构造可配置词法语法分析器生成器(上)
本文为笔者原创,转载请注明出处
http://blog.csdn.net/xinghongduo
前言
源程序在被编译为目标程序需要经过如下6个过程:词法分析,语法分析,语义分析,中间代码生成,代码优化,目标代码生成。词法分析和语法分析是编译过程的初始阶段,是编译器的重要组成部分,早期相关理论和工具缺乏的环境下,编写词法语法分析器是很繁琐的事情。上世纪70年代,贝尔实验室的M. E. Lesk,E. Schmidt和Stephen C. Johnson分别为Unix系统编写了词法分析器生成器Lex和语法分析器生成器Yacc,Lex接受由正则表达式定义的词法规则,Yacc接受由BNF范式描述的文法规则,它们能够自动生成分析对应词法和语法规则的C源程序,其强大的功能和灵活的特性很大程度上简化了词法分析和语法分析的构造难度。如今Lex和Yacc已经成为著名的Unix标准内置工具(Linux下对应的工具是Flex和Bison),并被广泛用于编译器前端构造,它已经帮助人们实现了数百种语言的编译器前端,比较著名的应用如mysql的SQL解析器,PHP,Ruby,Python等脚本语言的解释引擎,浏览器内核Webkit,早期的GCC等。本文将介绍可配置词法分析器和语法分析器生成器的内部原理,最后笔者实现了一个类似Lex & Yacc的可配置词法分析器生成器和语法分析器生成器,并利用它成功构造出了分析C99标准C的词法语法分析器。
词法分析器
词法分析器(tokenizer)的作用是按照词法定义规则将输入流分解为token序列,同时记录与每个token匹配的串和出现的位置等信息提供给语法分析器。手工编写一个针对某种语言的词法分析器是比较容易的,事实上很多编译器的词法分析器也是手写的,这种方式的优点是直观容易理解,缺点是开发效率低且易出错。编译技术经过几十年的发展已经形成了一套成熟的理论,应用这些理论可以让我们实现词法分析器的自动构造。在Lex中,每个词法规则由正则表达式定义,我们只需要定义每个token的正则表达式,Lex就可以自动生成对应的分析程序,所以本质上词法分析器生成器的核心是正则表达式引擎,下面将会介绍一些基础理论,以及如何实现一个基本的正则表达式引擎。
有穷状态自动机
为实现一个基本的正则表达式引擎,我们首先引入一个应用非常广泛的基础计算机模型—有穷状态自动机(FSM),有穷状态自动机形式定义为五元组M=(K, Σ, f, S, Z)其中
K是一个有穷集,它的每个元素称为一个状态;
Σ是一个有穷符号表,它的每个元素称为一个符号输入,所以也称为输入符号表;
f是转换函数,f(k,a)=e表示k状态在面临输入符号a时要转换到状态e;
S是初始状态,初始状态唯一;
Z是接受状态集;
例如:识别正则表达式ab(a|b)*ab的有穷状态自动机可以定义为M = ({1,2,3,4,5}, {a,b}, f,1,{5})其中f定义为:f(1,a) = {2} ,f(2,b) = {3},f(3,a) = {3,4},f(3,b) = {3},f(4,b) = {5}。用状态转换图表示如下:

有穷自动机M的状态转换图
有穷状态自动机又分为确定型(DFA)和不确定型(NFA),这里的不确定表示对于某一个输入符号,在同一个状态上可能存在多种转换,上图中状态3在面临符号a时存在两种转换,所以它是NFA。DFA在匹配过程中的任意时刻只在某个确定的状态上,而NFA在匹配过程中的某时刻可能在多个状态上,因此DFA是NFA的特例。对于一个基本正则表达式,存在能够识别它的DFA和NFA。
与M等价的DFA,状态转换唯一
以上图NFA匹配输入串ababaab的非标准过程:
目前实用的基于NFA的正则引擎为支持一些高级正则特性而普遍采用回溯法匹配,速度相对较慢。而构造词法分析器一般不需要高级正则特性,也就不需要回溯,使用类似于广度优先搜索的方式,每次匹配根据当前所有可达状态得到下一步所有可达状态,最后如果状态集中存在接受状态,则报告接受,否则匹配失败。DFA的状态转换唯一,匹配过程比NFA更简单,最后判断到达的状态是否是终态即可。由于DFA状态转换是确定的,因此DFA的匹配速度要高于NFA,但NFA支持一些DFA不支持的高级正则表达式特性,基于NFA的引擎也是很多的,JAVA,PHP中的正则引擎就是基于NFA的。
NFA中如果存在输入为空ε的边,则将其称为ε-NFA。ε边的含义是不需要任何输入符号就能进行状态转换,因此ε-NFA在每次状态转换后还需要对得到的状态集s进行一次ε闭包运算(ε-Closure),ε闭包运算的目的是得到s与s经过任意条ε边可达的所有状态的并集,也就是当前所有可达状态。
讲解了有穷状态自动机的定义,分类和匹配过程,下面介绍如何根据正则表达式构造识别它的自动机。我们首先回顾下正则表达式的基本语法,以下的定义来自MSDN并做了删减,笔者只保留了实现词法分析器生成器必要的语法规则,如有需要可以在其基础上自行扩展功能。
正则表达式基本规则
1. x|y匹配 x或y。
2. [xyz] 字符集。匹配包含的任一字符。
3. [^xyz] 反向字符集。匹配未包含的任何字符。
4. [a-z] 字符范围。匹配指定范围内的任何字符。
5. [^a-z] 反向范围字符。匹配不在指定的范围内的任何字符。
6. {n} n是非负整数。正好匹配n次。
7. {n,} n是非负整数。至少匹配n次。
8. {n,m} M 和 n是非负整数,其中n <= m。匹配至少n次,至多m次。
9. * 零次或多次匹配前面的字符或子表达式。等效于{0,}。
10. + 一次或多次匹配前面的字符或子表达式。等效于{1,}。
11. ? 零次或一次匹配前面的字符或子表达式。等效于 {0,1}。
12. \ 将下一字符标记为特殊字符。例如,“n”匹配字符“n”。“\n”匹配换行符。
13. (pattern) 匹配子表达式。
14. . 匹配除“\n”之外的任何字符。
15. \d 数字字符匹配。等效于 [0-9]。
16. \D 非数字字符匹配。等效于 [^0-9]。
17. \n 换行符匹配。
18. \r 匹配一个回车符。
19. \s 匹配任何空白字符,包括空格、制表符、换页符等。
20. \S 匹配任何非空白字符。
21. \w 匹配任何字类字符,包括下划线。与“[A-Za-z0-9_]”等效。
22. \W 与任何非单词字符匹配。与“[^A-Za-z0-9_]”等效。
上述的规则可以任意组合与嵌套构成识别复杂模式的正则表达式,规则看上去很多,但只需要几个简单的构造规则,就能构造出识别任意复杂正则表达式的ε-NFA。
汤普森构造法
汤普森构造法是C语言&Unix之父之一的肯·汤普森(Ken Thompson)提出的构造识别正则表达式ε-NFA的方法,其原理非常简单,先构造识别子表达式的ε-NFA,再通过几个简单的规则将ε-NFA合并,最终得到识别完整正则表达式的ε-NFA。汤普森构造法的优点是构造速度快,且构造的ε-NFA状态数较少。
1.对于空边ε,构造为ε-NFA为:
![]()
2.对于r=a,a为输入字符,则构造N(r)为
![]()
3.对于r=st,假设已经构造了s与t的NFA为N(s)和N(t),则N(r)构造为

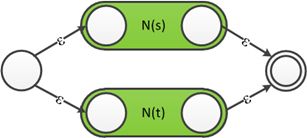
4.对于r=s|t,N(r)构造为
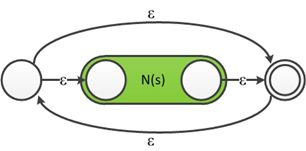
5.对于r=s*
6.对于r=s+

7.对于r=s?
8.对于r=s{n}

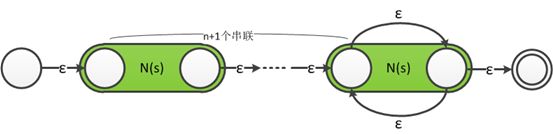
9.对于r=s{n,}
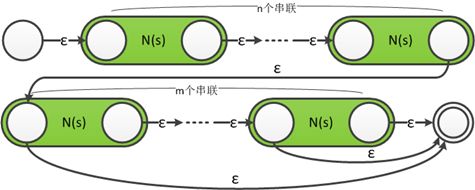
10.对于r=s{n,m}
给定一个任意复杂的正则表达式,从左至右依次建立每个符号或子表达式的ε-NFA,再通过上述几个规则合并,最终能构造出识别完整正则的ε-NFA。以正则表达式ab((aa)?|b+)*ba?为例,展示利用汤普森构造法建立识别它的ε-NFA的过程:
首先构造识别ab的ε-NFA:
构造识别(aa)的ε-NFA:
![]()
发现子表达式(aa)后有可选符号?,应用规则7构造(aa)?的ε-NFA:
构造b的ε-NFA:
![]()
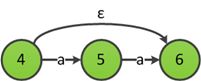
发现b后有+符号,应用规则6构造b+的ε-NFA:
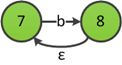
利用规则4合并(aa)?和b+,得到(aa)?|b+的ε-NFA:
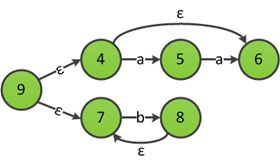
发现((aa)?|b+)后有*符号,应用规则5构造((aa)?|b+)*的ε-NFA:
利用规则3合并ab和((aa)?|b+)*,得到ab((aa)?|b+)*的ε-NFA:
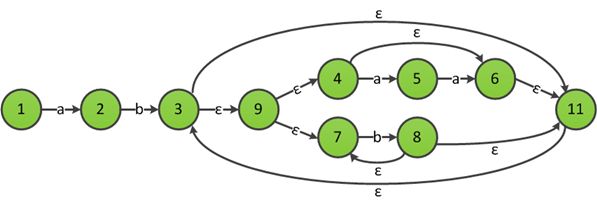
构造下一个符号b的ε-NFA,并利用规则3与ab((aa)?|b+)*的ε-NFA合并,得到ab((aa)?|b+)*b的ε-NFA:
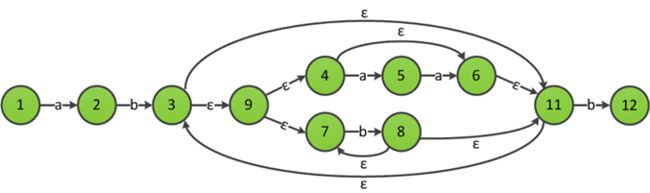
构造a?的ε-NFA:
最后应用规则3,将ab((aa)?|b+)*b和a?的ε-NFA合并,得到最终识别ab((aa)?|b+)*ba?的ε-NFA:
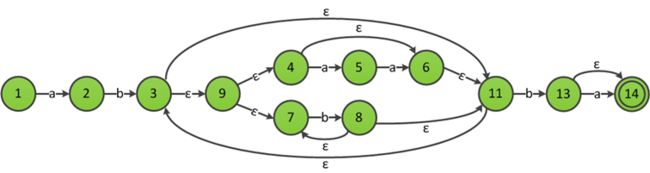
对于构造词法分析器,首先利用汤普森构造法构造出识别每个token正则的ε-NFA,然后将这些ε-NFA并联得到识别所有token的ε-NFA,该ε-NFA具有多个不同的接受状态。对于一个输入串,ε-NFA匹配该串后最终可能到达多个不同的接受状态上,为使词法分析器报告的匹配唯一,这里还要引入匹配优先级的概念。例如在多数编程语言中关键字都是标识符的特例,对于输入串int,我们期望词法分析器报告匹配了关键字而不是标识符,因此关键字比标识符的匹配优先级高,至于匹配优先级的实现,可以在每个ε-NFA的接受状态额外保存该状态匹配token的优先级,如果词法分析器最后到达了多个接受状态,那么则报告匹配了优先级最高的接受状态对应的token。
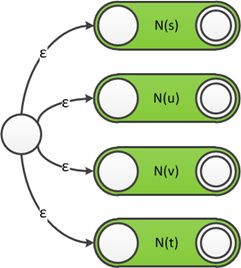
并联识别每个token的ε-NFA
符号集压缩
如果正则表达式中的某个元素包含多个符号的转换,例如[a-zA-Z],那么在构造识别它的ε-NFA的两个相邻状态s1和s2时,不必对于每个符号都添加一条s1到s2的边。因为对于状态s1来说,这个符号集中的每个符号都是等价的,因此可以利用符号集来表示状态转换减少ε-NFA边的数量。对于一个符号集,可以用一个唯一的id来表示,而对于单个符号,我们需要一个映射表来将该符号映射到其所属的符号集。需要注意的是,提取出每个token正则中的每个元素的符号集后,需要将这些符号集其划分,确保每个符号只属于一个符号集。
符号集压缩应在构造ε-NFA之前进行,在读入token定义正则表达式的同时,依次扫描该正则中每个元素的符号集s,并将s与已经划分的符号集做比较,可能出现以下几种情况:
1.若s与之前划分的符号集k相等,则停止比较。
2若s包含了之前划分的符号集k且s不等于k,则需要将s划分为k和s-k的并,并将s-k继续与其他符号集比较。
3.若s属于之前划分的符号集k,且s不等于k,则为s分配一个id,并在映射表中将s包含的字符映射到该id。
4.若s与之前划分的符号集k部分相交,则将s∩k作为新的符号集分配id,且在映射表中将s∩k中的字符映射到该id,并将s-s∩k继续与其他符号集比较。
5.若s与之前划分的所有符号集交集都为空,则为s分配一个id,并在映射表中将s包含的字符映射到该id。
上述规则对每个符号集都不存在过度拆分,因此它可以保证划分得到的符号集数量最少,压缩率是最高的,多数情况下都可以对ε-NFA的边很好的压缩,最坏情况下每个符号自为一个符号集。对于所有在正则中未出现的字符,在映射表中都映射到-1,表示不存在该符号的边。
正则表达式a1[a-zA-Z]+\d[x-z0-5]经过符号集压缩后的映射表
利用符号集表示状态转换的ε-NFA,边数减少很多
ε-NFA去空边
ε-NFA的状态数较多,且每次状态集转换后要进行ε闭包运算求出所有可达状态,匹配性能较低。为避免每次状态转换后进行ε闭包运算,可以将ε-NFA进一步转化为NFA。考虑下ε边的意义,ε边的意义是不需要任何输入符号就能进行状态转换,如果状态S1经过ε边可转换到状态S2,而S2又可以通过某输入符号a转换到状态S3,那么S1也可以通过符号a转换到状态S3,对于状态S1来说,状态S2只是它到达状态S3的中转状态,这个中转的过程完全可以通过添加一条S1到S3符号为a的边实现。根据此思路容易得到如下算法:
1.如果某个状态结点的所有入边都是ε边,则将其标记为中转状态。原因是该状态的所有出边均可以移动至其前驱节点,该状态在优化后将成为不可达状态。
2.对于每个非中转状态s求ε-Closure(s),将求ε闭包得到状态集中的每个状态的非ε出边复制到s,同时注意接受状态的合并。
3.删除所有与中转状态和其相关的边。
4.删除所有ε边。
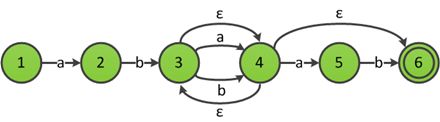
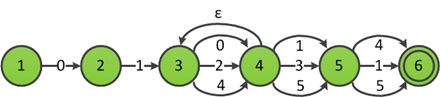
识别ab(a|b)*(ab)?的ε-NFA
以上图识别ab(a|b)*(ab)?的ε-NFA为例描述优化的过程:首先标记中转状态,扫描发现除开始状态外,其余状态的所有入边均不全是ε边,因此图中没有中转状态,所有状态优化后都是可达的。1,2,5,6的ε闭包均为其自身,因此不需要复制边,ε-Closure(3)={3,4,6},将4和6的所有非ε出边复制到3,状态6是接受状态,因此合并后3也是接受状态,ε-Closure(4)={3,4,6},将3和6的非ε出边复制到4,最后得到下图的NFA。
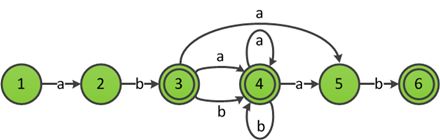
消除ε边得到的NFA
一般情况下NFA的匹配速度与DFA相差不大,但对于较多前缀相同的正则表达式或极端的输入串,NFA在每次状态转换时可能会转换到较多甚至是全部状态上,例如对于aaaaaaaaa,aaaaaaaab,.......aaaaaaaaz这些只有最后一个字符不同的正则表达式,输入串为aaaaaaaaz,在匹配到最后一个字符前每次都要转换到26个分支的状态上。如果N为NFA的状态数,L为输入串长度,则NFA匹配的最坏时间复杂度为O(NL),性能较低。而DFA每次状态转换都是确定的,只需要扫描一遍输入串即可确定匹配的模式,最好和最坏的时间复杂度都是O(L),因此更适用于词法分析器这种对性能要求较高的场景。
子集构造法
子集构造法用于构造与NFA等价的DFA。NFA在匹配过程中实际上是状态集的转换,每次得到的状态集就是对当前匹配状态的描述,因此我们可以将每个可达状态集映射为一个状态。若s1和s2是转换过程中的两个状态集,且s1通过符号t转换到s2,则创建两个状态d1和d2分别对应状态集s1和s2,并添加一条d1到d2符号为t的边,同时要注意如果状态集s1中存在接受状态,那么d1也是s1中优先级最高的接受状态,s2和d2同理。对NFA中所有可达状态集之间的所有符号转换进行该操作,可以得到另一个自动机,因为NFA中所有可达的状态集在这个状态机中都有对应状态,所以该状态机与NFA是等价的,且该状态机中的任何状态都不存在多个同符号的出边,恰好满足DFA的定义,因此这个状态机就是与NFA等价的DFA。
以上节中识别ab(a|b)*(ab)?的NFA为例:开始状态集{1}为起始,检测每个状态集对于每个输入符号的转换,直到没有新的状态集产生,图中的表格列出了每种状态集对于每个符号的转换关系,表中NFA的每一个状态集对应着DFA的一个状态,最后得到右图的DFA。

子集构造法的过程
对于绝大多数NFA,子集构造法都能有效的构造出与其等价的DFA,上面讲到NFA中的每个可达状态集都对应着DFA中的一个状态,而含有n个状态的NFA包含2^n-1个非空子集,也就是说对于某些极端的NFA,子集构造法构造的DFA状态数可能达到指数级。例如:正则表达式(a|b)*a(a|b)(a|b)…(a|b) n-1个(a|b),它最小DFA的状态数不会少于2^n。虽然存在这样的极端,但在词法分析器实际应用中,几乎不会出现这样的正则表达式,即使如果存在这样的应用场景,那么就不要用基于DFA的引擎,直接使用NFA匹配即可。
DFA最小化
任何DFA都存在唯一的与其等价的最小DFA,利用子集构造法将NFA转化得到的DFA不一定是最小的,虽然DFA的匹配速度只与输入串长度有关,但最小化的DFA状态数可能更少,实现起来占用更少的资源,因此最小化DFA是有意义的。
最小化DFA的常用方法是分割法,其原理是通过合并等价状态和删除死状态来减少DFA的状态数。如果一个非接受状态对于任何输入符号都转换到自身,则称其为死状态,因为一旦到达这个状态就始终停在这个状态上了,永远无法到达接受状态,因此是无意义的可以删除。如果两个状态s和t对于任何输入符号都转换到相同的状态上,并且s和t同为接受状态或不可接受状态,那么s与t就是等价的。下图左侧的DFA中,状态2和状态3都是非接受状态,并且对于所有符号都转换到相同的状态上,因此他们是等价的,可以合并得到右图最小的DFA。
左图状态2与状态3等价,合并后得到右图最小DFA
一旦多个状态被判定为等价状态,那么就表示这些状态可以合并为一个状态,因此若s和t对于任何符号不是转换到相同状态,而是转换到等价的状态上,其实也是相当于转换到了相同的状态,因此s与t也是等价状态。下面给出等价状态较为严谨的定义。
在有穷状态自动机中,两个状态s与t等价必须满足以下两个条件:
一致性条件:状态s与t必须同是接受状态(接受同一个token)或不可接受状态。
蔓延性条件:对于所有符号,s和t必须转换到等价的状态中。
分割法最小化DFA的最终目的是将所有状态划分为若干个不相交的子集,每个子集内的状态都是等价的,而不同子集间的状态都是不等价的,最后将所有等价的状态合并。
首先进行初始子集的分割:所有非接受状态划分为一个子集,对于接受相同token的接受状态分别划分为一个子集。经过上述划分后,可以得到n+1个子集(n为token的数量),因为每个子集中的状态接受的token都不相同,根据一致性条件,任意两个子集的间的状态都是不等价的。
经过初始分割后,我们得到了一些相互不等价的子集,但对于每个子集内的状态,还是不能确定是否都是等价状态,因此需要继续划分。划分的方法是针对每个子集扫描它的每个状态s,并与该子集的第一个状态t比较,根据等价的定义判断s与t是否等价,如果不等价则该子集需要分割,将该子集所有与t不等价的状态分割为新的子集。由于等价状态的判断存在依赖关系,因此需要反复尝试对每个子集分割,直到每个子集都不能再分割为止。
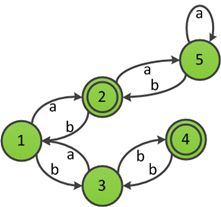
经过上述过程后,最终得到若干个互不等价的子集,且每个子集内的状态都是等价的。对于含有多个状态的子集,将它的所有状态合并为一个状态,经过合并后即得最小的DFA,子集的数量就是最小DFA的状态数。下面引用编译原理教材上的一个例子展示最小化DFA的过程。
根据接受状态和非接受状态得到初始子集划分{1,3,5,6}{2,4,7}
扫描子集{1,3,5,6},状态1和状态3对于符号ab都转换到了不等价状态,状态1和状态5对于符号ab也都转换到了不等价状态,因此该子集划分为{1,6}{3,5}。
扫描子集{2,4,7},状态2和状态4对于符号a转换到了不等价状态,因此该子集划分为{2,7}{7}
经过第二轮划分后的子集{1,6}{2,7}{3,5}{4}。
扫描子集{3,5},状态3和状态5对于符号a转换到了不等价状态,因此该子集划分为{3}{5}
经过第三轮划分后的子集{1,6}{2,7}{3}{4}{5},至此每个子集都不能再划分,将每个子集内的状态合并,最后得到下图最小DFA。
正则表达式引擎到词法分析器
以上实际上是讲解了构造正则表达式引擎的基础,而我们实现的正则表达式引擎在判断输入串匹配了哪个token后就停止了,而词法分析器是需要在输入流中不断匹配token的,为实现该能力,可以在自动机匹配一个token后继续读入字符,如果匹配到更长的模式或优先级更高的模式则更新匹配状态,如果无法进行状态转换则报告语法分析器已经匹配成功的token,并将输入流指针回退到最后一次匹配token的字符位置,然后复位自动机开始下一个token的匹配。如果还没有匹配token就已经无法进行状态转换,则表明扫描到了不满足任何token定义的符号,此时需要丢弃一个字符,然后复位自动机重新匹配。