DataNode节点的数据块管理(3)——FSVolumeSet、FSVolume
在分布式文件系统HDFS中,DataNode节点被用来存储文件的数据,确切的来说就是HDFS中的每一个文件是分块来存储的,一个文件可能有多个数据块,每一个数据块有多个副本,而且数据块的不同副本存储在不同的DataNode节点上,所以如果把整个HDFS集群看做一台机器的话,那么每一个DataNode节点就可以看做是一块存储磁盘。实际上,HDFS也正是这么干的。前面说过,每一个DataNode节点我们都可以为它配置多个本地存储路径,如果把这些
本地存储路径统一看做一块磁盘的话,那每个存储路径就可以看做是这个磁盘上的一个分区。HDFS设计了FSVolumeSet类来表示磁盘,FSVolume类来表示分区,这两个类都是作为
org.apache.hadoop.hdfs.server.datanode.FSDataset的内部类而只能被FSDataset类引用。
先来仔细的看看这两个类的基本信息:
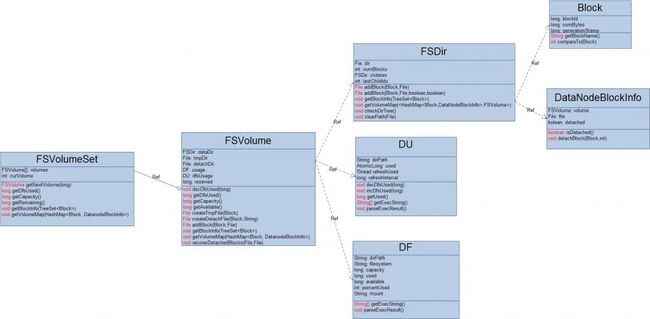
1.FSVolume
private FSDir dataDir; //存储有效的数据块的最终位置(current/) private File tmpDir; //存储数据块的中间位置(tmp/) private File detachDir; //存储数据块的copy on write(detach/) private DF usage; //获取当前存储目录的空间使用信息 private DU dfsUsage; //获取当前存储目录所在的磁盘分区空间信息 private long reserved; //预留存储空间大小DataNode节点配置的每一个存储路径最终被抽象成了一个FSVolume对象,它主要负责为数据块分配存储空间,并且定期的更新这个“分区”的空间使用信息,为了统计的准确性,它使用了DF、DU类。处于一致性的考虑,当有一个数据块达到DataNode节点时,就需要为这个数据块分配存储空间,但是FSVolume并不是马上就在它的最终存储位置上为它创建一个对应的存储文件,而是在“分区”的 tmpDir(对应存储路径下的tmp/目录)中为它建立一个临时文件,当成功接收这个数据块并写入这个临时文件之后,再把这个临时文件移动到真正存储这个数据块的位置下面。当我们为DataNode节点的数据进行备份/升级 时,DataNode节点会把每个"分区"中current/下的所有数据块移动到previous/下面,然后 为了提高会在 current/建立每一个文件的硬链接,它们分别指向 previous/下的对应文件。那么当我们对某一个数据块进行更新的时候(因为HDFS不支持随机写,所以这里的更新主要是指追加操作),就需要对相应的数据块文件进行detach操作(至于这一操作的原因,我在前面详细提到过):先将这个数据块对应文件(物理位置在 previous/下)复制到detach/下,然后用这个副本代替数据块在 current/下的硬链接。上面的两个操作( 分配存储空间、数据块detach)可以近似看作是采用了两段提交协议,因此每一个“分区”在初始化的时候都进行了恢复操作,它会尽量恢复可能由于DataNode所在节点宕机而造成影响。这个恢复操作是:
1).对于detach/下的所有数据块文件(detach/下不存在目录,只有文件),如果该文件在current/下不存在,则把它移动到current/下,最后清空detach/目录
2).如果DataNode节点被设置为支持append操作(对应的配置项为dfs.support.apend),那么对于tmp/下的所有数据块文件(tmp/下不存在目录,只有文件),如果该文件在current/下不存在,则把它移动到current/下,最后清空tmp/目录;否则清空tmp/目录。
笔者认为,这里的恢复操作,在Hadoop-0.20.0版本中有点问题或者是实现的有点牵强(大家可以详细的参考我贴出来的代码)。哦,对了,差点忘了“分区”的空间预留值reserved,它可以通过配置文件中的dfs.datanode.du.reserved项来配置。
FSVolume的启动恢复操作:
this.detachDir = new File(parent, "detach");
if (detachDir.exists()) {
recoverDetachedBlocks(currentDir, detachDir);
}
this.tmpDir = new File(parent, "tmp");
if (tmpDir.exists()) {
if (supportAppends) {
recoverDetachedBlocks(currentDir, tmpDir);
} else {
LOG.debug("clear directory: "+ tmpDir.getAbsolutePath());
FileUtil.fullyDelete(tmpDir);
}
}
...
private void recoverDetachedBlocks(File dataDir, File dir) throws IOException {
File contents[] = dir.listFiles();
if (contents == null) {
return;
}
for (int i = 0; i < contents.length; i++) {
if (!contents[i].isFile()) {
throw new IOException ("Found " + contents[i] + " in " + dir + " but it is not a file.");
}
// If the original block file still exists, then no recovery is needed.
File blk = new File(dataDir, contents[i].getName());
if (!blk.exists()) {
LOG.debug("try to move file["+contents[i].getAbsolutePath()+"] to file["+blk.getAbsolutePath()+"]");
if (!contents[i].renameTo(blk)) {
throw new IOException("Unable to recover detached file " + contents[i]);
}
continue;
}
LOG.debug("try to delete file["+contents[i].getAbsolutePath()+"]");
if (!contents[i].delete()) {
throw new IOException("Unable to cleanup detached file " + contents[i]);
}
}
}
FSVolume中的重要方法:
/*获取分区的存储空间容量,考虑预留值*/
long getCapacity() throws IOException {
if (reserved > usage.getCapacity()) {
return 0;
}
return usage.getCapacity()-reserved;
}
/*获取分区的可用空间*/
long getAvailable() throws IOException {
long remaining = getCapacity()-getDfsUsed();
long available = usage.getAvailable();
if (remaining>available) {
remaining = available;
}
return (remaining > 0) ? remaining : 0;
}
File createTmpFile(Block b) throws IOException {
File f = new File(tmpDir, b.getBlockName());
return createTmpFile(b, f);
}
File createDetachFile(Block b, String filename) throws IOException {
File f = new File(detachDir, filename);
return createTmpFile(b, f);
}
private File createTmpFile(Block b, File f) throws IOException {
if (f.exists()) {
throw new IOException("Unexpected problem in creating temporary file for "+ b + ". File " + f + " should not be present, but is.");
}
// Create the zero-length temp file
//
boolean fileCreated = false;
try {
fileCreated = f.createNewFile();
} catch (IOException ioe) {
throw (IOException)new IOException(DISK_ERROR +f).initCause(ioe);
}
if (!fileCreated) {
throw new IOException("Unexpected problem in creating temporary file for "+
b + ". File " + f + " should be creatable, but is already present.");
}
return f;
}
/*将一个接受成功的数据块写入current/中*/
File addBlock(Block b, File f) throws IOException {
File blockFile = dataDir.addBlock(b, f);
File metaFile = getMetaFile( blockFile , b);
dfsUsage.incDfsUsed(b.getNumBytes()+metaFile.length());
return blockFile;
}
2. FSVolumeSet
DataNode节点配置的每一个存储路径最终被抽象成了一个FSVolume对象,因此,FSVolumeSet对所有的存储路径进行管理,实际上就是对所有的FSVolume对象进行管理。FSVolumeSet主要为上层(DataNode进程)提供存储数据块选择一个的存储路径(分区),说白了就是为该数据块创建一个对应的本地磁盘文件,同时也负载统计它的存储空间的状态信息和收集所有的数据块信息。在FSVolumeSet中唯一需要重点明确的是它如何为一个数据块选择存储路径(分区)。这个过程实际上很简单,它采用循环队列的策略来实现负载均衡(参看它的getNextVolume()方法,一看便知)。
/*为一个数据块选择一个存储分区*/
synchronized FSVolume getNextVolume(long blockSize) throws IOException {
int startVolume = curVolume;
while (true) {
FSVolume volume = volumes[curVolume];
curVolume = (curVolume + 1) % volumes.length;
//检查分区剩余可用空间是否满足数据块的大小
if (volume.getAvailable() > blockSize) { return volume; }
if (curVolume == startVolume) {
throw new DiskOutOfSpaceException("Insufficient space for an additional block");
}
}
}
/*获取磁盘已使用空间*/
long getDfsUsed() throws IOException {
long dfsUsed = 0L;
for (int idx = 0; idx < volumes.length; idx++) {//统计每一个分区的已使用空间
dfsUsed += volumes[idx].getDfsUsed();
}
return dfsUsed;
}
/*获取磁盘的总空间容量*/
synchronized long getCapacity() throws IOException {
long capacity = 0L;
for (int idx = 0; idx < volumes.length; idx++) {//统计每一个分区的空间容量
capacity += volumes[idx].getCapacity();
}
return capacity;
}
/*获取磁盘的剩余空间*/
synchronized long getRemaining() throws IOException {
long remaining = 0L;
for (int idx = 0; idx < volumes.length; idx++) {//统计每一个分区的剩余空间
remaining += volumes[idx].getAvailable();
}
return remaining;
}
/*获取磁盘中所有数据块信息*/
synchronized void getBlockInfo(TreeSet<Block> blockSet) {
for (int idx = 0; idx < volumes.length; idx++) {//统计每一个分区下的所有数据块信息
volumes[idx].getBlockInfo(blockSet);
}
}
/*获取磁盘中所有数据块的分区位置信息*/
synchronized void getVolumeMap(HashMap<Block, DatanodeBlockInfo> volumeMap) {
for (int idx = 0; idx < volumes.length; idx++) {//统计每一个分区下的所有数据块的分区位置信息
volumes[idx].getVolumeMap(volumeMap);
}
}