布隆过滤器(Bloom Filter)
什么是布隆过滤器?
维基百科给出的解释如下:
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制矢量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果有1亿个不重复的网址,如何判定某个网址是否包含在这1亿个地址中?可能第一时间就想到用hash表了。但是,如果用hash表,存储1亿个网址,假设1亿个网址都被压缩为8字节的短网址,因为hash表中不可避免总会发生碰撞,如果控制hash表的装填因子在0.5左右,那至少需要的内存大小为:2*8*10^8/(1024^3)=1.5G。如果需要存储10亿,100亿的网址呢?有人会说,可以采用位图的方式,将每个网址经过一个哈希函数映射到某一位,比如1亿个网址,只需要1亿位就可以保存,也就只需要1*10^8/(1024^2*8)=11.9M。但是因为哈希函数冲突概率太高,假设要将冲突概率降低到1%,至少要将位图长度设定为url个数的100倍,所以使用的内存大小也接近1G了。显然,这种情况下hash表或位图处理就不再合适。这时候就需要用到布隆过滤器了。
布隆过滤器原理
布隆过滤器需要一个位数组,这点和位图类似。还需要k个映射函数,这点和hash表类似。
1)加入元素
首先,将长度为m个位数组的所有的位都初始化为0。如下图:

其中的每一位都是一个二进制位。
对于有n个元素的集合S={s1,s2,...,sn},通过k个映射函数{f1,f2,...,fk},将集合s中的每个元素映射为k个值{b1,b2,..,bk},然后再将位数组中的与之对应的b1,b2,...,bk位设置为1:

这样,就将一个元素映射到k个二进制位了。
2)检查元素是否存在
如果要查找某一个元素是否在集合S中。就可以通过映射函数{f1,f2,...,fk}得到k个值{b1,b2,..,bk},然后判断位数组中对应的b1,b2,...,bk位是否都为1,如果全部为1,则该元素在集合S中,否则,就不在集合S中。
但有没有误判的情况呢?即对应的位数组的位都为1,但元素却不在集合中。答案是有可能会有误判的情况,但这个概率很小,通常在万分之一以下。下文再继续论述。
布隆过滤器误判概率计算
假设布隆过滤器中的hash函数满足假设:每个元素都等概率的hash到m个位中的任何一个,与其他元素被hash到哪个位无关。那么,对某一个特定的位在一个元素被插入时没有被设置为1的概率是:1-1/m。
那么,k个hash函数中没有一个对该位设置为1的概率为:(1-1/m)^k。
如果插入了n个元素,但是都没有对该位设置为1的概率为:(1-1/m)^kn。
所以,插入了n个元素,该位被设置为1的概率为:1-(1-1/m)^kn。
在查询阶段,如果对应某个等待查询元素的k个位全部被设置为1,则判定它在集合中。因此,将元素误判的概率为
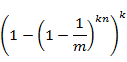
根据高等数学中的知识:
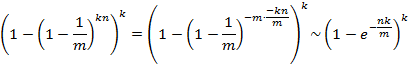
可以看出,当m增大或者n减小时,也就是位数组的位数越多或者集合元素数目越少,误判率都会减小。那么,k的值是多少时,可以让误判率最低呢?
经过计算,当k=ln2×m/2时,即k=0.7*m/n时,误判率最低。此时,误判率约等于0.6185^(m/n)。
我们此时可以计算以下,对于n=1亿时,如果取m=10亿位,那么k=7,此时的误判率为0.0082,降到了1%以下,但是只需要119M内存就可以存储。
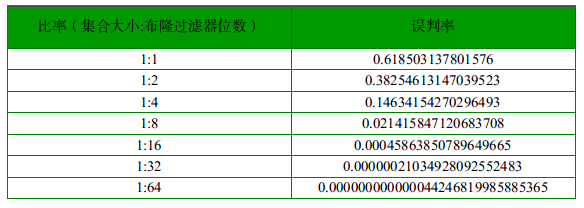
布隆过滤器误判率表如下:
一个简单的布隆过滤器代码如下:
package com.algorithm;
import java.util.BitSet;
public class SimpleBloomFilter {
private BitSet bits;
private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37, 61 };
private SimpleHash[] hashFunctions = new SimpleHash[seeds.length];
public SimpleBloomFilter() {
this(2 << 24);
}
public SimpleBloomFilter(int size) {
bits = new BitSet(size);
for (int i = 0; i < hashFunctions.length; i++) {
hashFunctions[i] = new SimpleHash(size,seeds[i]);
}
}
public void add(String value) {
for (SimpleHash hashFunction : hashFunctions) {
bits.set(hashFunction.getHashCode(value),true);
}
}
public boolean contains(String value) {
if (null == value) {
return false;
}
boolean result = true;
for (SimpleHash hashFunction : hashFunctions) {
result = result && bits.get(hashFunction.getHashCode(value));
}
return result;
}
public static void main(String[] args) {
SimpleBloomFilter bloomFilter = new SimpleBloomFilter();
String value = "iAm333";
System.out.println(bloomFilter.contains(value));
bloomFilter.add(value);
System.out.println(bloomFilter.contains(value));
}
}
其中,计算hash值的代码:
package com.algorithm;
public class SimpleHash {
private int size;
private int seed;
SimpleHash(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int getHashCode(String value) {
int result = 0;
int length = value.length();
for (int i = 0; i < length; i++) {
result = seed * result + value.charAt(i);
}
return (size - 1) & result;
}
}
转载请注明出处: http://blog.csdn.net/iAm333