iocrl如何从user space调用到 kernel space,还有调用的流程:
图1:
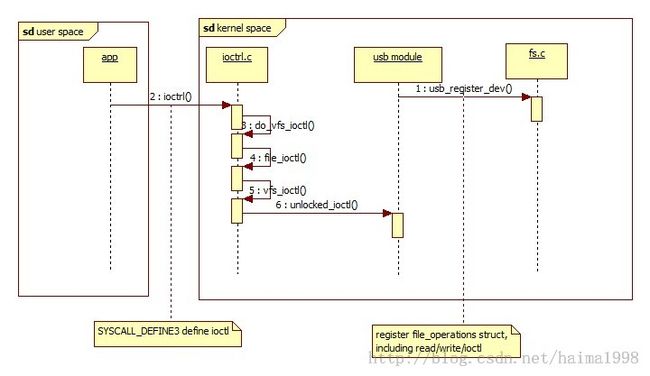 在上述的调用流程中,do_vfs_ioctl()会处理一些内核自定义的cmd type,如果我们自定义的cmd type和系统定义的重复,会导致
在上述的调用流程中,do_vfs_ioctl()会处理一些内核自定义的cmd type,如果我们自定义的cmd type和系统定义的重复,会导致
该自定义的ioctl cmd type调用不到(如cmd type = 2,系统已经定义并使用了FIGETBSZ=2),建议使用_IO 宏来定义cmd type,具体使用请参加说明: ioctl-number.txt
也可参考:http://stackoverflow.com/questions/10071296/ioctl-is-not-called-if-cmd-2
以下博客描述转自:http://www.cnblogs.com/hoys/archive/2011/04/11/2013078.html
在Linux的用户空间,我们经常会调用系统调用,下面我们跟踪一下read系统调用,使用的Linux内核版本为Linux2.6.37。不同的Linux版本其中的实现略有不同。
在一些应用中我们可以看到下面的一些定义:
| #define real_read(fd, buf, count ) (syscall(SYS_read, (fd), (buf), (count)))
|
其实真正调用的还是系统函数syscall(SYS_read),也就是sys_read()函数中,在Linux2.6.37中的利用几个宏定义实现。
Linux 系统调用(SCI,system call interface)的实现机制实际上是一个多路汇聚以及分解的过程,该汇聚点就是 0x80 中断这个入口点(X86 系统结构)。也就是说,所有系统调用都从用户空间中汇聚到 0x80 中断点,同时保存具体的系统调用号。当 0x80 中断处理程序运行时,将根据系统调用号对不同的系统调用分别处理(调用不同的内核函数处理)。
引起系统调用的两种途径
(1)int $0×80 , 老式linux内核版本中引起系统调用的唯一方式
(2)sysenter汇编指令
在Linux内核中使用下面的宏进行系统调用
| SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct file *file;
ssize_t ret = -EBADF;
int fput_needed;
file = fget_light(fd, &fput_needed);
if (file) {
loff_t pos = file_pos_read(file);
ret = vfs_read(file, buf, count, &pos);
file_pos_write(file, pos);
fput_light(file, fput_needed);
}
return ret;
}
|
其中SYSCALL_DEFINE3的宏定义如下:
| #define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
|
##的意思就是宏中的字符直接替换,
如果name = read,那么在宏中__NR_##name就替换成了__NR_read了。 __NR_##name是系统调用号,##指的是两次宏展开.即用实际的系统调用名字代替"name",然后再把__NR_...展开.如name == ioctl,则为__NR_ioctl。
| #ifdef CONFIG_FTRACE_SYSCALLS
#define SYSCALL_DEFINEx(x, sname, ...) \
static const char *types_##sname[] = { \
__SC_STR_TDECL##x(__VA_ARGS__) \
}; \
static const char *args_##sname[] = { \
__SC_STR_ADECL##x(__VA_ARGS__) \
}; \
SYSCALL_METADATA(sname, x); \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#else
#define SYSCALL_DEFINEx(x, sname, ...) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#endif
|
不管是否定义CONFIG_FTRACE_SYSCALLS宏,最终都会执行 下面的这个宏定义:
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
| #ifdef CONFIG_HAVE_SYSCALL_WRAPPERS
#define SYSCALL_DEFINE(name) static inline long SYSC_##name
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__SC_DECL##x(__VA_ARGS__)); \
static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__)); \
asmlinkage long SyS##name(__SC_LONG##x(__VA_ARGS__)) \
{ \
__SC_TEST##x(__VA_ARGS__); \
return (long) SYSC##name(__SC_CAST##x(__VA_ARGS__)); \
} \
SYSCALL_ALIAS(sys##name, SyS##name); \
static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__))
#else /* CONFIG_HAVE_SYSCALL_WRAPPERS */
#define SYSCALL_DEFINE(name) asmlinkage long sys_##name
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__SC_DECL##x(__VA_ARGS__))
#endif /* CONFIG_HAVE_SYSCALL_WRAPPERS */
|
最终会调用下面类型的宏定义:
asmlinkage long sys##name(__SC_DECL##x(__VA_ARGS__))
也就是我们前面提到的sys_read()系统函数。
asmlinkage通知编译器仅从栈中提取该函数的参数。所有的系统调用都需要这个限定词!这和我们上一篇文章quagga中提到的宏定义,有异曲同工之妙。
也就是宏定义中的下面代码:
| struct file *file;
ssize_t ret = -EBADF;
int fput_needed;
file = fget_light(fd, &fput_needed);
if (file) {
loff_t pos = file_pos_read(file);
ret = vfs_read(file, buf, count, &pos);
file_pos_write(file, pos);
fput_light(file, fput_needed);
}
return ret;
|
代码解析:
- fget_light() :根据 fd 指定的索引,从当前进程描述符中取出相应的 file 对象(见图3)。
- 如果没找到指定的 file 对象,则返回错误
- 如果找到了指定的 file 对象:
- 调用 file_pos_read() 函数取出此次读写文件的当前位置。
- 调用 vfs_read() 执行文件读取操作,而这个函数最终调用 file->f_op.read() 指向的函数,代码如下:
if (file->f_op->read)
ret = file->f_op->read(file, buf, count, pos);
- 调用 file_pos_write() 更新文件的当前读写位置。
- 调用 fput_light() 更新文件的引用计数。
- 最后返回读取数据的字节数。
到此,虚拟文件系统层所做的处理就完成了,控制权交给了 ext2 文件系统层。