有效率的SQL查询(I)
大型系统的生产环境,一般情况下,我们评价一条查询是否有效率,更多的是关注逻辑IO(至于为什么,回头补一篇)。我们常说,“要建彪悍的索引”、“要写高效的SQL”,其实最终目的就是在相同结果集情况下,尽可能减少逻辑IO。
1.1 where条件的列上都得有统计信息。
没统计信息SQLServer就无法估算不同查询计划开销优劣,而只能采用最稳妥的Scan(不管是table scan还是clustered index scan)。一般情况下我们不会犯这种错误——where条件里不使用非索引列是个常识。索引上的统计信息是无法删除的。
1.2 尽量不使用不等于(!=)或者NOT逻辑运算符。
这条规则被广为传颂,原因据联机文档和百敬同学的书讲,也是SQLServer无法评估不同查询计划开销的优劣。但是SqlServer2k5聪明了很多,试验发现尽管用了!=或者not,查询还是会被优化。如下:
create table tb1
(
col1 int identity(1,1) primary key,
col2 int not null,
col3 varchar(64) not null
)
create index ix_tb1_col2 on tb1
(
col2
)
create index ix_tb1_col3 on tb1
(
col3
)
declare @f int
set @f = 0
while @f < 9999
begin
insert into tb1 (col2, col3) values(1, 'ssdd')
set @f = @f + 1
end
insert into tb1 (col2, col3) values(0, 'aadddd')
insert into tb1 (col2, col3) values(2, 'bbddd')
insert into tb1 (col2, col3) values(3, 'bbaaddddddaa')
通过上述代码,各位可以看到数据分布。col2值为1的有9999条;col2值为0、2、3的分别有1条。
按照本条规则,!= 和NOT带来的应该是个scan操作,但实际情况是:
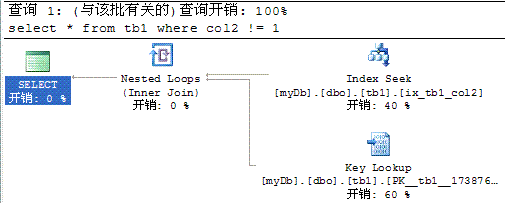
SQL2k5很聪明,它依据统计信息分析得出来,应该采用index seek而不是index scan。(稍微解释解释index seek和index scan:索引是一颗B树,index seek是查找从B树的根节点开始,一级一级找到目标行。index scan则是从左到右,把整个B树遍历一遍。假设唯一的目标行位于索引树(假设是非聚集索引,树深度2,叶节点占用k页物理存储)最右的叶节点上(如上例)。index seek引起的IO是4,而index scan引起的IO是K,性能差别巨大。关于索引,可以仔细读读联机文档关于物理数据库体系结构部分)。
1.3 查询条件中不要包含运算
这些运算包括字符串连接(如:select * from Users where UserName + ‘pig’ = ‘张三pig’),通配符在前面的Like运算(如:select * from tb1 where col4 like ‘%aa’),使用其他用户自定义函数、系统内置函数、标量函数等等(如:select * from UserLog where datepart(dd, LogTime) = 3)。
SQLServer在处理以上语句时,一样没办法估算开销。最终结果当然是clustered index scan或者table scan了。
1.4 查询条件中不要包含同一张表内不同列之间的运算
所谓的“运算”包括加减乘除或通过一些function(如:select * from tb where col1 – col2 = 1997),也包括比较运算(如:select * from tb where col1 > col2)。这种情况下,SQLServer一样没办法估算开销。不论col1、col2上都有索引还是创建了col1、col2上的覆盖索引还是创建了col1 include col2的索引。
但是这种查询有解决办法,可以在表上多创建一个计算字段,其值设置为你的“运算”结果,再在该字段上创建一个索引,就Ok了。
To Be Continue…
(II)中将介绍统计信息值分布不均匀对查询的影响和如何避免这些影响,捎带更多的说说返回多行结果时,为啥SQLServer有时会选择index seek,而有时会选择index scan。
(III)中主要介绍传说中的“Foldable”和“NonFoldable”表达式。并举例说说所谓的“Nonfoldable"表达式某些情况下也不是那么可怕。
(IV)中则主要说说在程序中执行SQL。如:安全性,拼SQL、参数化SQL和存储过程之间对DB来说有什么区别,参数化SQL的一些技巧。捎带着,会大概介绍介绍SQLServer的Buffer Pool