Aerospike-Architecture系列之次索引
Secondary Index(次索引)
次索引建立在非主键之上,给模型一个一对多关系的能力。索引的指定基于bin(类似RDBMS中的列)。允许高效更新并减少索引存储资源的需求。
数据描述(DDL)被用于决定哪些bin和type被索引。索引可以通过工具或API动态创建或移除。类似RDBMS的模式,即使bin被DDL定义为索引,DDL也不进行数据校验。更新索引bin的记录时索引一起更新。
例如,索引只能被创建在字符串(string)或整型上(integer)。考虑一下这种情况,一个bin存储用户年龄一个应用存储为字符串类型另一个存储正整型。整型索引将不包括字符串类型的记录,字符串类型的索引也不包括整型的记录。
次索引是这样的:
- 为快速查找存储于内存中
- 建立在集群的每一个节点上。每个次索引条目包含指向本节点记录位置的引用。
- 次索引包含集群中主记录和复制记录的指针
Data Structure
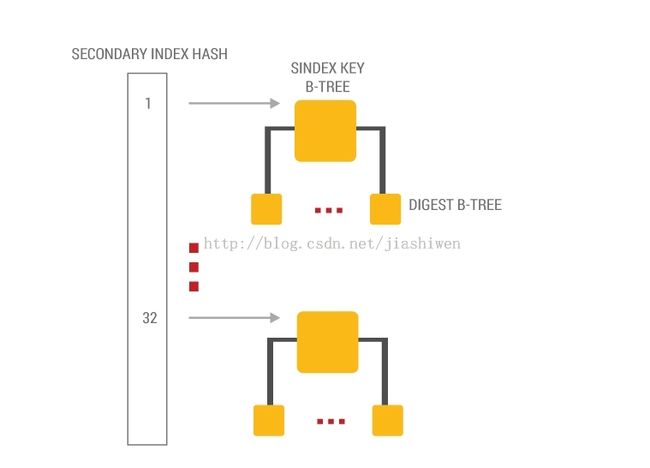
就像主索引一样,次索引是一个在B-tree中的B-tree形式的哈希表。每个逻辑次索引拥有32个物理树。当key被定义为索引操作,哈希函数用来决定索引条目创建在哪些物理树上。标识B-tree更新以后,注意一个次索引的键可以引用多个主记录。结构的最底层是基于记录数量的完整B-tree。
Index Management(索引管理)
Index Metadata(索引元数据)
Aerospike将索引创建信息保留在特殊的全局维护的数据结构中-系统元数据(SMD)。系统元数据模块位于多节点多次索引模块中。次索引的变化最终由SMD触发。

- 客户端请求触发 create / delete / update与次索引元数据由关的操作。请求通过次索引模块到达SMD
- SMD发出对paxos master的请求
- Paxos master从集群中所有节点请求相关的元数据信息。当所有数据返回,它调用次索引合并的回调函数。该函数负责分析元胜出的数据版本。
- 一旦为次索引确定了版本信息,请求被发送到所有接节点来接受新的元数据信息。
- 每个节点执行次索引create/delete DDL函数,然后触发一个扫描并返回客户端。
Index Creation(索引创建)
Aerospike支持动态创建次索引。aql工具可以读取当前可用的索引,并能够创建和分布索引。
-
要建立次索引,用户需要制定namespace, set, bin及索引类型(例如整型、字符串型)
-
从 SMD接收到确认每个节点以write-active模式创建次索引并启动一个后台扫描作业,作业扫描所有数据并将条目插入次索引。
-
索引条目只有在记录满足所有索引制定条件的情况下才会被创建。
-
次索引中的扫描作业与以完全相同的方式正常扫描的read/write事务互动,与正常扫描不同的是,索引扫描没有网络组件参与。在索引创建期间,所有新的影响索引属性的写操作都会更新索引。
-
-
索引创建扫描一完成所有的索引条目也就被创建了,索引立即准备用于查询并被标记为read-active。
-
索引在所有节点创建成功以后,次索引对所有普通查询有效。
Recommendations(建议)
- 索引DDL (create/drop index)在集群尚未形成或是集群正在故障检测时可能被忽略。索引的建立是I/O密集型操作,应该在低负载时进行。
- 如果节点携数据加入集群,但错过了索引定义,错过的索引会被创建并加入集群。在索引形成期间不允许查询访问。为了避免在节点加入时出现这样的情况应该在索引增长前进行清理。
Create Index Priority(创建索引的优先级)
索引创建扫描只读取应经被事务提交的记录(没有脏读)。假设没有记录更新阻塞,扫描将全速执行。因此重要的优先级设置索引构建在正确的级别,以确保创建索引扫描不影响正在进行的读和写交易的延迟。Aerospike实时引擎中的作业优先级设置可以用来有效地控制创建索引扫描的资源利用率。默认参数应该满足大多数情况,因为这基于多年的部署经验,这些经验来自于像再平衡与备份这样的长事务与低延迟读写之间的平衡。
Writing data with indexes(带索引的数据写入)
当数据被写入,当前索引的系统元数据 (SMD)被检查。,次索引为所有带索引的bin执行 update/insert/delete。注意Aerospike是一个flex-schema系统。如果对应的bin没有值或者数据类型不合适,相应的下一个步骤不会被执行
所有这些次索引的变化在当记录发生变化时被同步执行。由于索引是非持续的,提交索引与数据的困难提交问题没有了,提高了速度。
Garbage Collection(垃圾回收)
为了删除次索引的条目,当主数据被删除(e.g delete/expiry/eviction/migration),数据将不能从磁盘读入。这避免了不必要的I/O开销。次索引条目会由一个定时唤起的后台线程进行清理。垃圾回收器被设计为非侵入式。它在一个小的批量中创建被删除条目的列表然后缓慢的从索引中删除。在系统中存在大量清理工作时,需要更多内存以适应垃圾回收。
Distributed Query(分布式查询)
通过次索引的查询请求被发送到每个集群节点。图B描述其基本架构,步骤如下:
- 分散请求到所有节点
- 内存中的索引快速映射到主键
- 索引与各节点SSD上的数据协作来保证ACID 并管理迁移
- 从所有 SSDs / DRAM并行读取记录
- 在各节点汇聚结果集
- 从所有节点整合结果集发送到客户端
次索引查找一个非常长的主键记录列表。出于这个原因我们选择做小批量的次索引查找。也有一些在客户端响应的批量,如果内存达到临界值,响应立即被写入网络。这种行为就像Aerospike批处理请求的返回值的情况。通常的想法是,不管请求的选择度如何,保持一个独立二次查找的内存为一个常数
Query Result(查询结果)
查询进程确认的结果,是与查询记录被扫描期间的真实数据同步的。不存在查询执行过程中未提交的数据。然而可能返回查询期间被删除的数据。
In Presence of Cluster State Change(集群状态变化时的情况)
下面表格描述了次索引重建和查询结果一致性的场景
| Scenario | Persistent Namespace Boot Type | Data-in-memory | Secondary Index Population | Node Boot Time | Query Consistency during migrations |
|---|---|---|---|---|---|
| Node Joining | With Data; Without Fast Restart | False | Post Data Load From Disk; Parallel Data Partition Scan | Higher data load time than with no secondary index | Best effort * |
| Node Joining | With Data; With Fast Restart (Primary Key Index Available in Shared memory) | False | Post Fast Restart; Parallel Data Partition Scan ** | Higher data load time than with no secondary index | Best effort * |
| Node Joining | With Data; Without Fast Restart | True | At the data load from disk | No Signficant difference with and without Secondary Index | Best effort * |
| Node Joining | With No Data; Always Without Fast Restart | True/False | -NA- | -NA- | Consistent Copy |
| Node Leaving | - NA - | True/False | -NA- | -NA- | Consistent Copy |
在通常的操作环境下,节点可以在被添加或移除时就被完全查询可用。当迁移进行时,Aerospike照看从磁盘装在数据是的数据负载(详见结果一致性表)
Query Node(查询节点)
在数据迁移期间进行精确查询非常复杂。当节点被添加到集群或是从集群移除时,会调用数据迁移模块将数据转换至新配置的适当节点。在迁移行动中,分区可能在很多节点上存在不同版本。为了访问到拥有查询数据的分区位置。Aerospike利用其它集群中在节点间共享的分区状态查询处理质量,并且每个可能被执行潮汛的分区选择一个查询节点。选择分区的查询节点基于很多因素(例如,分区中的记录数,集群中分区的副本数量等等)。系统设计的目标是查询能够得到最精确的结果。
Aggregations(汇聚)
查询记录可以提供给汇聚框架来执行过滤。每个节点上,查询结果被发送到UDF子系统作为记录流处理。用户提及的UDF流将被调用,用户定义的操作序列将被应用到查询结果。各节点的结果由客户端收集,也有可能执行其他数据操作。
Performance(性能)
为了确保汇聚不会影响数据库整体性能,我们采用了多种技术:
全局队列用来管理记录通过处理的各个阶段,线程池有效利用CPU并行能力。查询状态被线程池共享,使系统能够正确管理流UDF管道。除了初始化数据,汇聚中的每个阶段都是一个CPU绑定操作。所以各阶段快速、优化的完成非常重要。为了达到这个目的,我们运用了类似记录批量处理的技术,UDF状态缓存等技术来优化实时海量记录处理的系统上限。
此外,为了那些在数据存储于内存中的namespace之上的操作(无存储获取),数据流处理实现在一个单独的线程上下文中。即使在这种情况下,由于Aerospike原生的将数据划分为固定数量的分区,系统仍然可以并行化操作跨分区的数据。
译 者:北京IT爷们儿