的现象而无法解释,在这个问题上,TCP和UDP的行为是不同的,TCP比较简单,因为一个TCP连接是四元素决定的(源IP地址,目的IP地址,源端口,目的端口),因此在建立连接后,源/目的IP地址是确定的。对于UDP而言,情况就复杂了,下节详述。但是不管什么协议,在API接口层次上,一个socket分为bind地址的和不bind地址的。如果是bind地址,那么源地址就是bind的那个地址,如果没有bind,那么源地址在路由之后根据路由的结果确定。这就意味着,策略路由的from关键字将无法匹配到所有没有bind地址的应用程序从本地发出的包-原因是策略路由匹配是在路由前做的,而此时还没有源IP地址。
想明白协议栈如何这么设计,还是要从IP路由的本质以及传输层语义来分析。IP路由的职责就是能将IP数据报送到目的地,在路由之后选择源IP地址可以使返回的IP数据报在完全逆向路径上返回。考虑传输层的语义,对于TCP而言,其源地址的确定性是TCP做的,而不是IP层做的,这一点一定要清楚。对于不bind地址的情况,应用程序在数据包到达网络层之前不需要考虑网络层协议头的内容,这个工作完全有网络层的IP路由模块来完成,应用程序只需要指出目的IP即可,完全由协议栈负责网络层协议头的添加。
想明白协议栈如何实现这个逻辑,最好的办法是看Linux的源代码,方法是跟踪一个数据包发送的全过程源码,具体看ip_route_output_slow。
1.3.UDP踢皮球
讨论TCP的文章很多,TCP也有很多复杂的特性值得去深究,然而UDP也不是吃素的,有一种现象就是UDP连接会踢皮球,最终用TCPDUMP抓取的数据包结果会让人焦头烂额。其实只要明白1.2节的内容,本节的内容就很简单了。UDP无连接,不可靠,只负责将数据尽力而为传到目的主机,它对源和目的IP地址的管理很松散,UDP数据流(更确切的并不能称为数据流)是单包的。在两端都没有显式bind到具体的IP地址的情况下,最终的数据包可以使用任意的本机地址,关键看路由的结果。数据到达对端之后,如果对端也没有显示bind到具体的IP地址,那么回复包的源地址也可能不再是初始包的目的地址。我们还是用实例来说明吧,先看网络拓扑:
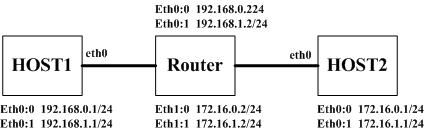
路由配置如下:
host1:default 192.168.0.2
host2:default 172.16.0.2
host1上运行一个UDP服务器,绑到0.0.0.0这个地址,也就是不绑定地址,host2向host1 192.168.1.1的UDP端口8888发送数据,抓包发现其源地址是172.16.0.1,目的地址是192.168.1.1,而返回包却抓不到了,意外抓取到一个源地址是192.168.0.1,目的地址是172.16.0.1的数据包。这是正常的,因为数据包到达host1时,查找返回路由时,会查到下一跳192.168.0.2,进而根据这个下一跳选择同一网段的192.168.0.1这个地址,此时如果添加一条路由:172.16.0.1 gw 192.168.1.2,那么就会看到返回数据包源地址为192.168.1.1了。
还有更奇怪的现象,那就是,初始时从host2向host1发送数据,源和目的分别是172.16.0.1和192.168.1.1,可是后来,在没有断开UDP客户端和服务器的情况下(host2更改了路由),源和目的分别成了172.16.1.1和192.168.0.1,这也是正常的,因为UDP本来就是无连接的,在不bind地址的情况下,关键是根据路由来选择源地址,选择源地址原则是:优先选择路由结果接口上和下一跳地址为同一网段的第一个primary地址,否则选择其它网卡上的primary地址,在选择过程中,有三个scope会影响选择结果,一个是下一跳地址scope,它表示该地址到达本地的“距离”,另一个是路由scope,它表示到达该路由的“距离”,还有一个是本地地址的scope,它限制了该地址的使用范围,路由模块保证下一跳的scope要小于路由的scope-背后的思想就是下一跳一定距离目的地比本机更近,而选择的本地地址的scope必须小于等于给定的scope(作为一个参数存在)。
UDP踢皮球有一个后果就是会影响Netfilter的ip_conntrack,我们知道,ip_conntrack是基于五元素来跟踪连接的,UDP的混乱情况可能使一个UDP数据流被跟踪好几次,从而使得后续的NAT规则(如果有的话)很复杂,NAT配置必须考虑到皮球的每一个方向,否则就会漏掉本来应该被NAT的数据包。
总之,网络是很复杂的,千万不要觉得就是配置几个IP地址以及几条路由那么简单的事。
1.4.路由前对本机出发数据包的源地址的检查
如果是本机发出数据包,最终要进入路由模块的ip_route_output_slow函数来查找路由,该函数对bind地址的源地址进行了检查,它保证到该本地地址的路由必须在local路由表中被找到。- static int ip_route_output_slow(...)
- {
- if (oldflp->fl4_src) {
- ...
- if (!(oldflp->flags & FLOWI_FLAG_ANYSRC)) {
- /* It is equivalent to inet_addr_type(saddr) == RTN_LOCAL */
- dev_out = ip_dev_find(net, oldflp->fl4_src);
- if (dev_out == NULL)
- goto out;
- ...
- }
- }
- }
ip_dev_find的实现中,有以下逻辑:
- local_table = fib_get_table(net, RT_TABLE_LOCAL);
- if (!local_table || local_table->tb_lookup(local_table, &fl, &res))
- return NULL;
这意味着本机出发的数据包的源地址如果有的话,必须要在local表中找到一条local路由,否则则返回EINVAL错误。然而可以取消这一限制,具体见1.6节。总而言之,FLOWI_FLAG_ANYSRC这个标志是基于socket,通过setsockopt可以设置socket,使与之相关的oldflp的flags中有FLOWI_FLAG_ANYSRC标志。
1.5.Linux的IP地址属于主机而不属于网卡
在Linux中,不要以为IP地址是属于网卡的,它是属于主机的,实际上就算是UNIX或者其它的OS,IP地址都不应该是网卡的,IP地址是三层概念,网卡是二层设备。很多人都认为IP地址是属于网卡的是因为在Linux中配置IP地址时都要给定一个网卡参数,比如ip address add dev ethX XXX/YY。IP地址是属于主机的,这就意味着,只要IP数据报到达本机,没有常规的方式使用路由限制该IP数据报不到达本地应用程序(local表是无条件最先被查询的,除非在local表中将该地址对应的local路由删除)。在procfs中使用sysctl能通过配置网卡参数达到限制数据包的目的吗?比如什么“关闭eth0的forwarding,这样数据包就不能从eth0 forward到eth2了”,根本不是那回事。
1.6.取消本地地址必须存在于local路由表的限制
2.6.27以上内核的socket选项IP_TRANSPARENT可以影响本机出发数据包路由查找时的源地址检测,具体做法是在应用程序中使用下列代码段:int value = 1;
setsockopt(fd, SOL_IP, IP_TRANSPARENT, &value, sizeof(value));
设置后,服务器回包的源地址不再限制在local表内,而是可以使用任何地址,包括非本机地址,这个技术一般用于透明代理。因此可以用这一特性来利用策略路由表完成本应该由防火墙完成的功能,不损耗性能。这样可以做到在local表中将eth0上的local路由删除,将该local路由加到策略路由中,本地应用程序将不能访问配置在eth0上地址。
在2.6.27之前,协议栈在添加源地址(或者用户指定了侦听地址)时,要确保local路由表中拥有该地址,否则会报错,而我们就是想把该地址的本机local路由移出local表,因此此功能不可实现。在2.6.27之后,增加了FLOWI_FLAG_ANYSRC标志,可以通过设置该标志做到限制的取消,具体做法有两种,一种是全局的,那就是将ip_route_output_slow中的if (!(oldflp->flags & FLOWI_FLAG_ANYSRC))判断取消掉,改为if (0);第二种改法是基于socket的,实际上FLOWI_FLAG_ANYSRC是基于单个socket设置的。完成此功能的前提:
1).内核编译了CONFIG_IP_MULTIPLE_TABLES
2).修改管理服务程序,为其socket增加IP_TRANSPARENT选项
2.具体操作
为了很简单的几步操作,前面啰里啰嗦说了那么多,实际上做技术本来就应该这样,必须挖掘深层次的原理,否则就只能算个IT工人。配置:
eth0:192.168.0.1/24
eth1:172.16.0.1/24
eth2:10.0.0.1/24
lo:127.0.0.1
2.1.限制从其它网卡接口访问特定网卡接口上配置的IP地址(这个说法不准确,具体见1.5节)对应的服务
2.1.1.添加一个策略路由表
echo "100 my" >> /etc/iproute2/rt_tables这样可以在local和main表之间增加一个路由表my,内核路由模块的查找顺序是:local->my->main...
2.1.2.增加一条策略
ip rule add from 192.168.0.1 table my2.1.3.在策略路由表中增加所有从eth0出去的路由
ip route add 12.34.0.0/16 via 192.168.0.2 dev eth0 table myip route add ... table my
...
ip route add default dev eth0 table my
所有匹配到my这个策略路由表的数据包,将从上述的路由项中查询结果。注意,最后一条默认路由是必须要的,且一定要从eth0出去,否则根据Linux策略路由查找原则,如果在my表中没有找到路由的话,还是会继续往下进行的,所谓的策略路由表只是一个优先级问题,而不是强制的查找约束。
2.1.4.结论和问题
通过以上的配置,所有从eth0进来的数据包才能安全返回,否则,比如从eth1进来一个访问192.168.0.1的数据包,由于它只有从eth1返回才可以(不考虑多径路由),然而返回包的源地址却是192.168.0.1(对应的服务不管是TCP的还是UDP必须显式bind到192.168.0.1这个地址,否则对于UDP就会有踢皮球的现象),这样路由查找就会进入my表(对于踢皮球的情况,就可能不进入my表),然则my表中没有一个从eth1出去的路由,且该包起码会匹配到my表的默认路由,数据包因此无法返回。现在考虑一下一个问题,如果是bind到192.168.0.1这个地址的服务主动访问外部,是不是也一定要从eth0出去呢?答案是肯定的,因为它bind了一个明确的地址,而源地址是该地址的数据包一定会匹配到my,最终起码会匹配到my的默认路由...
2.1.5.进一步的问题
现在已经实现了不能从除eth0之外的其它接口进入访问bind到eth0上地址的服务,然而如果希望做到连本地都不能访问该服务,那才是名副其实的“除eth0之外的...都不能...”,无疑本地出发的访问192.168.0.1的数据包肯定不是从eth0进入的。有一个办法可以解决这个问题,那就是禁用掉lo,因为在Linux中,所有从本地到本地的包都会被定向掉lo,禁掉lo后,所有本地到本地的包就都无法到达目的地。但是这种方法并不好,管不着人家就把人家关起来,非真的猛士!下一节我们就看看怎么做到本地不能访问本地eth0上的192.168.0.1这个地址,做到名副其实的“只有eth0进入的数据包才能访问”
2.2.限制本地访问本地bind到eth0上192.168.0.1这个地址的服务
想理解这个配置原理,还要回顾一下1.4节和1.6节,当理解了这两节之后,这里的配置就手到擒来了2.2.0.前提:两种方式
之一:直接将内核中的检查取消掉,见1.6节之二:改写bind到192.168.0.1地址服务程序,为其socket增加IP_TRANSPARENT选项,
2.2.1.添加一个新路由表
echo “100 my_rule” >> /etc/iproute2/rt_tables2.2.2.增加一条策略:从eth0到来的数据包,开放my_rule路由表
ip rule add iif eth0 table my_rule所有从eth0进来的数据包,查找my_rule表中的路由
2.2.3.为新增策略增加190.7 local路由
ip route add local 192.168.0.1/32 dev lo table my_rule由于到达本地的数据包要想成功到达,必须要找到一条local路由(类型对即可,无需非要在local表),因此在my_rule中增加一条到达192.168.0.1的local路由
2.2.4.删除原有的local表中的192.168.0.1路由
ip route del local 192.168.0.1/32 table local由于2.2.0中的两种前提,对源地址的检测已经取消了,到达源地址的路由现在没有必要非要在local表中了,因此即使删除了local中到达192.168.0.1的路由,也无所谓,返回包会直接使用源地址192.168.0.1而不被检查。
2.2.5.结论和问题
2.2.1-2.2.4的结果就是:访问192.168.0.1的数据包从eth0而来,查找my_rule表,找到,对于返回包,由于IP_TRANSPARENT取消了限制,可以正常返回;对于从非eth0到来的访问192.168.0.1的包,由于192.168.0.1的local路由已然被删,my_rule由于只匹配入口为eth0的数据包因而不对其开放,将无法访问。这个配置在2.1节的基础上做了增强,然而由于要修改bind到192.168.0.1地址的服务程序,对于既有的闭源程序的类似的访问控制将没有用武之地(这些程序没有源码,不能修改)。
3.总的结论
本文给出了一种使用路由进行访问控制的方式,对于规则比较简单,且访问控制都在第三层的场景中,路由的方式要比用防火墙更好,不会影响性能。然而本文的讨论完全是基于Linux的,对于非Linux的系统,比如Cisco,可能人家的ACL防火墙实现得比较高效,比iptables配置的更好,也就不需要用路由的方式进行访问控制了,就算对于Linux本身,nf-HiPAC对filter表做了优化之后,路由的方式进行访问控制的优势也减少了。 总之,Linux网络或者说网络本身是一个超级复杂的系统,不同的实现对于配置方式的选型影响巨大,然而有一个问题,比如像Windows这样的系统,你还不知道它的网络协议栈实现的内幕,那么它的配置肯定也就比较固定,那就是Microsoft的建议配置。
实际上,由于增加了策略路由表,查表的过程也是遍历,并且根据策略路由表的match一个一个比较,这个过程和filter表的查询过程几乎是一样的,则策略路由的优势体现在何方?实际上,路由和filter有一个区别,那就是路由是可以缓存的,而filter则是每包匹配的,有一种基于状态的防火墙可以“缓存”过滤结果,但是由于需要维护连接状态,这笔开销也是不可小觑的。路由缓存是完全独立的,路由完全缓存在一个hash表当中。
但是,如果路由缓存hash表的冲突链表过长(缓存太大了),或者hash算法太菜,在配置大量策略路由和配置iptables之间权衡的话,后者也不是总是处于劣势,孰是孰非,只有具体情况具体分析,只有分析了具体的性能数据才能有结论,否则只是纸上谈兵一纸空文。
4.两篇文档
linux-source/Documentation/networking/tproxy.txtlinux-source/Documentation/networking/policy-routing.txt