用Hough投票做物体检测的3篇文献
用Hough投票做物体检测的3篇文献
文献1:Combined Object Categorization and Segmentation with an Implicit Shape Model,ECCV 04 Workshop。
内容简介:用隐形状模型(Implicit Shape Model, ISM)把物体的检测和分割结合起来。
创新点:
-
用隐形状模型把物体的识别和分割结合起来,整合到同一个概率框架下。
-
用基于最小描述长度(Minimal Description Length, MDL)的标准来做多个物体检测问题。
算法细节:
码本:
Harris检测器提取感兴趣点,提取patch,合并相似的patch,将类中心存入码本。
物体识别的过程:
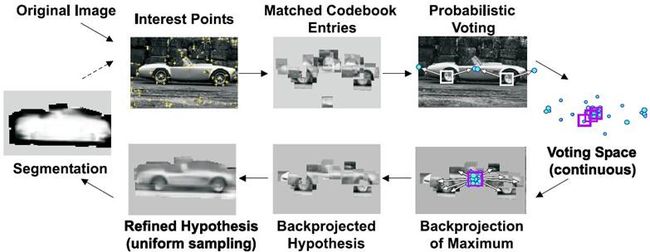
Harris检测器提取感兴趣点——提取patch——与码本匹配——对物体中心投票——得到最大得分——搜集相关patch——提取相关patch附近的patch。
概率形式化:
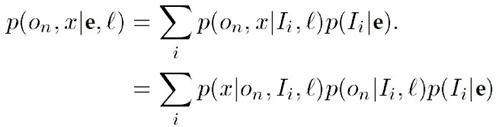
第一项是给定物体类别、patch的解释后,hough投票物体位置的概率;第二项是码本匹配的是物体而不是背景的概率;第三项是patch和码本匹配的概率。
对上式求平均,得到一个中心作为物体的中心的得分为:
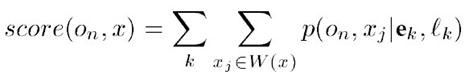
物体分割:
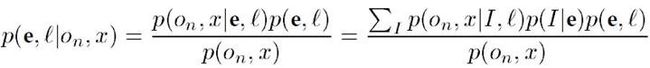
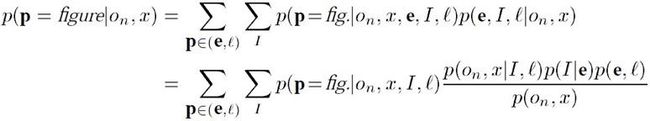
基于最小描述长度的规则做多个物体场景分析:
最小描述长度的规则要求最小化图像、模型和错误的总描述长度。提出savings的概念:
![]()
其中:![]() 指可以被假设h解释的像素个数;
指可以被假设h解释的像素个数;![]() 指描述错误的代价;
指描述错误的代价;![]() 指模型复杂度。
指模型复杂度。
两个假说时:
![]()
_____________________________________________________________________________________
文献2:A Boundary-Fragment-Model for Object Detection,ECCV 06。
内容简介:提出了"Boundary-Fragment-Model"(BFM)检测器,用物体的边界来做检测。流程为:
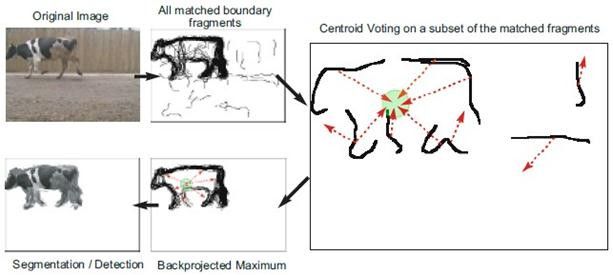
创新点:
学习边界片段码本的方式。片段不但具有较高的类别信息,并且能够稳定的预测物体的中心。
用Boosting方法把一系列基于边缘片段的弱检测器构造成强检测器。有这些检测器,检测物体时不再需要滑动窗对物体定位。
算法细节:
学习边界片段。主要涉及对边界片段打分和选择。需要训练集(已用bounding box划定了物体)和验证集(标注了物体是否存在和物体的中心,但没用bounding box)。
对边界片段打分
候选的边界片段需要满足:(i)匹配的边缘链经常在正例样本而不在负例样本;(ii)能较好的预测正例中的物体中心。根据以上两点对边界片段打分。边界片段的代价函数为:
其中:
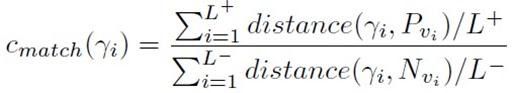
选择边界片段
步骤:在边界片段上随机撒一些种子——让种子在边界片段上生长,并随时计算在验证集的代价![]() ——选择最佳的边界片段,得到码本。码本中有边界片段相对于中心的几何信息。——对码本进行合并,降低冗余。
——选择最佳的边界片段,得到码本。码本中有边界片段相对于中心的几何信息。——对码本进行合并,降低冗余。
用boosting的方法训练物体检测器。
弱分类器:几个边界片段的组合就有了较好的判别信息,可以组成弱分类器。如下图:如果几个边界片段能匹配图像的边缘链,他们预测的中心比较靠近,并且与真正的物体中心接近。则形成弱分类器。
强分类器:用Adaboost的方法由弱分类器得到强分类器。这样,每个弱分类器有各自的权重,用于后面的投票;整个强分类器也有输出值,设置阈值后用于判断物体是否存在。
物体检测。
步骤:提取边缘——用弱分类器匹配——每个弱分类器投票(弱分类器有自己的权重),得到候选点(该点来自弱分类器的投票数,即强分类器的输出,必须大于一定阈值)——计算候选点的置信度,在候选点附近窗口内,用mean-shift的到新的中心——把对中心投票过的弱分类器重建出来——检测物体——分割。
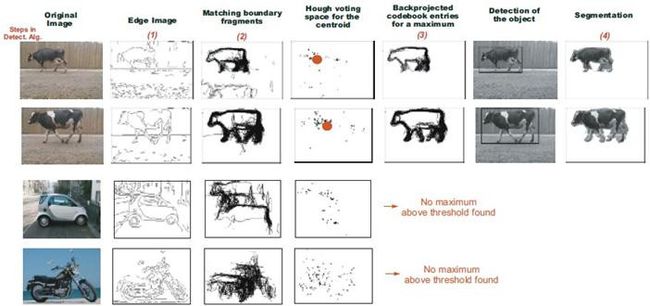
其中候选点的置信度用:
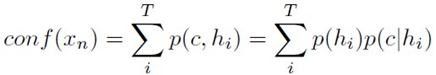
![]()
针对尺度、旋转和视角变化,在文章末尾对算法提出改进。
对比:与ISM(implicit shape model)不同在于,ISM用所有的部分投票,本文只用物体的边缘投票。
_____________________________________________________________________________________
文献3: Class-Specific Hough Forests for Object Detection,CVPR 09。
内容简介:通过训练特定类的Hough森林,由各个部分对物体的中心位置投票,选取最大值作为物体的中心。

创新点:Hough森林的引入。Hough森林的建立、在物体检测中的应用是本文的重点。
算法细节:
Hough森林的特点。
叶子节点存的是具有判别性的码本(一个patch是来自物体还是来自背景,物体中心距离当前patch中心的位置)。
建立Hough森林可以优化投票性能,即叶子节点投票时的不确定度将降低。
用有监督的方法建立树,即一个patch是来自物体还是来自背景, patch来自物体的哪个部分。
Hough森林的建立。
用有监督的方式训练Hough森林。训练包括建树、叶子节点信息的分配;测试时样本从每个树开始传递,输出是到达的所有叶子节点分布的平均。
建立Hough森林
训练数据和叶子信息:训练的patch表示为:,分别代表patch的特征、patch的类别(物体或是背景)、patch中心到bounding box中心的偏移量。叶子节点存储总的类别构成和偏移量,形成码本。

Patch的特征和二值测试:一个patch的C种特征为![]() ,同一种特征来自两个位置的二值测试定义为:
,同一种特征来自两个位置的二值测试定义为: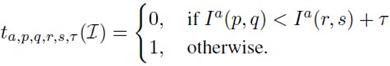 。
。
树的建立:建树时,每个节点得到很多patch,如果达到成为叶子节点的标准,该节点作为叶子节点。否则,需要拆分该节点。选择好的二值测试,将节点上的patch拆分给子节点。
一个好的二值测试,应该能使得后继结点的数据尽可能的"纯"。也就是说,越往叶子节点,类别和偏移量的不确定性应该越低。分别用类别不确定性和偏移量不确定性来度量节点的不纯度,定义为:
![]() 和
和
二值测试过程为:给定一些patch,均匀采样得到一系列测试像素;随机选择最下化类别不确定性还是偏移量不确定性;对不确定性求和:![]() 。随机选取可以保证叶子结点的类别不确定性和偏移量不确定性都比较低。
。随机选取可以保证叶子结点的类别不确定性和偏移量不确定性都比较低。
Hough森林做物体检测。
假设特定物体类别的bounding box大小固定,只要找到bounding box的中心即可。
E(x)代表随机事件——物体中心位于x。给定一个patch![]() ,当patch的中心在bounding box内时,物体中心位于x的概率为:
,当patch的中心在bounding box内时,物体中心位于x的概率为:
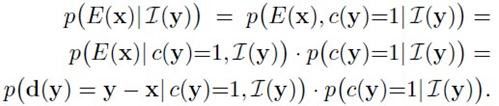
其中,上式第一项用核密度估计,给定一棵树:

给定整个森林,取各个树的平均。每个位置的得分是来自bounding box内各个patch投票的总和。所以检测输出最大得分的位置及其置信度。
注:为了提高速度,文中提到简化的策略。
处理不同尺度。将测试图像按尺度缩放,共S组。各个尺度内进行投票,最后得到得分最高的位置。
实验:将图像设置为相同的高度。训练时先随机选取正反例建立5棵树,再用更难区分的正反例建立5棵树,直到有15棵树时停止,Hough森林建立成功。特征用颜色、梯度、HOG。
对比:ISM和BFM用无监督的方法产生码本,而Hough森林的方法是有监督的,而且是判别式,所以速度快。