2011hadoop技术大会实时数据分析
facebook在这次大会上谈了facebook的进展。他们以前架构是
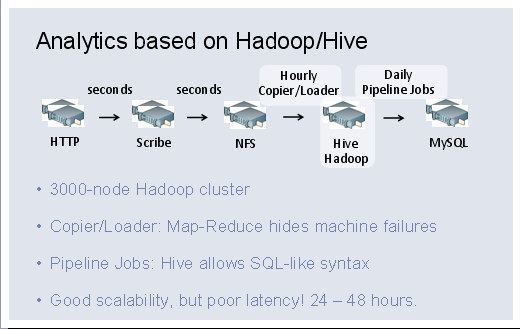
applicationserver 将日志近乎实时的通过facebook自己的流传送工具scribe,传送到nfs。然后通过一个copyier或者loader(这里考虑应该是使用hive的load 到hive内表中)每小时载入hive/hadoop,r然后通过每天的pipeline jobs 运行任务 将结果存入mysql。
这个架构使用scribe保证了日志的流传送;使用mapreduce运算job,隐藏了单一节点的失败,增强了容错性。通过hive简化mapreduce分析,也具有非常好的系统伸缩性。但是延迟比较严重。mapreduce本身还是倾向于批量job的运行,而非实时job运行!
结合目前部门的架构,部门内也是借鉴facebook,使用其scribe来传送数据。和facebook不同的是,scribe经过数级转接后直接通过末端的scribe入hdfs。然后使用dip-data-analyze 调度任务运行。这样的架构可以满足 批量job,但是实时性不好。为了支持一些比较实时的计算,目前是暂时通过分钟任务运行,也算一种无奈吧。
facebook ppt中一句话 对于实时性德建议:
We got 2 ideas on how to improve the latency.
The first one is small-batch processing. Instead of using a batch of 1 day, we can produce much smaller batches. The question is how to reduce per-batch overhead, so that tiny batches like 1 min or less makes sense.
The second one is stream processing. We can aggregate the data as soon as it arrives. This will produce near realtime results. The question is how to make the system reliable against hardware failures.
It turns out the per-batch overhead of Map-Reduce is so high that it’s not practical to have even 5-minute batches on our Hadoop cluster, so we finally decided to go stream processing.
目前他们在研发 Data Freeway 和 Puma
Data Freeway, is a scalable data stream framework on top of Scribe and HDFS.
Puma, is a reliable stream aggregation engine on top of HBase.
需要深入研究。再是 ali的iprocess也需要关注下。阿里心在完全走在国内前列,对apache也贡献了不少东东。很赞!
----------------------------------------------------------------------------------
继续ppt的内容。
facebook以前的架构:
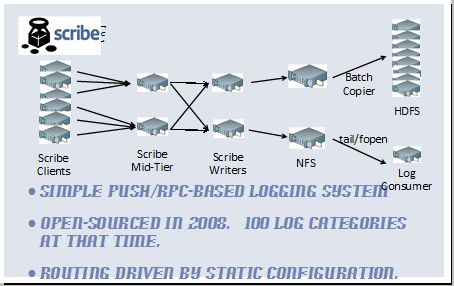
上面架构包含几个layer,负责数据转发。第一层为应用客户端到scribe中间层,将日志来源从成千上万的应用端减少到几百个scribe中继。第二层从scribe中继到scribe写入层,这一层主要做基于category的数据shuffle,可以保证每个category由一个writer来写。 然后写入nfs,可通过 批量copier写入hdfs,或者通过tail等linux工具 喂给 logconsumer。
这个架构的缺陷是 每个category只有一个writer写 存在单点故障。伸缩性不好,必须为每个writer管理一个配置,不可扩展。
优点是 采用push/rpc 机制,效率高,简单,当时(08年)支持100 categories
2011年的新架构 :
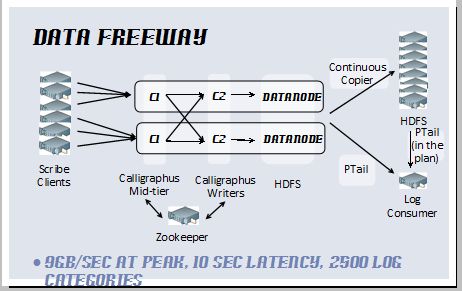
data freeway可以支持高峰时9g/s的传送速度,端到端延迟仅为10s,正支撑2500categories.架构包含4个组件:
1 scribe,只存在于应用端,保证数据通过rpc将数据转发出去。
2 Calligraphus(查不到这个单词,facebook自己造的)。通过zk保证category选择,洗牌,并写入hdfs。
3 Continuous Copier,持续的从hdfs发现文件增长,将数据copy到其他集群或其他存储。
4 PTail 并行从hdfs tail多个目录,并写入标准输出。这样就可以通过ptail来处理Calligraphus写入hdfs的数据。这里facebook提到未来会tail 通过Continuous Copier写入的hdfs数据
下面详细讲下 重要组件:
Calligraphus :最终要特色是 提供bucket支持。scribe端可以基于应用做桶的划分,所以这里可以支持这个桶。同时后端也可以支持sharded log consumer,这样可以分散数据流。
支持基于桶的基础架构,这个可以支撑 一个应用从每秒 字节级到 g级的数据增长。每个桶表现为一个目录,所以大的数据流会同时被分散到多个目录中。
Calligraphus 有非常好的性能表现。7秒文件系统同步点 是现在最大的延迟来源。网络吞吐量可以非常容易的堵塞1g的NIC(暂时理解为带宽吧)。他们计划采用10g的带宽。
Continuous Copier :设计为持续从一个文件系统到另一个文件系统。和基于mapreduce的批量copy,这个具有更加好低延迟性和平滑性。现在这个是通过一个持续运行的map-only job来实现,可以很容易的迁移到 任何一个简单的job调度系统,而不通过mapreduce。因为mapreduce启动延迟就已经很高了。目前该组件通过在很多datanode中使用锁文件来协调控制,以后会通过zookeeper来控制。
现在在生产环境,Continuous Copier 高峰速度为 3g/s,数据已经被压缩。
ptail: 从一个文件系统到一个输出流。它的关键特性是提供了checkpoint。每个checkpoint包含了当前的文件和每个路径下这些文件的偏移值。这可以保证ptail可以很容易的回滚到上一个checkpiont,从而可以保证数据无丢失,不重复。
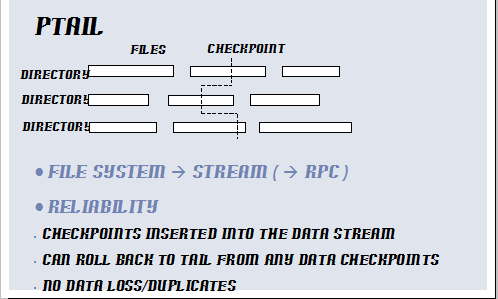
上面是对facebook的整个新架构组件的详细介绍,下面facebook谈了一些 性能 对比图
rpc push数据 和从fs拉数据的性能对比。
Data Freeway consists of 4 components that allows data transfer between these 2 channels.
下一个是 Puma。负责实时的aggregation/storage(聚合/存储)。等待持续更新。。。。