【学习记录】关于数据库优化的几点知识以及事务和锁
上午实习导师潇哥考核了下业务知识,然后说给你们讲下数据库这边的东西吧,然后balabala讲了挺多有用的。
下午把上午学到的梳理了下,包括查了一些资料,就整理了一篇文章出来。
数据库的基本优化
首先,数据库优化的最基本规则有两点:
1.减少IO次数。
2.减少计算次数。(如果某查询会常用到而且计算次数较多的话,应当放在一张表中以减少计算)
然后是索引,众所周知索引是提高查找效率的。
但是当查询结果的字段数量占表中所有字段数比重越多的时候,索引与全表扫描查找的效率差值就越来越小,当到达一个阈值,索引的效率甚至会低于全表扫描,这个阈值一般会在5%左右,也就是查询结果数量占全表的5%以下时,用索引的效率是很高的。
但是在现在这个规则不是很适用了,因为现在的数据库中添加了一个叫做CBO(Cost Based Optimizer)的机制,会自动选择更适合的执行方式(走索引还是全表扫描)。
然后是join,关系型数据库之所以可以被称所关系型数据库的关键。
自然链接:join:链接的两个表都会显示,若无数据则显示空
左链接:left join:链接以左边表为准,左边表有数据才会显示此条目
右链接:right join:类比左链接,作用相反。
对join的优化,主要也是最基本的,就是调换join的顺序。
1.若表a和表b均为1000w级别的表,c为1w级别的表,那么 a join b join c where xx = xx 这条语句查找数量级为1000w*1000w 以及1000w * 1w,而将顺序换为a join c join b where xx = xx 后,数量及变为了1000w*1w和1w*1000w,数量级显著降低了三个层级。
2.尽量避免无索引的大表(如两个大表join后的结果集)去join另一个表(无论此表有无索引),因为这会很慢。
解决办法:hash join。这个是在oracle中内置的一中join方法,可以解决上面这种问题,原理是将两个表先hash再join。现在定制的mysql也可以使用该方法。
索引工作模式图
索引有B+tree索引、bitmap索引(仅oracle有)、reverse索引(翻转索引)等,最常用的是B+tree索引。
B+tree索引
bitmap索引
reverse索引
下图是一个简单的B+tree索引示意图(图引B+树索引—水墨江南):
事务和锁
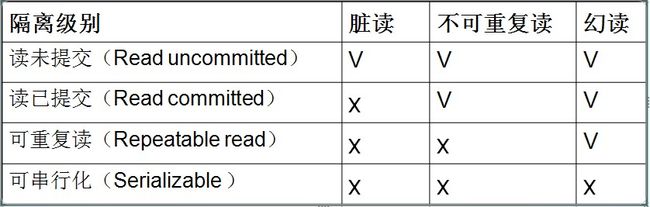
某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read)
在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read)
在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
1、用begin,rollback,commit来实现
begin 开始一个事务
rollback 事务回滚
commit 事务确认
2、直接用set来改变mysql的自动提交模式
set autocommit=0 禁止自动提交
set autocommit=1 开启自动提交
来实现事务的处理。
但注意当你用 set autocommit=0 的时候,你以后所有的SQL都将做为事务处理,直到你用commit确认或rollback结束,注意当你结束这个事务的同时也开启了个新的事务!按第一种方法只将当前的作为一个事务!
个人推荐使用第一种方法!
MYSQL中只有INNODB和BDB类型的数据表才能支持事务处理!其他的类型是不支持的!(切记!)
| name | balance | version |
| pandadru | $1000 | 0 |