Hadoop学习第一章_初识Hadoop
初识Hadoop
Apache软件基金会开发的分布式计算平台 —核心—>HDFS(分布式文件系统)和MapReduce(Google MR开源实现)
作用:
有效存储和管理大数据
应用:
FaceBook 存储内部的日志拷贝,数据挖掘和日志统计
Yahoo 支持广告系统并处理网页搜索
Twitter 存储微博数据、日志文件和其他中间数据
百度 日志分析和网页数据库的数据挖掘
阿里巴巴 商业数据排序和搜索引擎的优化
优势:
* 高可靠 按位存储和处理数据能力高
* 高扩展 使用计算机集簇分配数据并计算,集簇便扩展
* 高效 能在节点间动态移动数据,并保持个节点动态平衡,故处理速度极快
* 高容错 能自动保存数据的多副本,自动将失败任务重新分配
结构:
Pig Chukwa Hive HBase
核心 MapReduce HDFS ZooKeeper
基础API Core Avro
* Core 提供常用工具 API
*Avro 数据序列化系统 提供数据结构类型、快可压二进制格式、存储文件集 简单调用语言
*MapReduce 并行

*HDFS 分布式文件系统
*Chukwa 数据收集
*Hive 整理、存储 查询数据集工具 支持传统RDBMS的SQL语句查询
*HBase 分布式、面向列的开源数据库
适合存储非结构化数据
基于列模式
*Pig 经受住大数据处理的平台
体系:
*HDFS 分布式底层存储支持
主从模式 NameNode和DataNode一对多
NN 主服务器,管理文件系统及客户对其的操作
DN 管理存储数据,受NameNode调度进行相应操作,1文件1组DateNode
关系图如下
*MapReduce 分布式并行任务处理支持
并行编程模式,将任务分发到多台机器的集群上,以高容错方式并行处理大数据集的框架
主节点 JobTracker
集节点 TaskTracker

数据管理:
* HDFS数据管理 NameNode-DataNode-Client
补充:一个Block会有三份备份;写入文件时,客户端读取一个Block,然后写到第一个DataNode上,接着备份至其他DataNode,知道所有需要此Block的DataNode都成功写入才写下一个Block

* HBase数据管理 HClient-HMaste-HRgionr
结构图
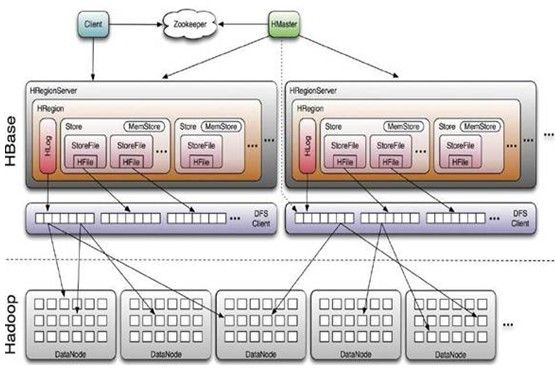
Table & Column Family
Row Key
Timestamp
Column Family
URI
Parser
r1
t3
url=http://www.taobao.com
title=天天特价
t2
host=taobao.com
t1
r2
t5
url=http://www.alibaba.com
content=每天…
t4
host=alibaba.com
Ø Row Key: 行键,Table的主键,Table中的记录按照Row Key排序
Ø Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
Ø Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
Table & Region
当Table随着记录数不断增加而变大后,会逐渐分裂成多份splits,成为regions,一个region由[startkey,endkey)表示,不同的region会被Master分配给相应的RegionServer进行管理:
-ROOT- && .META. Table
HBase中有两张特殊的Table,-ROOT-和.META.
Ø .META.:记录了用户表的Region信息,.META.可以有多个regoin
Ø -ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
Ø Zookeeper中记录了-ROOT-表的location
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做cache缓存。

Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
1. 管理用户对Table的增、删、改、查操作
2. 管理HRegionServer的负载均衡,调整Region分布
3. 在Region Split后,负责新Region的分配
4. 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,HRegion中由多 个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。
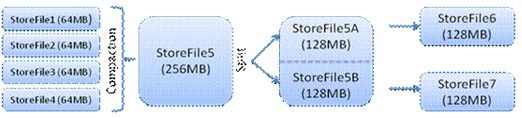
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。MemStore是 Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile), 当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进 行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要 进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前 Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上。下图描述了Compaction和Split的过程:
HLog
通过HBase架构图得出, HLog与HRegionServer一一对应
* Hlog在Hbase写数据时,相对应的工作阶段如下:
向HBase Put数据时通过HBaseClient-->连接ZooKeeper
--->-ROOT--->.META.-->RegionServer-->Region:
Region写数据之前会先检查MemStore.
1. 如果此Region的MemStore已经有缓存已有写入的数据, 则直接返回;
2. 如果没有缓存, 写入HLog(WAL), 再写入MemStore.成功后再返回.
* HLog生命周期:
一般来说HLog File的生命周期有两种(下面RS 指HRegionServer):
1. 正常的情况
RS 创建 HLog File -> RS append HLog File -> 关闭 HLog File -> File Max SeqNum 小于所有StoreFile的SeqNum -> 转移File至.oldlog文件夹 -> 删除 HLog File
当File Max SeqNum 小于所有HFile的SeqNum的时候说明这个File里面的所有Entry都已经安全的存在StoreFile里面了,这个HLog File就没有用处了,可以被删除了。
2. 异常的情况
RS 创建 HLog File -> RS append HLog File -> RS Crash -> MasterServer Split File -> New RS load Region -> New RS delete File Split
在异常情况下HLog File会被分解成N个文件, N = HLog File包含的Region数。这时HLog跟随Region,Region 被分配给一个新的RS之后,新的RS就会来处理HLog片段。

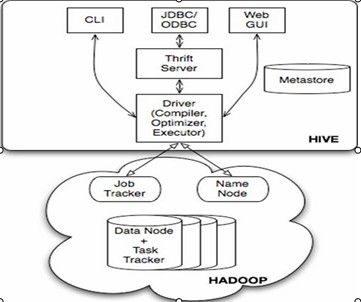
*Hive数据管理
与Hadoop关系:
元数据存储(三模式):
* 单用户:连接到一个In-Memory的数据库Derby,主用于UnitTest
* 多用户:通过网络连接到数据库,常用
* 远程:非Java客户端访问元数据库,服务端启动MetaStoreService,客户端利用Thrift协议通过MetaStoreService访问元数据库
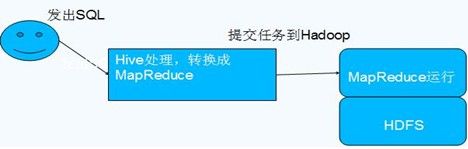

Hive数据存储:
•Hive的数据存储是建立在Hadoop HDFS之上的
•Hive没有专门的数据存储格式
•存储结构主要包括:数据库、文件、表、视图
•Hive默认可以直接加载文本文件,还支持sequence file 、RCFile
•创建表时,我们直接告诉Hive数据的列分隔符与行分隔符,Hive即可解析数据
Hive数据交换:
•用户接口,包括 CLI,JDBC/ODBC,WebUI
•元数据存储,通常是存储在关系数据库如 mysql, derby 中
•解释器、编译器、优化器、执行器
•Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算。
下一章 介绍MapReduce 计算模型,关键内容是一流程四方法