MongoDB分页处理方案
MongoDB的分页性能是广大使用者所诟病的大问题之一,在大数据量环境下,如果一次跳转的页数过多,如10W多页,可能用户要等上几十秒(瞎掰的数据),有兴趣的可以去看一下这篇文章Paging& Ranking With Large Offsets: MongoDB vs Redis vsPostgreSQL。
看完了你是不是对MongoDB的性能很失望,对Redis充满了崇敬?
其实这种对比是完全不公平的。
首先,看一下Redis,研究NoSQL的多少会了解一些吧,这是一种完全的内存缓存的存储系统,他完全称不上是个数据库,为什么这么说呢,因为数据库最基本的一个特征——持久化Redis是没有的。Redis和Memcached一样,是一种将数据全部放在内存中用于缓存的存储系统,因此它的性能就是内存的性能。
而MongoDB,乃至其他一切数据库,都会将数据存入硬盘,虽然MongoDB也会将部分热数据放入内存,但是面对千万级甚至上亿的数据量,让内存放下所有热数据是不可能的,所以如果一个查询匹配的数据过多的话,可能大部分的性能瓶颈都在页面交换(从硬盘上读数据)上了。
最后,你可以测一下关系型数据库的性能,相信很难有哪个关系型数据库的分页性能比MongoDB还好。
当然,这不是为MongoDB开脱,我认为10gen应该找到一些办法来优化一下这种分页之后大偏移量的性能严重下降问题,虽然我还没想到。
数据库性能瓶颈分析
出现这一现象的原因,在于用户的这种查询需要数据库根据条件做一次筛选或排序,这是非常耗时间的,比如:
db.user.find({age:{$gt:20, $lt:30}}).sort({registdate:1,name:-1})
你如果在Google的用户数据中(据说是亿级)进行了这种查询,假设这些数据使用MongoDB(实际应该是BigTable)存储的,匹配了上亿的数据量,这个过程,MongoDB需要一个compound index,类似于{age:1, registdate:1, name:-1}这种,首先要根据age过滤出符合{age:{$gt:20,$lt:30}}的数据,然后根据两个条件{ registdate:1, name:-1}进行排序,这个排序很可能会与原来的索引顺序不同,因此MongoDB需要花时间来进行这种排序操作,更重要的是基于内存大小的限制,这种排序的结果不可能用于存储在内存中,甚至不会记录而是每次都排序一遍(这是很正常的),如果你查询的是前一百条的数据还好,MongoDB也许只需要排序数百条数据就能返回排序好的前一百。
举个例子,减小一下数据规模,如下图:

MongoDB由两个Shard组成,user这个Collection有{age:1, registdate:1, name:-1}的索引,假设查询前三条数据,即
db.user.find({age:{$gt:20, $lt:30}}).sort({registdate:1,name:-1}).limit(3)
那么,最理想情况下(因为我不太清楚MongoDB的查询机制),MongoDB只需要查找三步就可以返回结果。如下图(前面的序号可以理解为指针跳转序号):

如果用户进行了跳转,如:
db.user.find({age:{$gt:20, $lt:30}}).sort({registdate:1,name:-1}).skip(3),limit(2)
那么MongoDB必须把前5条排序完才能给用户返回第4-5条。如下图(前面的序号可以理解为指针跳转序号):
s
Google实例
首先看一下Google老大哥是怎么做到的。
关键词为:nba
这是搜索到的结果数:
![]()
以及导航翻页栏:

手动点了一下翻页,速度还挺快的,不过这只不过是1000条数据以内的翻页,没有任何参考意义,于是我不停的往后翻,直到:
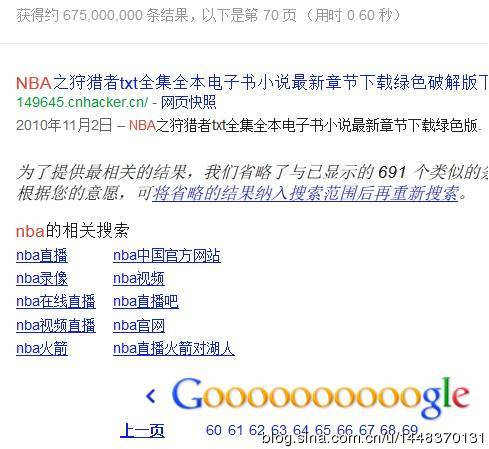
嗯,这个令我顿时语塞……
只能翻到70页,之后的全被Cut掉了。不信的可以自己试试,基本不会让你翻超过80页。而且注意关于搜索结果数:
获得约:675,000,000,000条结果……
Google用了个“约”字,数据库中肯定不会是这个值。
综上,Google关于分页的处理方法是,采用一定的方法获取匹配到的结果的大概值,这种方法类似于:只匹配重要度排名靠前的部分数据,然后根据这部分所占比例估算出总匹配结果数。在数据呈现时也只显示700条左右的数据,因为用户基本不会翻那么多页。
针对翻页需求的分析
在解决翻页问题之前,必须首先解决一些问题:
问题1:翻页功能有必要么?
是的,一般来说是很有必要的。
问题2:翻几十页的功能也必要么?
嗯,也许有些情况下是需要的。
问题3:翻几百页的功能真的有必要么?
这个,真的很难想出相应的需求来。
需求:有人会提出需求说,我公司有上千万的物品信息,我要查找的物品正好在第1W页,所以我要求有能够一次翻1W页的功能。
解决办法:这真的是一个要求翻页功能的需求么?客户是如何在未一页一页翻页的情况下就知道该物品在信息系统的第1W页的,一定有物品的相应属性信息约束了它必定会出现在第1W页,比如ID信息,其ID自增,并且该物品ID为100002,信息系统每页显示10件物品的话,升序情况下,该物品会出现在第1W页。我们不一定会知道那么详细,但一定会有个大概的信息,例如ID是10000X,就可以用ID > 100000&& ID <100010来快速查找到。
综上,解决这种需求的方法是,告诉客户,我有更好的方法为您找到这件物品,那就是用查询代替翻页。
很多情况下的需求都要经过这种转变,如果客户要你做什么你就做什么,那你就不是产品经理了,而只是传话筒罢了。Google之所以敢只提供给用户700条的数据会是因为他的数据量不够么?当然不是,这是一种性能与客户体验的折中方案,一般来说,用户在搜索结果的前10页就能解决自己想要的问题。即使没找到,Google认为翻到70页还没找到结果就应该修改或者更换关键词再次搜索了。
解决方案
下面我们来处理些实际的,不再耍嘴皮子了。
方案1:类Google式性能与用户体验折中
注:Google的处理方案肯定不是这样,而是采用类似分布式计算的方式,我只是以呈现给用户的方式来定义本种方案的。
首先,要保证用户查询的排序条件一定要有索引,然后:
db.test.find({“context”:”nba”}).sort({“date”:-1}).limit(1000)
只查询前1000条数据
1)如果返回的结果数<1000,那么直接呈现给用户。
2)否则根据最后一条数据的排序条件的数据信息进行分析,得到估算值。以本例来说,假设返回的最后一条数据的日期是lastDate = “2012-11-0508:00:00”,而你的数据库中存储的数据是从originDate = “2010-01-0108:00:00”至今的,当前时间(数据库中最新的数据时间)是nowDate = “2012-11-0618:00:00”,那么:

这只是粗略的一个公式,例中数据在时间上是基本均匀分布的,实际应用中可能不是这样,比如按年龄排序,数据库中存储的用户数据是中间多两边少的情况就需要调整这一公式,为每一年龄段的用户数据量加上一定的权重再计算。
针对此种情况举一例:
| 年龄段 |
用户比例 |
| 0~10 |
0% |
| 10~20 |
6.4% |
| 20~30 |
29.1% |
| 30~40 |
46.9% |
| 40~50 |
14.7% |
| 50~60 |
2.9% |
| 60+ |
0% |
你的网站中有如上的用户构成,然后进行了一次按用户年龄排序的查询:
db.user.find({“name”:/立/,”age”:{“$gt”:18}}).sort({age:1}).limit(1000)
查询出最后一条数据的年龄为21,那么可以粗略算出匹配到的数目约为:
在内存中进行如此简单的数学公式计算可要比遍历约24倍的数据快多了。
方案2:限定翻页的页数
上面这种方案过于讨巧,本方案完全实现了全部数据的翻页,方法的精髓在于:
不要让用户一次进行20页以上的翻页操作。
这个20页不是固定的,可以根据性能进行调整。进行这种限定的原因在于:在知道当前用户正在查看的数据的前提下,向后进行一定数量的翻页其性能是可控的。举个栗子:
db.test.find().sort(date:-1).limit(200)
在date有索引的前提下,这个查询是相当快的,因为数据是已经排好序的,指针只需要遍历前200条(或后200)就可以返回结果。再看下面的查询语句:
db.test.find({“date”:{“$lt”1352194000:}}).sort(date:-1).limit(200)
注:date的数据存储格式为时间戳,单位为秒
这条查询依然很快,因为指针会在date的索引数上定位1352194000这条数据所在位置,然后顺序读200条数据即可,与前面的查询相比性能差不多。
下面说一下实际操作的方法:
首先,屏蔽掉支持用户手动指定翻页页数的功能,当用户目前处在第15页时,导航条只显示最多前后20页的导航栏(其实10页就足够了,如baidu)。
然后你必须能够获取本页最后一条数据的相应排序条件的数据信息,比如查询是以ID排序的,就需要知道本页最后一条数据的ID值,设为queryID。
假设每页显示20条,用户翻到24页,那么执行:
db.test.find({ID:{$gt:queryID}}).sort({ID:1}).limit(180)
取最后的20条就可以了。
此外,可以为导航栏加上“向前20页”、“向后20页”这样的功能,是完全没有问题的。还有“首页”“末页”也是可以实现的。
方案3:以空间换取时间
简单说就是将查询到的相关信息缓存起来,当然,缓存也有两种不同的方式:
1. 缓存全部查询到的信息。这个视每次查询到的数据量大小以及你的服务器内存大小而定,不行的话就用第二种方式。
2. 缓存关键索引信息。主要是用户用于排序的字段。
这里讲一下第二种方式,再举例:
例一:
以ID为唯一索引的表为例,用户查询后也是按照ID进行排序的,不提供其他排序方式,那么可以采用每10个ID缓存一次的数据结构进行存储,采取10的原因是一般每页显示数量为10,20或50比较常见。如果采用的是键值对方式的缓存方案,如MemberCached或Redis,可以存储为:
| key |
value |
| 4X0001 |
1 |
| 4X0011 |
2 |
| 4X0021 |
3 |
| 4X0031 |
4 |
| …… |
…… |
前面的ID即是要查询的数据表的主键ID,value为分页用的页码/序号,比如Redis中有一种带权值的ZSET数据结构,查询任何一页的性能都为常数复杂度。
时间:缓存响应时间(常数)+数据库响应时间(常数)。
空间:设ID为64位,数据量在200亿以内,则需缓存n * (64 + 32) / 10位大小,大约为n * 1.2 Byte。一个亿也就是120MB的占用。
例二:
可排序字段有:价格(price)、数量(num)、时间(date)。另外若出现排序字段值相同,则按ID进行排序。
每种排序都需要存储为一个数据结构,以价格为例,key为[price]:[ID],value仍为翻页用的页数:
| key |
value |
| 1:4X0219 |
1 |
| 1:4X9555 |
2 |
| 3:4X1500 |
3 |
| 6:4X3038 |
4 |
| …… |
…… |
数量和时间也以这种方式进行存储。
时间:缓存响应时间(常数)+数据库响应时间(常数)。
空间:总体和例一计算方式一样,因为多了前缀,所以每个数据结构要大1/3到2/3,要排序的字段越多,需要存储的数据结构也就越多。理想情况下,一亿数据量3字段排序需要480MB左右。