使用堆查找前K个最大值兼谈程序优化(下)
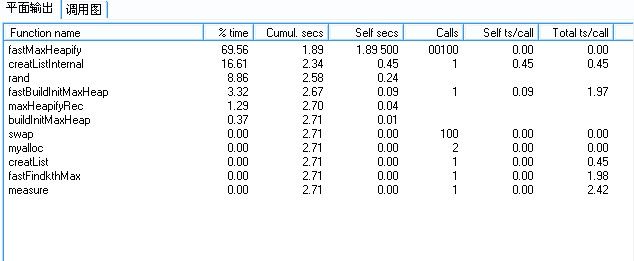
在建立正确性的回归测试之后,继续前进。 首先用性能工具分析下, 发现有点悲剧: 效率又倒退了。去除不必要的系统调用后, Profile分析结果如下:

七、 一些小改进
生成一亿个随机数也比较耗时, 可以看到rand()耗费时间并不多,但creatListInternal 耗费时间却很多, 可以推断, 模运算上耗费了很多时间。可以消除模运算。使用(1+rand()+rand()) * (1+rand()) 来生成随机数, (1-65535)*(1-32768) ,可以随机生成1- 65535*32768 之间的任何数。当然,这只是个简单的算法,会有重复元素。 此外,还可以启用编译器优化选项。
八、 聚焦热点区域, 减少比较次数
不去优化次要的地方,再次聚焦热点区域。 可以发现,fastFindkthMax 的主要时间几乎都花在 fastMaxHeapify 上。 只要改进 fastMaxHeapify 的比较次数即可。 对于结点有左右孩子结点的大多数情形,原来的实现中,总要进行两次与heapsize的比较; 但事实上只需要进行一次比较, 对相应代码做一些改动, 即可获得一定的提速。代码如下:
if (rch <= heapsize) {
if ((*(list+lch)) > temp) {
curr_largest = lch;
}
if ((*(list+rch)) > (*(list+curr_largest))) {
curr_largest = rch;
}
}
else {
if (lch <=heapsize && (*(list+lch)) > temp) {
curr_largest = lch;
}
}
九、 高速缓存的影响
在(上篇)中,一位博友提醒说高速缓存也起着重要的影响。 感谢他的提醒! 鉴于自己在这方面掌握不够扎实,暂时留空。
十、 回到算法, 思路比较
要提速,还是要寻找更好的算法改进。 有没有更好的算法呢? 本文的算法有点“笨拙”, 先分配N个数,然后对这N个数建最大堆, 最后依次找出K个最大数。另有两种思路如下:
1. 最小堆。 首先在N个数中选择K个数建立K个元素的最小堆。 接着, for i = K+1 to N : 如果 i 小于最小堆的根元素, 那么直接不做理会; 如果 i 大于最小堆的根元素,那么, 将其替代堆的根元素,并重构最小堆。 其正确性如下: A。 初始状态下, 堆中所有元素都比空元素大; B。 对于每次重构最小堆之后, 堆中的元素总是比被替代出来的所有元素要大;C。 当循环结束后,堆中的元素就比所有不在堆中的元素要大。其效率为 O(K + NlogK) ;
2. 分治。 分而治之总是一种有效的策略。 先将N个数分成b 堆, 每堆 N/b 个数。 对于每个堆找出前K个从大到小排序的最大数 b*O(N/b+Klog(N/b)) ;最后, 在这b个堆的已排序的K个最大数(bK)找出前K个最大数(O(b+(K-1)logb))。这种算法对于多处理器、并行执行机器更为有效,其时间为O(N/b+Klog(N/b)+b+(K-1)logb) + C(N), C是通信时间。对于大数据量处理来说, 并行算法是一种非常值得研究的领域。