第八章 采用PCA(主成分分析)或LDA(线性判别分析)的人脸识别(一)
【原文:http://blog.csdn.net/raby_gyl/article/details/12611861】
注释:
1、翻译书名:Mastering OpenCV with Practical Computer Vision Projects
2、翻译章节:Chapter 8:Face Recogition using Eigenfaces or Fisherfaces
3、电子书下载,源代码下载,请参考:http://blog.csdn.net/raby_gyl/article/details/11617875
转载请注明:http://blog.csdn.net/raby_gyl/article/details/12611861
Chapter 8:Face Recogition using Eigenfaces or Fisherfaces
在这一章我们将介绍人脸检测和人脸识别的概念,提供了一个人脸检测和识别的工程。人脸识别是一个流行和困难的话题,许多研究人员投身于人脸识别领域好多年。因此在这一章我们将阐述简单的人脸识别方法,给读者一个好的开始,如果你想开发更复杂的方法。
在这一章,我们将包括以下内容:
1、人脸检测
2、人脸预处理
3、用搜集来的人脸来训练一个机器学习算法
4、人脸识别
5、收尾工作(最后一笔)
人脸识别和人脸检测引言
人脸识别是一个给已知人脸贴上一个标签的过程。就像人类仅仅通过看他们的脸来学习识别他们的家庭,朋友和名人,对于计算机有很多学习识别已知人脸的技术。大体包括四个主要步骤:
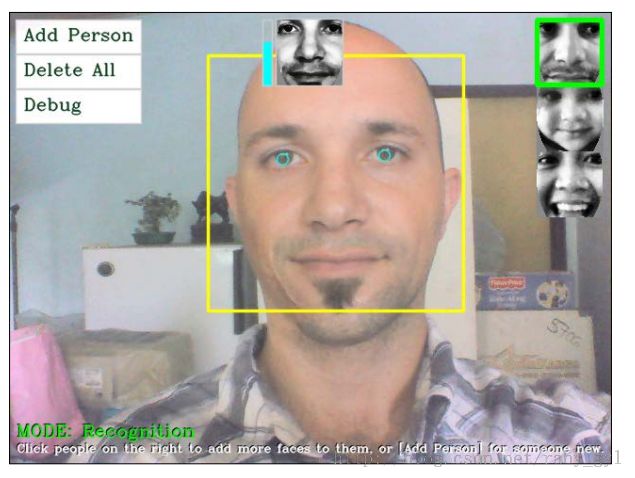
1、人脸检测:它是图像中定位人脸区域的过程(一个大的矩形靠近下面截图的中心)。这一步我们不需要关心这个人是谁,仅仅知道是个人脸就可以了。
2、人脸预处理:校正人脸图像,使其看起来更清晰类似于其他人脸的过程(在下面截图上中部的小的灰色人脸)
3、收集和学习人脸:保存大量处理过的人脸(对于每一个应当被识别人),接着学习如何识别他们的过程。
4、人脸识别:选择收集的人脸图像中哪个更接近相机中的人脸的。(如下截图右上部分的小矩形)
注释:注意人脸识别这个短语经常被大众用于寻找人脸的位置(即人脸检测,就像步骤1描述的那样),但是在这本书中我们使用一个正式的人脸识别定义——参考步骤4和人脸检测定义——参考步骤1.
下面的截图展示了最终的网络相机人脸识别工程,包括右上角的加亮了已识别人脸的小矩形。也注意到了信任尺度条,它邻接着的预处理的人脸(在标记人脸矩形的中上处的小的人脸),这展示了在本例中大约70%的信任度,它识别了正确人脸。
现在的人脸检测技术在现实生活的环境中相当可靠,然而当被用于现实生活的环境中,现在的人脸识别技术却很少可靠。例如,很容易找到论文,该论文展示了人脸识别的准确率在95%以上,但是当你亲自测试那些同样的算法时,你经常发现准确率低于50%。这来至于现在的人脸识别技术非常敏感于图像中严谨的环境,例如照明的类型,照明的方向和影子,严谨的人脸方位,面部表情,和这个人当前的情绪。如果在我们训练(搜集图像)和测试(来之相机的图像)时,他们都保持不变,那么人脸识将很有效。但是如果一个人屋内训练的时候站在灯光的左手边,并且用相机测试的时候站在右手边,这将产生一个相当坏的结果。因此用作训练的数据集非常重要。
人脸预处理(步骤2)的目的是减少这些问题,例如:确保人脸总是显示同样的亮度和对比度,并且可能确保人脸的特征总是在同一个位置(例如调整人脸或者鼻子到某一位置)。一个好的人脸预处理将会帮助改善整个人脸识别系统的可靠性,因此在这一章将强调人脸预处理的方法。
尽管一个大的主张是媒体中人脸识别的安全,现在的单独的人脸识别方法对于任何真正的安全系统足够的可靠是不可能的,但是他们能使用于不需要高的可靠性的目的,例如为不同的人进入房间播放个性化的音乐或者一个机器人当它看到你是能说出你的名字。也有各种各样的人脸识别实用性的延伸,例如性别识别,年龄识别,情感识别。
步骤1:人脸检测
直到2000年,有很多不同的技术用在人脸检测,但是所有的这些都很慢,不可靠或者两者兼有。2001年发生了重大变化,Viola和Jones发明了基于Haar级联目标检测分类器。并且在2002年,Lienhart和Maydt.改进了该方法。结果是目标检测即快(能够在一个典型的带有VGA网络摄像头的台式电脑上实时检测人脸)又可靠(正脸检测的正确率大约95%)。目标检测器革新了人脸检测的邻域(总的来说就像机器人学和机器视觉),因为它最终实现实时人脸检测和人脸识别。尤其当Lienhart他亲自写的目标检测器免费的应用到Opencv。它不仅对正脸有效而且对测视人脸(称做侧脸),眼,嘴,鼻子,公司标识和其他一些目标也有效。
目标检测器在OpenCV2.0得到扩展,使用了LBP特征作为目标检测,是基于2006年Ahonen,Hadid和Pietikäinen的工作。因为基于LBP检测器比基于Haar检测器可能地快好几倍。并且不需要证书问题,而一些Haar检测器需要。
基于Haar人脸检测器的基本思想是,如果你观察大多数的正面脸,眼睛所在的区域要比前前额和脸颊深一些,并且嘴所在的区域也应当比下脸颊深一些,等等。它典型地执行类似的20次比较操作,来判别是否是一个人脸,但它必须处理图像中每一个可能的位置和每一个可能的人脸大小。因此事实上,对于每个图片经常要做数千次的检测。基于LBP人脸检测器的基本思想类似于基于Haar的人脸检测器,但是它利用像素强度的直方图做比较,例如边缘,角点和平坦的区域。
而不是使人决定对于定义一张人脸哪个比较方法较好,基于Haar和基于LBP的人脸检测器都能够自动的训练来从大量的图片中找到人脸,将大量的信息存储在将要用到的XML文件中。这种级联分类检测器典型地要用至少1000张唯一的人脸图像和10000张非人脸图像(例如树,车和课本的照片),并且甚至在一个双核的台式电脑上,训练过程也将花费很长的时间(典型地LBP需要几个小时,而Haar需要一周)。幸运的是OpenCV带有预先训练的Haar和LBP检测器给你们使用。事实上你可以检测正脸,侧脸,眼睛,鼻子只需要导入不同的人脸级联分类器的XML文件到目标检测器。选择Haar还是LBP检测器是基于你选择的哪个XML文件。
使用OpenCV实现人脸检测
像前面提到的,OpenCV v2.4带有各种各样预先训练的XML检测器,你可以用于不同的目的。下面的表格列出了一些常用的XML文件:

基于Haar的人脸检测存储在文件夹data\haarcascades下,基于LBP的人脸检测存储在文件夹data\lbpcascades下。该文件夹在opencv的根目录,例如c:\opencv\data\lbpcascades\。
对于我们的人脸识别工程,我们想检测的正面人脸,因此我们使用LBP人脸检测器,因为它最快并且不存在潜在的证书问题。既然预处理LBP人脸检测器来至于OPenCV2.x,不像预先处理的Haar人脸检测器那样悠久,因此如果你想更加可靠的人脸检测,你可以训练你自己的LBP人脸检测器,或者使用Haar人脸检测器。
为目标或者人脸检测导入Haar或者LBP检测器
为了进行目标或者人脸检测,首先你必须使用OpenCV的CascadeClassifier类导入预先训练的XML文件,如下:
- CascadeClassifier faceDetector;
- faceDetector.load(faceCascadeFilename);
仅通过指定不同的文件名就可以导入Haar或者LBP检测器。一个常见的错误是当你使用它时提供了一个错误的文件夹或者文件名,但是依赖于你建的环境,load()方法将会返回false或者产生C++异常。(带有一个中断异常退出你的程序)。因此最好在load()方法外面添加一个try/catch块来显示错误信息给用户,当程序出错时。许多初学者跳过错误的检查,但是当不能正确导入时,展示一个帮助信息对用户很重要,否则在最终意识到你未正确导入之前,你可能花很长的时间来调试你的代码的其他部分。一个简单的错误提示如下:
- CascadeClassifier faceDetector;
- try {
- faceDetector.load(faceCascadeFilename);
- } catch (cv::Exception e) {}
- if ( faceDetector.empty() ) {
- cerr << "ERROR: Couldn't load Face Detector (";
- cerr << faceCascadeFilename << ")!" << endl;
- exit(1);
- }
访问网络摄像头
为了从计算机的网络摄像头获取视频帧或者甚至从一个视频文件,你可以简单地调用VideoCapture::open()函数,用摄像机数字号或者视频文件名作为参数,接着用C++流操作获取视频帧,正如在第一章(卡通漫画制作和肤色改变for安卓)的访问网络摄像头部分。
用Haar或者LBP分类器检测目标
既然我们已经导入了分类器(在初始化时仅一次),我们可以使用它来检测视频的每一帧中的人脸。但是首先我们应当为了人脸检测做一些相机照片的初始化处理,通过执行下面的步骤:
1、灰色彩色转换:
人脸检测只处理灰度图像,因此我们将彩色相机帧转换为灰色图像。
2、缩小相机图像:人脸检测的速度依赖于输入图像的大小(大的图像检测很慢但是小的图像检测很快)。甚至在低分辨率的图像中检测仍然相当可靠。因此我们需要缩小相机图像到一个更加合理的尺寸(或者在检测器中使用一个大的minFeatureSize参数值,过会要讲)
3、直方图均衡化:人脸检测在光线暗的环境中不那么可靠。因此我们需要进行直方图均衡化来提高对比度和亮度。
灰色彩色转换
我们可以很容易使用cvtColor()函数来现实彩色图像到灰度图像的转换。但是只有当我们知道我们用的是彩色图像(也就是说,它不是一个灰色的相机)时才能那么做,并且我们指定输入图像的格式(通常计算机上为3通道BGR或者手机上的4通道的BGRA)。因此我们应当采用三个不同的输入彩色格式,如下代码展示:
- Mat gray;
- if (img.channels() == 3) {
- cvtColor(img, gray, CV_BGR2GRAY);
- }
- else if (img.channels() == 4) {
- cvtColor(img, gray, CV_BGRA2GRAY);
- }
- else {
- //直接访问输入的灰度图像
- gray = img;
- }
缩小相机图像
我们可以使用resize()函数来缩小图像到某一大小或者尺度。人脸检测通常对于任何大于240*240像素的图像产生相当好的效果(除非你需要检测距离相机很远的人脸)。因为程序将寻找任何大于minFeatureSize(典型地20*20)的人脸。因此我们缩小相机图像到320像素的宽。输入的是VGA的网络摄像头或者5百万像素HD相机,这都没关系。记住和扩大的检测结果很重要,因为你是在一个缩小的图像中找到人脸,检测结果也将缩小。注意如果不使用缩小输入图像,你应当在检测器中使用一个到的minFeatureSize值。我们也必须确保图像不能变的更宽或者更窄。例如一个宽屏800*400的图像,当缩小到300*200时,人将看起来很窄。因此我们必须保持输出图像的宽高比(宽/高)和输入图像一样。让我们计算一下宽将缩小多少比例,并且应用同样的尺度到高度,如下:
- const int DETECTION_WIDTH = 320;
- // 可能性的缩放图像, 使检测更快.
- Mat smallImg;
- float scale = img.cols / (float) DETECTION_WIDTH;
- if (img.cols > DETECTION_WIDTH) {
- //缩放图像,同时保持同样的宽高比例
- int scaledHeight = cvRound(img.rows / scale);
- resize(img, smallImg, Size(DETECTION_WIDTH, scaledHeight));
- }
- else {
- //如果已经满足条件(即宽度不大于320),则我们不缩放,直接使用输入的图像。
- smallImg = img;
- }
直方图均衡化
我们可以简单地使用equalizeHist()函数进行直方图的均衡化来改善图像的对比度和亮度(就像learning OpenCV(Computer Vision with the OpenCV Library)阐述的那样)。有时这会使得图像看起来很奇怪,但是总的来说它改善了亮度和对比度,并且有助于人脸检测。equalizeHist()函数使用如下:
- //标准化亮度 & 对比度,例如改善深色图像
- Mat equalizedImg;
- equalizeHist(inputImg, equalizedImg);
检测人脸
既然我们已经将图像转换为灰度,缩小了图像,并且均衡化了直方图。我们准备使用CascadeClassifier::detectMultScale()函数来检测人脸。我们将传递很多参数到这个函数:
1、minFeatureSize: 这个参数决定了我们所关心的人脸的最小尺寸,典型地是20*20或者30*30像素,但是这依赖于你的使用情况和图像的大小。如果你正在一个网络摄像头或者手机上进行人脸检测,这时的人脸经常会离相机很近,你应当扩大这个参数到80*80,这样检测会更快。或者如果你想检测远距离的脸,例如和朋友在海滩上,这是采用20*20。2、searchScaleFactor:这个参数决定了我们要寻找多少种不同大小的人脸。典型的1.1,可以得到好的检测效果。或者1.2可以更快的检测(时常检测不到人脸)。
3、minNeighbors: 这个参数决定了怎样确保检测器应当已经检测到了人脸,典型值是3,如果你想得到更可靠的检测,你可以设置高一点,虽然许多人脸不被检测到。4、flags: 这个参数允许你指定是否寻找所有的脸(默认)还是值寻找最大的脸(CASCADE_FIND_BIGGEST_OBJECT).如果你只想寻找最大的脸,检测会更快。还有许多其他参数你可以添加,用来使检测快百分之1,2。例如:CASCADE_DO_ROUGH_SEARCH或者CASCADE_SCALE_IMAGE.
detectMuliScale()函数的输出是一个cv::Rect类型对象的vector容器。例如,如果检测到两个人脸,则它将存储一组两个矩形作为输出。函数detectMultiScale()使用如下:
- int flags = CASCADE_SCALE_IMAGE; // 寻找许多人脸
- Size minFeatureSize(20, 20); // 最小人脸大小
- float searchScaleFactor = 1.1f; //多少大小将被寻找
- int minNeighbors = 4; // 可靠性vs人脸数量
- // 在缩小的灰度图像上检测目标
- std::vector<Rect> faces;
- faceDetector.detectMultiScale(img, faces, searchScaleFactor, minNeighbors, flags, minFeatureSize);
我们可以通过查看存储矩形的vecotr的大小来看是否所有的脸都被检测到,即通过使用objects.size()函数。
像前面提到的,如果用一个缩小的图像做人脸检测,结果图像也被缩小。如果我们想知道源图像的人脸区域,因此我们必须扩大他们。我们同样需要确保图像边界上的人脸能够完全在图像内部,如果这样的事情发生,opencv会产生一个异常,如下面的代码展示:
- // 如果图像之前被暂时的缩放了,那么扩大图像结果
- if (img.cols > scaledWidth) {
- for (int i = 0; i < (int)objects.size(); i++ ) {
- objects[i].x = cvRound(objects[i].x * scale);
- objects[i].y = cvRound(objects[i].y * scale);
- objects[i].width = cvRound(objects[i].width * scale);
- objects[i].height = cvRound(objects[i].height * scale);
- }
- }
- // 如果目标图像在边界上,保持它在图像内部
- for (int i = 0; i < (int)objects.size(); i++ ) {
- if (objects[i].x < 0)
- objects[i].x = 0;
- if (objects[i].y < 0)
- objects[i].y = 0;
- if (objects[i].x + objects[i].width > img.cols)
- objects[i].x = img.cols - objects[i].width;
- if (objects[i].y + objects[i].height > img.rows)
- objects[i].y = img.rows - objects[i].height;
- }
既然之前的代码可以寻找图像中所有的脸,但是如果你只关心一张脸,这时你应当改变flag变量如下:
- int flags = CASCADE_FIND_BIGGEST_OBJECT | CASCADE_DO_ROUGH_SEARCH;
本网络摄像人脸识别工程在Opencv的Haar或者LBP检测器上做了封装,使其更容易在图像中找到人脸或者人眼,例如:
- Rect faceRect; //存储检测到的结果,或者-1,例如Rect(-1,-1,-1,-1)表示为检测到,返回一个无效矩形
- int scaledWidth = 320; //在检测前缩放图像
- detectLargestObject(cameraImg, faceDetector, faceRect,scaledWidth);
- if (faceRect.width > 0)
- cout << "We detected a face!" << endl;
既然我们拥有了一个矩形,我们可以用许多的方式使用它,例如从源图像中提取或修剪人脸。下面的代码允许我们使用人脸:
- // 使用图像中的人脸
- Mat faceImg = cameraImg(faceRect);
下面的图像展示了一个典型的人脸检测器检测到的矩形区域:
步骤2:人脸处理
像先前提到的那样,人脸识别非常容易受到光照环境,人脸的方向,人脸表情,等等的影响。因此尽可能的减少这些差异非常重要。否则人脸识别算法会经常认为在同样的环境下两个不同的人脸比同一个的人脸更相似。
人脸的预处理的一个简单的形式是仅应用直方图函数equalizeHist()来均衡化,就像我们在人脸检测时做的那样。对于一些工程,这可能很充分,因为它们的光线和位置环境改变的不大。但是为了现实生活的环境的可靠性,我们需要许多复杂的技术,包括人脸特征检测(例如检测眼睛,鼻子,嘴和眉毛)。为了简单些,这一章我们仅使用眼睛检测,忽略其他面部特征,例如鼻子和嘴,他们很少有用。下面图像展示了一个放大的典型的预处理的人脸,采用的技术本部分将涉及到。
人眼检测
人脸预处理中眼睛的检测非常有用,因为对于正面人脸来说,你可以经常假定一个人的眼睛应当是水平的并且在人脸的对立面上,应当在人脸中有一个非常标准的位置和大小,尽管它会因为面部表情,光线环境,相机性能,到相机的距离等等而变化。它对于抛弃人脸检测器检测到错误的正样本人脸(false positives)(即错误的人脸,实际上是其他东西)很有用。人脸检测器和双眼检测器同时发生故障是很罕见的。因此如果你只用检测的人脸和检测的双眼来处理图像,这时它将不包括太多的错误正样本(false positives)(但是它也为处理得到了更少的人脸,因为人眼检测器不会像人脸检测器那样经常不工作)。
Opencv2.4自带一些预先训练的人眼检测器,能够检测眼是睁还是闭,然而其他一些只能检测到睁开的眼。
能够检测睁或者闭眼的人眼检测器如下:
1、haarcascade_mcs_lefteye.xml(and haarcascade_mcs_righteye.xml)2、haarcascade_lefteye_2splits.xml(and haarcascade_righteye_2splits.xml)
只能检测睁眼的人眼检测器:
1、haarcascade_eye.xml
2、haarcascade_eye_tree_eyeglasses.xml
注释:
1、因为睁或者闭眼的检测器指定他们是哪一只眼而被训练的,你需要使用不同的检测器来检测左眼和右眼,然而只能检测睁眼的检测器可以使用相同的检测器检测左眼和右眼。
2、检测器haarcascade_eye_tree_eyeglasses.xml能够检测到带眼睛的人脸,但是对于不带眼睛的检测不可靠。
3、如果XML文件名指明了左眼(left eye),它意味着是人的真实左眼,因此相机图像中左眼经常在人脸的右边,而不是在左边!
4、上边提到的四个检测器,是大约按照最可靠到最不可靠排列的,因此如果你知道你并不需要寻找带眼睛的人脸,此时第一个检测器可能是最好的选择。
人眼搜索区域
对于人眼检测,把输入的图像修剪成仅有大约眼睛的区域很重要,就像人脸检测做的那样。此时修剪成一个小的包含左眼睛的矩形(如果你正在使用左右检测器),右眼也同样如此。如果你仅在一整张人脸或者一整张图像上做人眼检测,此时会非常慢并且很少的可靠性。不同的人眼检测器适用于不同的人脸区域,例如,如果在一个实际人眼周围非常紧凑的区域搜索,the haarcascade_eye.xml 检测器将工作的最好。然而,如果在眼睛周围有一个大的区域搜索 ,haarcascade_mcs_lefteye.xml和haarcascade_lefteye_2splits.xml检测器工作的最好。
下面的表格列出了对于不同的人眼检测器的好的搜索区域(当使用LBP人脸检测器),使用在检测到的人脸矩形内的相对坐标:(x,y,width,height),这里是相对比例

这是用来从检测到的人脸中提取左眼区域和右眼区域的源代码:
- int leftX = cvRound(face.cols * EYE_SX);
- int topY = cvRound(face.rows * EYE_SY);
- int widthX = cvRound(face.cols * EYE_SW);
- int heightY = cvRound(face.rows * EYE_SH);
- int rightX = cvRound(face.cols * (1.0-EYE_SX-EYE_SW));
- Mat topLeftOfFace = faceImg(Rect(leftX, topY, widthX,
- heightY));
- Mat topRightOfFace = faceImg(Rect(rightX, topY, widthX,
- heightY));
下面的图像展示了不同人眼检测器的理想搜索区域,这里haarcascade_eye.xml和haarcascade_eye_tree_eyeglasses.xml在小的的搜索区域是最好的,同时haarcascade_mcs_*eye.xml和haarcascade_*eye_2splits.xml在大的搜索区域是最好的。注意,为了给出了眼睛搜索区域 大小的概念,和对检测到的人脸矩形进行了比较,我们在下图也将检测到的人脸矩形显示出来了。(有点拗口,红框为检测到人脸区域,蓝色和绿色是后两个检测器的最佳搜索区域,紫色为前两个检测器的最佳搜索区域)

当使用先前的表中给出的人眼搜索区域,这里是不同的人眼检测器的大约的检测性能:

*Reliability value(可靠性)展示了LBP正面人脸检测之后双眼被检测到的概率,此时没有带眼睛并且双眼是睁开的。如果眼睛闭合可靠性将下降,或者如果带眼睛则可靠性和速度都下降。
**Speed value(速度)是在Intel Core i7 2.2GHz上,图像尺度化为320*240像素大小的毫秒时间值(1000个图像的平均值)。检测到人眼的速度典型地要比未检测到人眼的要快,因为它必须扫描整个图像,但是haarcascade_mcs_lefteye.xml总是比其他的人眼检测器慢。
例如,如果你缩小一个图像到320*240像素,对它进行直方图均衡化,使用LBP人脸检测器得到一张人脸,接着使用haarcascade_mcs_lefteye.xml提取出左眼区域和右眼区域,并且对每个人眼区域进行直方图均衡化。此时如果你用haarcascade_mcs_lefteye.xml检测左眼(实际上在图像的右上部分),用haarcascade_mcs_righteye.xml检测右眼(实际上在图像的左上部分),采用LBP检测正脸后,每一个人眼检测器要处理大约90%的图像部分。如果你想双眼检测,它将处理大约80%的图像。
既然在检测人脸之前推荐缩小相机图像同时,你应当在整个相机分辨率上检测眼睛,因为眼睛显然比脸小,因此你需要尽可能得到高分辨率图像。
注释:
1、基于上述表格,好像当我们选择一个人眼检测器去使用时,你应当决定是否你想检测闭的眼睛或者只检测睁开的眼睛。并且记住,你甚至可以使用一个人眼检测器,如果它不能检测到一个人眼,你可以试试另外一个检测器。
2、对于许多任务,检测人眼睁开或者闭合是有用的,因此如果速度不重要,最好首先使用mcs_*eye检测器,如果它失败了,则使用eye_2splits检测器。
3、但是对于人脸识别,如果他们的眼睛闭合,一个人将表现的非常不同。因此最好首先使用简单的haarcascade_eye检测器,如果它失败了,则使用haarcascade_eye_tree_eyeglasses检测器。
我同样可以使用用在人脸检测的函数detectLargestObject()来寻找人眼,但是在人眼检测之前,我们代替缩小的图像,使用全眼区域图像的宽度来获得好的检测。用一个人眼检测器很容易检测到左眼,并且如果它失败了,接着尝试另外一个检测器(同样对于右眼),眼睛检测做法如下:
- CascadeClassifier eyeDetector1("haarcascade_eye.xml");
- CascadeClassifier
- eyeDetector2("haarcascade_eye_tree_eyeglasses.xml");
- ...
- Rect leftEyeRect; // 存储检测到的人眼
- //使用第一个人眼检测器搜索左边区域
- detectLargestObject(topLeftOfFace, eyeDetector1, leftEyeRect,
- topLeftOfFace.cols);
- //如果失败了,使用第二个人眼建仓期搜索左边区域
- if (leftEyeRect.width <= 0)
- detectLargestObject(topLeftOfFace, eyeDetector2,
- leftEyeRect, topLeftOfFace.cols);
- //如果一个检测器工作了,获得左眼中心
- Point leftEye = Point(-1,-1);
- if (leftEyeRect.width <= 0) {
- leftEye.x = leftEyeRect.x + leftEyeRect.width/2 + leftX;
- leftEye.y = leftEyeRect.y + leftEyeRect.height/2 + topY;
- }
- //对右眼做同样的操作
- ...
- // 检查是否双眼被检测到
- if (leftEye.x >= 0 && rightEye.x >= 0) {
- ...
- }
人脸和双眼已经检测到了,我们将要进行下面的组合预处理:
1、 几何变换和修剪 :这个处理包括尺度,旋转和转换图像,这样眼睛在水平位置。接下来从人脸图像中移除前额,下巴,耳朵和背景。2、分别对左区域和右区域进行直方图化:这个过程单独地对左区域和右区域的亮度和对比度进行标准化。(左区域即左半脸,右区域即右半脸)
3、 平滑 :用一个双边滤波器减少图像中的噪声。4、椭圆掩码:椭圆形的掩码用来从人脸图像中去掉一些仍然存在的头发和背景。
下面的照片展示了应用到了人脸检测脸的预处理的步骤1到步骤4。注意最终的图像在人脸的两边有好的亮度和对比度,然而原始图像没有。
几何变换
人脸对齐很重要,否则人脸识别算法可能用鼻子部分和人眼部分进行比较,等等。人脸检测的输出,仅仅在某种程度上看起来给出了对齐的人脸,但是它并不准确。(也就是说,人脸矩形不总是从前额上的同一点开始)。
(关于本部分的理解可以参考我写的:人脸识别之人眼定位、人脸矫正、人脸尺寸标准化(2):http://blog.csdn.net/raby_gyl/article/details/12312745)
为了得到更好的对齐,我们使用人眼检测来对齐人脸,这样两个检测到的人眼位置在想到的的位置完美的排列。我们使用warpAffine()函数来做几何变换,一个简单的操作将做四个事情:
1、旋转人脸,以便两个人眼在同一水平位置。
2、尺度化人脸,以便两个眼睛的距离总是一样
3、转换人脸,以便眼睛总是水平居中并且在想要的高度上。
4、切掉脸的外部分,因为我们想切掉图像的背景,头发,前额,耳朵和下巴。
仿射变换需要一个仿射矩阵,这个矩阵转换两个检测的人眼位置到两个想要的人眼位置,然后修剪到一个想要的大小和位置。为了产生这个仿射矩阵,我们需要得到两个眼睛的为中心位置,计算两个检测到的眼睛显示的角度,并且看看他们的之间距离,如下:
- // 获取两个人眼连线的中心位置.
- Point2f eyesCenter;
- eyesCenter.x = (leftEye.x + rightEye.x) * 0.5f;
- eyesCenter.y = (leftEye.y + rightEye.y) * 0.5f;
- // 获取两个人眼之间的角度
- double dy = (rightEye.y - leftEye.y);
- double dx = (rightEye.x - leftEye.x);
- double len = sqrt(dx*dx + dy*dy);
- //转换弧度到角度
- double angle = atan2(dy, dx) * 180.0/CV_PI;
- //手测量表面左眼中心理想地应当在尺度化人脸图像的(0.16,0.14)的比例位置
- const double DESIRED_LEFT_EYE_X = 0.16;
- const double DESIRED_RIGHT_EYE_X = (1.0f – 0.16);
- // 得到尺度化的量,使用这些量,我们尺度化到我们想要的固定大小
- const int DESIRED_FACE_WIDTH = 70;
- const int DESIRED_FACE_HEIGHT = 70;
- double desiredLen = (DESIRED_RIGHT_EYE_X – 0.16);
- double scale = desiredLen * DESIRED_FACE_WIDTH / len;
现在我们可以在一个理想的人脸上转换人脸(旋转,尺度,转换)来使两个检测到的人眼到一个想要的位置。
- // 为想要的角度和大小得到一个转换矩阵
- Mat rot_mat = getRotationMatrix2D(eyesCenter, angle, scale);
- //移动人眼中心到一个想要的中心
- double ex = DESIRED_FACE_WIDTH * 0.5f - eyesCenter.x;
- double ey = DESIRED_FACE_HEIGHT * DESIRED_LEFT_EYE_Y – eyesCenter.y;
- rot_mat.at<double>(0, 2) += ex;
- rot_mat.at<double>(1, 2) += ey;
- //转换人脸图像到一个想要的角度,大小和位置。同时用默认的灰度值清除原来的背景图像
- Mat warped = Mat(DESIRED_FACE_HEIGHT, DESIRED_FACE_WIDTH,CV_8U, Scalar(128));
- warpAffine(gray, warped, rot_mat, warped.size());
为左侧和右侧进行单独地直方图均衡化
在现实生活的环境中,脸的一半具有强的光线另外一半具有弱的光线是非常普遍的。这在人脸识别算法中有巨大的影响,因为同一个人脸的左手边和右手边将看起来像截然不同的人。因此我们将左半脸和有半脸进行单独地直方图均衡化,以使得人脸的每个边都标准化亮度和对比度。
如果我们简单地在左半部分应用直方图均衡化,然后应用到右边,我们会看到在中间有一个很明显的边界,因为平均的亮度在左边和右边可能不同,因此为了移除边界,我们将应用两个直方图均衡化,逐渐地从左手边或者右手边朝向中心。用一个全部的人脸直方图来混合。因此,远离 左手边将使用左直方图均衡化,远离右手边将使用右直方图均衡化,并且中心使用一个平滑的左右值的和整脸均衡值的混合值。(具体参考下面代码即可理解)
下面的图像展示了左均衡化,整均衡化和右均衡化图像是怎样混合在一起的:

为了进行这些,我们需要拷贝整个人脸均衡化,类似于左半部分均衡化和右半部分均衡化,如下做法:
- int w = faceImg.cols;
- int h = faceImg.rows;
- Mat wholeFace;
- equalizeHist(faceImg, wholeFace);
- int midX = w/2;
- Mat leftSide = faceImg(Rect(0,0, midX,h));
- Mat rightSide = faceImg(Rect(midX,0, w-midX,h));
- equalizeHist(leftSide, leftSide);
- equalizeHist(rightSide, rightSide);
现在我们混合三个图像到一起。因为图像小,我们可以直接使用image.at<uchar>(y,x)函数访问像素,即使它慢。因此通过直接访问三个输入图像和输出图像,将三个输入图像混合,如下:
- for (int y=0; y<h; y++) {
- for (int x=0; x<w; x++) {
- int v;
- if (x < w/4) {
- //左侧25%:仅使用左脸
- v = leftSide.at<uchar>(y,x);
- }
- else if (x < w*2/4) {
- //中-左25%:混合左脸和整个人脸
- int lv = leftSide.at<uchar>(y,x);
- int wv = wholeFace.at<uchar>(y,x);
- // 混合更多的整个人脸,因为它移动远离右侧脸
- // further right along the face.
- float f = (x - w*1/4) / (float)(w/4);
- v = cvRound((1.0f - f) * lv + (f) * wv);
- }
- else if (x < w*3/4) {
- // Mid-right 25%: blend right face & whole face.
- int rv = rightSide.at<uchar>(y,x-midX);
- int wv = wholeFace.at<uchar>(y,x);
- // Blend more of the right-side face as it moves
- // further right along the face.
- float f = (x - w*2/4) / (float)(w/4);
- v = cvRound((1.0f - f) * wv + (f) * rv);
- }
- else {
- // Right 25%: just use the right face.
- v = rightSide.at<uchar>(y,x-midX);
- }
- faceImg.at<uchar>(y,x) = v;
- }// end x loop
- }//end y loop
单独地直方图均衡化对减少人脸左半边和 右半边不同的光亮的影响很有帮助。但是我们必须理解它没有完全去除一边光照的影响,因为人脸是复杂的3D形状,带有很多阴影。
平滑
为了减少图像噪声的影响,我们对人脸使用双边滤波器,因为双边滤波器善于平滑一幅图像的大部分,同时保持边缘的尖锐。直方图均衡显著地增加了噪声,因此我们用sigmaColor为20来覆盖更多的噪声,但是使用一个只有两个像素的邻域,因为我们想大量的平滑少量的噪声,但不是大的图像区域,如下:(此处应理解双边滤波的原理:建议参考一下:http://blog.csdn.net/bugrunner/article/details/7170471 理解讲解的很好,很不错 )
- Mat filtered = Mat(warped.size(), CV_8U);
- bilateralFilter(warped, filtered, 0, 20.0, 2.0);
椭圆形掩码
尽管当我们在做几何变换时,我们已经去掉了大部分的图像背景和前额,头发。我们可以使用一个椭圆形的掩码去掉一些角的区域例如脖子,在人脸上他们可能处于阴影区域,尤其如果脸没有完全直视相机。为了创建掩码,我们画一个黑色的填充椭圆在一个白色图像中。这个椭圆有一个0.5的水平半径(也就是说,它完全覆盖了人脸的宽度),一个0.8的垂直半径(因为人脸通常是高比宽大),中心定位在0.5,0.4,如下图展示,这里椭圆形的掩码从人脸上去掉了一些不需要的角。

我们应用掩码时,调用cv::setTo()函数,该函数通常设置整个图像为某一个像素值。但是当我们给一个掩码图像时,它只把某些部分设置为给定的像素。我们将用灰色填充图像,因此与人脸的剩余部分相比它应当有小的对比度。
- //在图像的中心画一用黑色填充的椭圆
- //首先我们初始化掩码图像到白色(255)
- Mat mask = Mat(warped.size(), CV_8UC1, Scalar(255));
- double dw = DESIRED_FACE_WIDTH;
- double dh = DESIRED_FACE_HEIGHT;
- Point faceCenter = Point( cvRound(dw * 0.5),
- cvRound(dh * 0.4) );
- Size size = Size( cvRound(dw * 0.5), cvRound(dh * 0.8) );
- ellipse(mask, faceCenter, size, 0, 0, 360, Scalar(0), CV_FILLED);
- //对人脸应用掩码,去掉角
- //设置角到灰度,没有接触到内部脸
- filtered.setTo(Scalar(128), mask);
下面的放大的图像展示了所有人脸处理过程后的样本结果。注意这对于在不同的光照,人脸旋转,相机的角度,背景,灯光位置,等等,有更多的一致性。这个预处理的人脸将用作人脸识别阶段的输入,也用在为训练收集人脸图像的时,和尝试识别输入图像时。
步骤3:收集人脸并且学习他们
收集人脸可以像简单的从相机得到一组预处理过的人脸,然后把新的预处理的人脸加入进去。同时把标签放入到一组图像中(指定拍的是哪个人的人脸)。例如你可以使用第一个人的10个预处理的人脸,和第二个人的10个预处理的人脸。因此,输入到人脸识别算法将是一组20个预处理过的人脸并且一组20个整数(这里前10个是0,后10个为1)。
人脸识别算法将要学习怎样区分不同人的人脸。这称作训练阶段,搜集的人脸称为训练集。人脸识别算法完成训练之后,你可以保存产生的知识到一个文件或者存储器,并且过会使用它去识别在相机前面的这个人是谁。这称作测试阶段。如果你直接使用相机输入,那么预处理的人脸被称为测试图像,如果你测试很多图像(例如从一个图像文件夹),它将被称作一个测试集。
你提供一个好的训练集是很重要的,该训练集涉及到你期望发生在测试集的各种类型。例如,你只需要完全直视前方的人脸(例如ID 照片),那么你只需要提供完全直视前方的人脸训练图像。但是,如果这个人可能正在看左边或者上边,那么你应当确保训练集也要包括做这个动作的人脸。否则人脸识别算法在识别他们时困扰,因为他们的人脸表现的相当不同。这同样也应用与其他因素,例如面部表情(例如,如果一个人在训练集中一直保持微笑,但是在测试集中不微笑)或者光线情况下(例如,在训练集中左手边人脸有一个强的光照,但是在训练集中右手边人脸是一个强的光照),那么人脸识别算法在识别他们时变的困难。我们刚刚看到的人脸识别处理阶段可以帮助我们减少这些问题,但是它当然不能去掉这些因素。特别地人脸直视的方向,因为它对人脸上的所有元素的位置有很大的影响。
注释:
1、获得一个好的训练集的一种方式是覆盖许多不同的现实生活的情况,针对每一个人,旋转他们的头从看左边,上,下,然后直视。接着这个人倾斜他们的头到一边并且接着抬头和低头,同时也改变他们的面部表情,例如在微笑,生气,中性人脸中交替变换。如果每个人在搜集人脸时按照这样的程序,那么在现实生活的环境下,将有更好的可能性识别每一个人。
2、对于甚至更好的结果,应当再进行一次或者更多次位置,方向。例如通过180度的旋转相机并且与相机相反的方向行走,那么重复整个过程,因此训练集将包括许多不同的光照情况。
因此总的来说,对于每一个人有100个训练人脸可能比仅有10个训练人脸得到更好的结果。但是如果100个人脸总是相同的,那么它任然执行不好,因为训练集中涉及到测试集中充分的多样性是很重要的,而不仅仅是有大量数据的人脸。因此为了确保训练集中的所有人脸不太相似,我们在每一个搜集的人脸中间夹一个显著的延时。例如,如果摄像头每秒30帧,那么仅几秒钟就可以搜集100张人脸,同时人并没有时间周围移动。因此最好每秒钟仅搜集一个人脸,同时向周围移动人脸。另外一个简单的方法是提高训练集中变化,只搜集看起来与先前搜集的人脸不同的人脸。
为训练收集预处理人脸
为了确保在搜集新人脸的时间间隔至少1秒。我们需要计算已经过去了多长时间,做法如下:
- // 检测从前一个脸被添加到现在花了多长时间
- double current_time = (double)getTickCount();
- double timeDiff_seconds = (current_time –old_time) / getTickFrequency();
为了一个像素一个像素的比较两个图像的相似性,你可以找到L2相关误差,这仅仅包括从另外一幅图像中剪切一幅图像,加上它的平方值,然后获取它的开方。因此如果一个人一点都不移动,当前人脸减去先前人脸的每一个像素的差值将非常小,但是如果这些像素仅仅沿任意方向轻微移动,图像的差值将很大,因此L2误差将很高。因为结果是所有像素的和,这个值将依赖于图像的分辨率。因此为了获取均值误差,我们将该值除以图像中像素的总数。我们用一个便利的函数实现它,getSimilarity(),如下:
- double getSimilarity(const Mat A, const Mat B) {
- // 计算两个图像的L2相关误差
- double errorL2 = norm(A, B, CV_L2);
- //尺度化该值,因为L2是通过所有像素得到的和
- double similarity = errorL2 / (double)(A.rows * A.cols);
- return similarity;
- }
- ...
- //检测现在人脸是否和先前人脸不同
- double imageDiff = MAX_DBL;
- if (old_prepreprocessedFaceprepreprocessedFace.data) {
- imageDiff = getSimilarity(preprocessedFace,old_prepreprocessedFace);
- }
如果一幅图像不移动,这个相似性低于0.2,如果图像移动,相似性高于0.4。我们用0.3作为收集一张新人脸的阈值。
我们有很多方法来获取更多的训练数据,例如使用镜像人脸,增加随机噪声,小像素的移动人脸,百分比的尺度化人脸,或者一个小角度的旋转人脸。(即使在预处理人脸时,我们专门的尝试去掉这些影响)。让我们增加镜像人脸到训练集,因此我们有双倍的,一个更大的训练集,同样减少了非对称人脸的问题。或者在训练时如果一个用户经常轻微地朝向左,右。做法如下:
- //只处理与前一帧有显著不同的人脸,必须有显著的时间间隔
- if ((imageDiff > 0.3) && (timeDiff_seconds > 1.0)) {
- // 并且增加镜像图像到训练集
- Mat mirroredFace;
- flip(preprocessedFace, mirroredFace, 1);
- // 增加人脸和镜像人脸到检测的人脸列表Add
- preprocessedFaces.push_back(preprocessedFace);
- preprocessedFaces.push_back(mirroredFace);
- faceLabels.push_back(m_selectedPerson);
- faceLabels.push_back(m_selectedPerson);
- // 保存处理的人脸副本,用来与下一次迭代进行比较
- old_prepreprocessedFace = preprocessedFace;
- old_time = current_time;
- }
将预处理的人脸和标签或者人的ID号收集到preprocessedFaces和faceLabels容器中。(假定ID号存储在整形的m_selectedPerson变量中)
为了使我们添加现在的脸到集合中更显眼,通过在整个图像上显示一个巨大的白色的矩形框或者仅仅在短时间内显示他们的人脸来提供一个视觉的通知,让他们意识到照片已经拍照了。采用OpenCV的c++接口,你可以使用重载的cv::Mat加号操作符来对图像中的每一个像素增加一个值,使其修剪到255(使用saturate_case,因此它不会溢出,再从白色到黑色!)假定displayedFrame将是彩色相机帧的将要显示的一个副本,将其加入到为人脸采集的预处理之后:
- // 获取感兴趣的人脸区域
- Mat displayedFaceRegion = displayedFrame(faceRect);
- // 为人脸区域的像素增加一些亮度
- displayedFaceRegion += CV_RGB(90,90,90);
后面内容请关注:
第八章 采用PCA(主成分分析)或LDA(线性判别分析)的人脸识别(二):http://blog.csdn.net/raby_gyl/article/details/12623539