迭代器之入门介绍(下)
迭代器之入门介绍(下)
我们又见面了~~
或许之前的内容你觉得都比较简单,那么这次得有点心理准备,我打算讲稍微深入一些的东西。
而且可能也不会讲那么详细,或者说废话那么多了,点到为止,剩下的,你最好还是自己去查一查。
哎呀,没心理准备?
那就在此之前先聊个最简单的小玩意吧。
最简单的迭代器:指针
呵呵,是的没错,最简单的迭代器就是我们早已打交道n久老伙计——指针。语言的原生(native)指针。
不信?想想指针可以做啥:
- 可以指向一个内存区域中的位置。
- 可以通过++、--前后移动
- 可以通过*来访问其指向地方的数据。
- 可以用=赋值,可以用==、!=比较。
完全和我们(上)篇中介绍的迭代器的特性一样嘛!
事实上,如果你记得我之前说过的一句话:“迭代器就是对指针这个概念的抽象”,应该就明白了。迭代器在广义上说就是一种容器内元素的指针,现在语言原生指针何有不算迭代器之理?
再不信,你可以把指针传给STL那些需要迭代器的算法函数中,保证工作正常:
| C++ 代码: |
int arr[5]={5,3,9,-4,12};
int* begin=&arr[0];
int* end=&arr[4];
sort(begin,end);
这段代码会将这个数组排序……会非常顺利的通过编译,而且工作很正常。
现在信了吧?呵呵。
不过这里有一个小陷阱:虽然你发现之后的数组完全排序了,但是只不过是恰巧而已。事实上你只对数组的前4个元素排序了。为什么?想想你end指向的位置,再想想STL的区间是怎么一回事吧,呵呵。
其实可以写的更简单点:
| C++ 代码: |
int arr[5]={5,3,9,-4,12};
sort(arr,arr+5);
这样就可以对整个数组完全排序了。因为指针还支持相加运算,可以把一个指针+n来得到这个指针之后n个位置的地方。多么强大的功能,很多迭代器也不支持的。
是的,你之后就会看到,虽然指针是“最简单的迭代器”,但是它却属于迭代器分类中最强大的一种。
最后稍微透露你一个内幕消息:
嘿嘿,其实一些版本的STL中,vector的迭代器就是一个指针。只不过你一直在用vector<XX>::iterator这种写法而被蒙在鼓里而已,呵呵。不过你可千万别写:int *p= v.begin();这种代码啊,我都说了,只是有一些STL版本是这么干的,不保证其它版本也是用的指针啊。你如果实在无聊的话倒是可以测试一下,呵呵。
怎么样,“最简单的迭代器”,的确够简单吧!那么下面就来聊个更复杂的:
更复杂的迭代器:迭代器之配接器(Adapter)
配接器(Adapter,或者译为适配器),该怎么理解?
搞过DIY的朋友可能经常见到这个词汇,显卡适配器、网络适配器……
其实说白了,就是一个满足某一接口(或者说条件),而实际内容可以有所不同的一类东西。
还是有点晕?继续往下看:
在这里,接口或条件就值得是迭代器的各种行为。
于是我们的迭代器配接器就可以这么理解:
它是这么一类东西:提供和普通迭代器完全一样的操作——以至于我们使用的时候都感觉不到差别,但是他们做的事情却和普通迭代器有所不同。
好了具体点,说说STL中提供的三类Adapter吧:
- 反向(逆向,Reverse)迭代器
- 插入(安插,Insert)迭代器
- 流(Stream)迭代器
先别急着头晕,我慢慢来介绍。嗯,要收中介费。。
反向(逆向,Reverse)迭代器
顾名思义,这种特殊的迭代器提供一种逆向的访问——它是倒着走的。
它的++操作符是往前回退,而--操作符是往后移动,与正常的迭代器刚好相反。
除此之外,你使用这种迭代器和普通的迭代器并无二致。
为啥要搞这么一个迭代器出来呢?
比如我们想反向遍历一个容器,你用普通迭代器怎么写?
| C++ 代码: |
for(Cont::iterator it=v.end();it!=v.begin();--it)
{
//... ?????!!
}
这样写吗?
显然是错的。你也看出来了,你访问了不该访问的end位置,却没有访问本该访问的begin位置。
而有了逆向迭代器就很好办了:
| C++ 代码: |
for(Cont::reverse_iterator it=v.rbegin(); it!=v.rend(); ++it)
{
//...
}
这样我们就可以逆向遍历了!和正向遍历的时候完全一样,只是把迭代器换成了逆向迭代器而已。
我知道你这时候想问一些东西了,不过还是先看我列的一张表吧:
|
|
|
| reverse_iterator |
类型,代表这个容器适用的逆向迭代器的类型。 |
| const_reverse_iterator |
类型,代表这个容器适用的常量逆向迭代器的类型。 |
| rbegin() |
成员函数,返回这个容器的逆向起始位置。(可以理解为最后一个元素的位置) |
| rend() |
成员函数,返回这个容器的逆向结束位置。(可以理解为第一个元素之前的位置) |
这是STL中所有标准容器提供的成员,你可通过它们来方便的使用逆向迭代器。
如何?还有问题吗?
介绍下一位:
插入(安插,Insert)迭代器
还记得我在(中)篇里面最开始介绍的那个错误的例子吗?
不记得了?好吧,我做一次搬运工。。就是这段代码啦:
| C++ 代码: |
vector<int> v;
//... 然后向v里面添加了些数据
list<double> li;
copy(v.begin(),v.end(),li.begin());
当时我说了这个有严重的问题。list可能没有足够的空间,需要事先resize一下。
但是我那时候也说了,上述方法不够优雅。优雅的做法是:将copy默认进行的拷贝操作变成插入操作。
当时卖了个关子,没说具体方法。现在想必你也猜到了:对,就是使用这个配接器。
insert iterator,插入型迭代器,又称inserter(插入器),就是这么一个配接器:它将普通迭代器的赋值操作变成插入操作。
来看看上面的那个例子如何优雅的解决:
| C++ 代码: |
vector<int> v;
//... 然后向v里面添加了些数据
list<double> li;
copy(v.begin(),v.end(),back_inserter(li));
这样,这个copy算法默认的赋值操作就被适配(Adapt)成了一个插入操作:插入型迭代器将调用list的push_back()方法来将数据一个个插入到容器尾部。
你看到back_inserter这个名字,想必也猜出来了:对,插入迭代器有三种类型,分别使用三个函数来创建:
|
|
|
| back_inserter(container) |
返回尾部插入型迭代器,内部会调用容器container的push_back()方法来将数据插入容器的尾部 |
| front_inserter(container) |
返回头部插入型迭代器,内部会调用容器container的push_front()方法来将数据插入容器的头部 |
| inserter(container,pos) |
返回通用插入型迭代器,内部会调用容器container的insert(pos)方法将数据插入到pos位置。 |
不过这里要清楚,不是所有的容器都可以适用上述三种方法来创建插入型迭代器的。事实上vector不能创建front inserter,map和set不能创建back inserter 和front inserter ——对,你猜出来了:
如果容器没有push_back()方法,那你就不能创建back inserter,不然这些配接器内部怎么调用那些函数?其它插入迭代器也是一样。
对于通用型插入迭代器,由于所有标准容器都提供了insert方法,因此所有标准容器都可以创建。不过效率未必很高——取决于容器的insert方法的效率。
最后一位出场:
流(Stream)迭代器
这个配接器有点诡异,他事实上可以为一个流(stream)创建一个迭代器从而实现对流的读取或写入。
个人感觉,这玩意的用处不是特别大,主要是用于将各种流适配到STL的那些针对迭代器的算法上。
有些时候还是非常好玩的。
最常见的流就是标准输入输出流了:
istream_iterator<int>(cin);
这一句,创建了一个输入流迭代器,可以从cin中读取整数(int)。
最后给出一个经典的例子,也是很多书上被拿来展现STL强大之处的一个例子:
三句话实现从屏幕中输入单词,按字母顺序排序,剔除重复单词后,输出到屏幕上。
嘿嘿,先想想如果你用C写的话得写多少代码……
那么来看看在C++中如何写:
| C++ 代码: |
vector<string> v1((istream_iterator<string>(cin)),(istream_iterator<string>()));
sort(v1.begin(),v1.end());
unique_copy(v1.begin(),v1.end(),ostream_iterator<string>(cout," "));
用STL实现就这么一点,恰三行代码。
来稍微解释下:
第一句定义了一个vector v1,并且在构造函数中传入两个输入流迭代器,这两个迭代器构成一个区间,表示输入的所有单词,直到输入终止(EOF)。这样v1就在创建的时候里面填满了输入的各个单词。
第二句,使用sort对这个vector里面的元素进行排序。是的,不需要你写复杂的字符串比较函数,string内部带有operator < 的定义。而sort,只需要一个小于号即可运作。排序完毕后,所有单词就按照字母顺序从小到大整齐排列了。
第三句,使用unique_copy来将v1中的数据拷贝到目标区间。unique_copy和copy的不同之处就在于,它可以将连续的n个相同元素剔除掉其中的n-1个,只留下一个元素,从而实现unique的功能。这次拷贝的目标区间的起始又是流迭代器——这次是输出流迭代器,它将算法给它的数据输出到cout中,于是就显示在屏幕上了。
很神奇,很强大吧。我觉得用这个例子来作为迭代器配接器介绍的结尾,挺好的。
ok,STL中的三大迭代器配接器已经粗略介绍完了。其实它们每一个都有很多细节,如果你想自如的使用的话,可能需要额外研究。鉴于你没有付我介绍费(^_^),这里就只做一些简单的介绍啦,剩下的自己去研究吧。
迭代器的分类(Category)
好吧,其实我觉得用了这么久如果你还没感觉到迭代器有几个明显的类别,这是一个悲剧。。
而我将迭代器的分类放在这么靠后的位置介绍,恐怕又是一个悲剧。。
还是老办法,先从一段代码开始吧,一段非常非常简单的代码:
| C++ 代码: |
list<int> li;
// ...然后在这里像li中添加了一些数据
sort(li.begin(),li.end());
你心想这下这段代码肯定悲剧了,既然被揪出来就是要拿来批斗的。。嘿嘿。
可是貌似真没啥问题啊,我不过就是想对list排个序么。有啥不对的。。?
如果你还抱有这种想法,不妨编译一下,看看编译器是怎么说的。。
编译器会上书几百行错误来向你抱怨写出了如此代码。
如果你实在看不出这个代码中有何问题,那么你不妨把list换成vector、deque、map、set甚至string等等,一个个试下,看看编译器会不会都抱怨……
而你会发现这些被抱怨的容器在另外一些算法上却不会遭到抱怨,比如find、copy、transform……
而如果你非常细心的话,又会发现,有些迭代器可以做加减法,有些不可以;有些可以比较大小,有些不可以……
而如果你是既细心又严谨的模范的话,或许某天你会发现,同样的算法,比如distance,在有些迭代器上会很快,有些迭代器上会很慢……
哦哦哦,说到这里,或许你已经大概可能似乎有那么一点点感觉了:迭代器是不一样的。有某种分类。
是的。在STL中,迭代器的确是有明确的分类,同一类的迭代器有着相同的特性和相似的用法。而且迭代器的类别之间有着一定的关系。
在STL中,迭代器分为这么几个类别: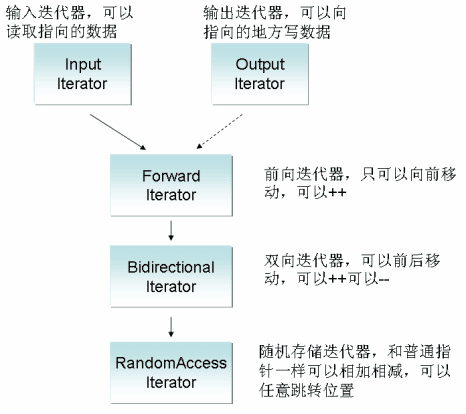
我想这张图片已经很能说明问题了。是的,有五种迭代器,从上往下分别是:
input iterator,输入迭代器
output iterator,输出迭代器
forward iterator,前向迭代器
bidirectional iteraotr,双向迭代器
random access iterator,随机存取迭代器
在图上从上往下,它们有一个继承关系(用箭头来表示):下层的迭代器继承了上层迭代器的能力,因此越下面的迭代器功能越强。(注意:这里的继承不是指OOP中类的继承关系,事实上不同迭代器的类型完全不同,根本无法用类继承来实现。这里的继承仅仅是概念上的功能继承,在C++0x中就可以表示为Concept的继承关系了)
●output iterator,顾名思义,可以向这个迭代器中写入数据。可以++,可以向后挪动位置。
●input iterator,也顾名思义,可以从这个迭代器中读取数据。可以++,可以向后挪动位置。两个此类迭代器之间可以比较是否相等。
这俩迭代器的“读取、写入”功能是所有迭代器的基础。
●forward迭代器,是上述俩迭代器的功能的集大成者,可以读取可以写入(理论上如此,当然实际上还看你是否const)。这是一个具有完整读写功能的向前走的迭代器。
●bidirectional迭代器,更加顾名思义了,在forward迭代器的基础上增加了-- 操作,还可以向前回退位置了。
●random access iterator迭代器,嗯,不用我说了吧。可以随机存取访问。也就是说可以任意跳转。它支持算数运算,也就是operator +、operator -,可以直接从当前位置跳转到之后n个位置或者之前m个位置,而且还支持比较运算符(operator <等),两个迭代器位置之间可以比较大小,看谁在前谁在后。
嗯,你已经发现了,output iterator 到 forward iterator之间为啥是虚箭头啊?呵呵,挺眼尖的。其实这是因为一个细节:forward iterator没有完全继承output iterator的所有功能,只是继承了大部分功能而已。具体细节这里暂不讨论,如果你实在有兴趣的话,可以找找专门的资料看看。
再回头看看上面那个代码的问题,或许你应该猜到了:
是的,list上的迭代器是双向迭代器,而sort算法要求的迭代器却是随机存储迭代器。这样就导致了编译错误。不过由于C++的模版机制的一些不完善性(这其实也怨不得C++,当初所有设计者都想不到之后模版技术居然能被使用的淋漓尽致到这个地步吧……),导致编译器对这种错误极其感冒:一错就错出几百个喷嚏出来。而你在这些四溅的喷嚏飞沫中估计很难找到病原体……只有有经验的医师可以从它打喷嚏的动作猜出可能是啥原因。。
(不过在C++0x中将Concept引入了语法层面,就可以解决这个问题,那时候编译器就会简单的报一句:迭代器类型不对,而不是像现在一样打几百个喷嚏。不过这是额外的话题了,这次不谈)
在STL的标准容器中,所有容器的迭代器都至少提供了双向迭代器的功能。
其中vector、deque的迭代器更进一步——他们是随机存取迭代器。
而我这篇最开始讲的,C++语言原生支持的指针,虽然是最简单的迭代器,但是却最强大的一种——这里你也就明白了,是的,原生指针属于最强大的随机存取迭代器。
之前介绍的那些迭代器配接器,在这里也稍微提下:
reverse iterator:取决于你这个容器本身的迭代器是什么类型。但是至少是bidirectional的(不然我怎么逆向啊?)
insert iterator:属于output iterator;
istream iterator:属于input iterator;
ostream iterator:属于output iterator。
你可以自己对比下这些配接器的功能,就会明白他们为啥归类于这些了。
哎?可是开头的问题还没解决:我如何对一个list排序?
嗯,其实对于这种特殊的无法提供通用算法的容器,只好特殊定制排序算法了。
不过不用担心,不用你来写,大师们已经替你写好了:list本身就有一个成员函数sort()来进行排序。
因此,那个代码这样改就ok啦:
| C++ 代码: |
list<int> li;
// ...然后在这里像li中添加了一些数据
li.sort(); //使用成员函数来进行排序
哦……那我要对map排序也就可以调用map::sort()了?——罚你做100个俯卧撑……算了俯卧撑比较危险还是改练叉腰肌算了……
呃,为啥罚你?map是什么容器?关联式容器——根本无需也不能排序。这种容器内部的元素一经插入,就已经处于有序状态!
假设你还是上面的那个细心而又严谨的你,那么你可能还记得在distance()这种算法中,除了output迭代器,其它类型的迭代器都可以适用,但是效率却有所差别。。这又是怎么一回事呢?
不熟悉distance()的同学,就顺便在这里介绍一下:distance(it1,it2)返回两个迭代器的距离。其实也就是区间[it1,it2)的长度。
显然,对于input、forward和bidirectional迭代器,我们只好一步步往后走同时计数,直到走到终点,看下计数器走了多少步,于是就知道了这俩迭代器的距离。时间复杂度O(n)。
但是对于random access iterator,显然再这么做就太傻B了,既然可以随机访问,我直接相减就可以立即求出二者的距离啊,时间复杂度只要O(1)。
假如你是distance()算法的作者,你会怎么写?
到底用上述哪种方法来实现求距离呢?前一种?不错,这样可以适用于多种迭代器,通用性挺好。可惜对于随机存储迭代器,太浪费时间了。后一种?很好,随机存储迭代器可以非常快的求出距离,但是你却让其它迭代器彻底与你的算法无缘了。
怎么办啊啊啊啊??难道这就是传说中的鱼与熊掌不可得兼?
——谁说的!我明明一边吃着烤鱼一边看着熊掌(在动物园里)……
STL提供的distance就是这么神奇:一方面保证了通用性,另一方面又保证了针对特殊的迭代器,提供最好的效率。
它是怎么实现的呢?对了,你肯定猜到了它的第一步——首先得通过某种方式来识别迭代器的类型。这样才能针对不同的类型来写不同的算法。
类型萃取
是的,就是这个听起来很玄乎的技术——类型萃取技术,或者称为特征(Traits)获取技术。
很神奇的一个技术,你会见识到一些比较高级的模版技巧。
事先提个醒,这里可能有点深,你得需要事先了解模版的偏特化等一些特性,才能比较好的理解这里的内容。
好了我们开始尝试实现这个鱼+熊掌版的distance。
为了能够知道迭代器的类型,我们首先想到了一个办法,那就是和容器一样,要求所有迭代器都遵循一种约定——在迭代器中加入一个枚举变量作为类型标识:
| C++ 代码: |
enum IteratorType
{
input_iterator_type,
output_iterator_type,
forward_iterator_type,
bidirectional_iterator_type,
random_access_iterator_type
};
struct XXXIterator
{
IteratorType type; //定义一个枚举来保存当前迭代器的类型信息,我们便可通过这个变量来知道它的类型
//...其它内容
};
嗯……如果是Java这些动态性比较强的语言这么做也就罢了。。可是C++明明是一个强静态语言,编译器在编译代码时知道的信息很多,这样许多东西完全可以在编译期解决——从而完全不耗费运行时的资源。
特别是模版技术的引入,让我们拥有了能够在编译期完成某些事情的能力。
于是我们再想想,能不能不用上面那种需要运行时判断的方法,把这些工作全部在编译期完成。试着这么尝试下吧:
假设我们先定义这么几个类:
| C++ 代码: |
struct input_iterator_tag{};
struct output_iterator_tag{};
struct forward_iterator_tag{};
struct bidirectional_iterator_tag{};
struct random_access_iterator_tag{};
定义这么多struct干嘛?而且都是空的?有什么用吗?
嘿嘿,这就是我们利用C++强大的类型系统的第一步:将信息类型化。
不太明白?不要紧,接着往下看:
这样我在迭代器的类里面,就可以这么写啦:
| C++ 代码: |
XXXIterator
{
typedef forward_iterator_tag iterator_category;
//...其它内容
};
这样,我们就成功的将之前的那个枚举变量type变成了一个静态的类型iterator_category——你只需查看这个iterator_category到底是哪个类型(它是我们上面定义的那五个空struct类型之一)——你就可以知道这个iterator是什么类别!
你或许会问,这个和一个枚举变量相比有什么好处?
呵呵,好处大大地:首先,枚举变量会占用空间,而这个iterator_category只是一个typedef,换句话说只是一个类型定义,完全不占空间;其次,类型信息是在编译期就可以被确定的,因此编译器可以利用这些信息在编译阶段就完成这些识别和分类工作,这样完全不会耗费运行时的时间来做判断(后面你会看到);再下来就是这个理由:使用类型,便可以清晰的表示迭代器类别之间的继承关系——我们将上面那一堆struct的定义稍微改一下,加点料:
| C++ 代码: |
struct input_iterator_tag{};
struct output_iterator_tag{};
struct forward_iterator_tag:public input_iterator_tag{};
struct bidirectional_iterator_tag:public forward_iterator_tag{};
struct random_access_iterator_tag:public bidirectional_iterator_tag{};
看见了没有?这样这些单纯用来表示类别差异的空struct或class(我们称之为tag类——因为他们就像blog文章中的tag一样,没别的用途,仅用于给别的类标识类型),现在有了明确的继承关系:random_access_iterator_tag继承自bidirectional_iterator_tag,bidirectional_iterator_tag继承自forward_iterator_tag……是不是和之前介绍的迭代器类别那里的图上的关系一样?没错,就是用这种方法,表示了类别的继承特性。(同时你也可以注意到forward_iterator_tag并没有继承自output_iterator_tag,呵呵)
好了,我们这样便可以在一个迭代器中定义一个typedef来标明它所属的迭代器类别了!但是如何识别呢?
if(XXXIterator::iterator_category ==input_iterator_tag)
这样写吗?
显然是错的。类型之间不能用==比较。其实你要换思路:我们根本就不该用if语句——if语句是运行时执行的,而我们要做的是让它在编译期就决定谁是谁,谁该调用谁。
想想吧,C++有什么东西可以在编译期间根据一个类型的不同来决定不同的行为呢?
没错!函数重载!
| C++ 代码: |
void func(int a); //#1
void func(const char*b); //#2
//...
func(1); //这里便可根据参数的不同类型来选择#1或#2不同的版本。
func("a");
我们可以构造一个tag类的变量,然后作为参数传入,便可以利用函数重载来自动绑定到不同的行为了!
来看看distance(可能)是怎么做的吧:
| C++ 代码: |
//先写出distance的两种不同版本的算法:#1和#2
//#1. 这是针对普通迭代器的通用版本
template<typename Iterator>
size_t distance(Iterator it1, Iterator it2, input_iterator_tag tag) //注意最后一个参数
{
size_t d=0;
for( ; it1!=it2; ++it1) //通过循环计数得到距离
{
++d;
}
return d;
}
//#2. 这是针对随机存取迭代器的特殊版本
template<typename Iterator>
size_t distance(Iterator it1, Iterator it2, random_access_iterator_tag tag) //注意最后一个参数
{
return it2 - it1; //直接相减得到距离
}
//#3. 这个才是我们平常调用的那个只有俩参数的distance
template<typename Iterator>
inline size_t distance(Iterator it1, Iterator it2)
{
return distance(it1, it2, Iterator::iterator_category()); //这里,传入一个tag对象,便进行了函数重载
}
aha!太巧妙了!
(如果你没有喊出“aha!”而是喊出了“huh?”,那么请往下看,并在看完下面几段之后再回头仔细看一遍上面的代码)
我们这次人肉运行一下试试:
●第一次人肉运行:
我有两个输入型迭代器(假设类型名叫InputIterator) :it1和it2,我想调用distance求他们的距离,于是我这样写:
distance(it1,it2);
然后发生了什么?编译器一看,俩参数的,于是,调用了上面代码中的#3,并自动推导出模版中的Iterator就是InputIterator。
接下来进入函数,函数内部直接调用了另外一个仨参数的distance,于是编译器开始检查这三个参数。前两个都没啥变化,最后一个多出来的那个参数是什么呢?
编译器一看,Iterator::iterator_category(),哦,原来是构造了一个对象,这个对象是Iterator内部的iterator_category类型啊——那到底是什么类型?
再翻一翻户口簿,记录着:Iterator在这里就是InputIterator,而InputIterator内部有一个:
typedef input_iterator_tag iterator_category;
于是编译器明白了,这个Iterator::iterator_category到头来原来是input_iterator_tag这个类啊。
接下来编译器就好办了:找有没有哪个函数名叫distance,有三个参数,其中第三个参数是input_iterator_tag类型的?哦,有,#1不就是一个吗?于是编译器就决定调用它啦。
这样我们最终就进入了#1的函数内部,然后使用了普通的那种走一步记一步的方式计算出了it1和it2的距离。
●第二次人肉运行:
我有两个前向迭代器(假设类型名叫FowardIterator) :it1和it2,我想调用distance求他们的距离,我还是这样写:
distance(it1,it2);
编译器照样照样找到了#3,调进去一看,还是一样,要找三个参数的函数。不过这次经过查户口,这个FowardIterator里的iterator_category是foward_iterator_tag类型的。编译器大略搜了一下,没发现第三个参数是foward_iterator_tag类型的函数啊,这可咋办捏?又查了查,哦,原来foward_iterator_tag是继承自input_iterator_tag嘛,它俩差不多算一类,就当作input_iterator_tag 处理吧!于是调用了#1,之后就和第一次人肉运行后面的情况一样啦。
●第二点五次人肉运行:
我有两个双向迭代器要求距离……呃呃,鉴于和第二次人肉运行差不多,就不人肉了吧。。
●第三次人肉运行:
这次我拿了俩随机存取迭代器过来了(假设类型名叫RAIterator) :it1, it2。还是想通过distance求距离:
distance(it1,it2);
这次你作为编译器(啊?我啥时候开始人肉编译了?),应该驾轻就熟了,直接找到#3,然后找里面那个函数的第三个参数。这次查户口,发现RAIterator里的iterator_category是random_access_iterator_tag,接着去搜函数,哎呦,正好有一个嘛:#2不就是一个名叫distance并且第三个参数要random_access_iterator_tag类的函数嘛。就是他了,去吧年轻人~~~!
于是我们第三次就用上了it2-it1这种高效的算法。
怎么样?“aha!”了没有?还没有的话再回头去仔细看看代码~~
啊,太帅了,不愧是巧妙的类型萃取技术啊……
别忙!这还不算是类型萃取呢,才是第一步。(啊??搞错没有?!才第一步?)
是啊。虽然目前我们的这种方法工作很好,但是你想想,还有一类最常见最简单的迭代器被我们遗忘了呢——噢……难道是它……
没错,就是它——最简单却最强大的迭代器,指针。上述算法对指针一点用都没有。
为啥没有用?你想想,我们这个方法要区分类型,必须依靠迭代器内部的那个iterator_category类型。自定义的迭代器倒好办,标准一声令下,所有人都得遵守。但是指针你怎么办?你如何给指针加一个iterator_category类型?这下没辙了。。
嘿嘿,有时候你不得不承认有些人不愧是大师,来看看他们拿出的解决方案——类型萃取:
对,到这里才是真正类型萃取的主体,之前的都是前戏~~呵呵。
大师们定义了这么一个东西:
| C++ 代码: |
template <typename T>
struct iterator_traits
{
typedef typename T::value_type value_type; //萃取值的类型
typedef typename T::reference reference_type; //萃取引用的类型
typedef typename T::difference_type difference_type; //萃取距离的类型
typedef typename T::pointer pointer; //萃取指针的类型
typedef typename T::iterator_category iterator_category;//萃取迭代器特征(分类)
};
这个名叫iterator_traits的神奇的struct,你可以称之为迭代器类型萃取器,它可以像化学实验中的那些检测器一样把每个迭代器的各种特征全部检测出来。
于是便可以获取各种迭代器的特征了!
哎,等等——这不过是多了一个typedef而已,有什么用吗?对指针貌似还是没有用啊!
哦,忘了忘了,抱歉,其实上述的iterator_traits仍然是个不完整的,还没有给你们看traits真正强大的一面呢:
iterator_traits强就强在,它可以利用模版特化,为指针单独定制一个版本的萃取器!
| C++ 代码: |
template <typename T>
struct iterator_traits<T*>
{
typedef typename T value_type; //萃取值的类型:就是T
typedef typename T& reference_type; //萃取引用的类型:就是T&
typedef typename ptrdiff_t difference_type; //萃取距离的类型:就是ptrdiff_t
typedef typename T* pointer; //萃取指针的类型:就是T*
typedef typename random_access_iterator_tag iterator_category;//萃取指针迭代器特征(分类):就是随机存取迭代器tag
};
看到没有?模版特化在此处体现了它的强大:假如是指针类型,就会被自动特化成这个版本——而这个版本为指针定义好了各种特性,包括迭代器的类型是随机存取迭代器——因此就轻而易举的获取了指针这种最简单的迭代器的各种特征!
回到之前那个distance的例子:
有了这个iterator_traits,我们就可以将上面的distance代码#3处这么改进:
| C++ 代码: |
template<typename Iterator>
inline size_t distance(Iterator it1, Iterator it2)
{
return distance(it1, it2, iterator_traits<Iterator>::iterator_category()); //使用Traits来获取迭代器的tag
}
还是#3的代码,这次使用iterator_traits来获取iterator_category,如果这个Iterator是一个复杂的迭代器,那么就和之前没有区别;如果这个Iterator是一个简单的指针,那么就会被特化为random_access_iterator_tag,从而一举解决所有的问题!哈哈,爽吧。
这就是类型萃取的魅力所在。
ok,关于它的内容就介绍到这里。如果你还没有看的很懂的话,建议先去温习下函数重载和模版特化的相关知识,然后再回头把这一小节重新仔细看一遍。
另外再做个说明:上述的distance代码有很多不严谨之处,比如返回值不应该简单的写size_t类型,而也应该使用traits来获取当前迭代器的距离类型(difference_type)。但是因为本小节只是为了给大家介绍一下类型萃取技术的原理,因此将这些东西都做了简化以方便阅读。
针对迭代器编程
还记得在(上)篇中我们最后的那个小小的遗憾么?我们想写一个迭代器版的findMin,可是因为无法得知迭代器指向的数据类型而只好作罢。
现在有了类型萃取技术,利用iterator_traits,问题就迎刃而解啦:
| C++ 代码: |
template<typename Iterator>
iterator_traits<Iterator>::value_type findMin(Iterator begin,Iterator end)
{
iterator_traits<Iterator>::value_type tmp; // now it works!!
for(Iterator it=begin;it!=end;++it)
{
if(tmp>(*it)){tmp=(*it);}
}
return tmp;
}
通过简单的使用iterator_traits,我们便可以从迭代器的类型中萃取出更多的信息:比如这次萃取出了迭代器指向位置的元素的类型。
所以说,类型萃取技术,是针对迭代器编程的基础。STL里面大量的算法都使用了这个技术。如果你想针对迭代器编程,那么你也就好好利用这一利器吧!
就像上面iterator_traits定义的那样,迭代器有五种特征。虽然上面的定义已经写明了,不过为了清楚,还是在这里专门列一下吧:
|
|
|
| value_type |
这个迭代器指向的元素的类型 |
| reference_type |
这个迭代器指向的元素的引用类型 |
| difference_type |
两个此类迭代器之间的距离的类型 |
| pointer |
这个迭代器指向的元素的指针类型 |
| iterator_category |
这个迭代器迭代器的特征(分类) |
来一个自己的迭代器怎么样?
嗯,这次介绍了这么多内容,终于把整个《迭代器入门介绍》系列差不多讲完了。如果你看到这里,并且把之前的内容差不多都搞懂的话,我想其实也就差不多理解了一点GP以及STL中针对迭代器编程的思想了吧。
就像最开始说的,STL是一个开放的框架,你可以在遵循一些Concept的前提下扩展这个框架,写自己的算法,写自己的容器,使它们与现有的STL成员良好的协调工作。真是一件美妙的事情啊,不是么?
看了上一小节“针对迭代器编程”,你或许已经大略知道如何为STL扩展算法了。
现在貌似还差如何写一个自己的、可以被STL算法所用的迭代器?
呵呵,那我就在本文的最后,告诉你一个简便的方法吧。
其实STL的最初设计者们就考虑到了之后的扩展性,专门为后人提供了一个类,就叫做:iterator。
你可以通过继承这个类,来实现各种各样的迭代器:
| C++ 代码: |
//我来定义一个指向int型元素的双向迭代器吧~
class MyIterator : public std::iterator<bidirectional_iterator_tag,int>
{
MyIterator();
MyIterator(const MyIterator& val);
~MyIterator();
MyIterator& operator++();
MyIterator& operator--();
MyIterator& operator++(int);
MyIterator& operator--(int);
MyIterator& operator =(const MyIterator& val);
bool operator ==(const MyIterator& val) const ;
//...你可以继续加……呵呵
}
就像上面的例子,通过iterator后面的模版参数就可以指定你要实现的迭代器的类型和其指向元素的类型。
呵呵,很简单吧。手痒了?那就自己来一个试试吧!
嘘~~~~~~~~~ 极其长的迭代器介绍废话,终于被我唠叨完了。介绍系列就到此为止吧~!
还有很多细节没有讲到,就靠大家自己去学习了。我么,还是偷偷懒算了~~(砖~!)
嗯……砖也行啊,还是那句话:如果觉得写的好请顶一下,如果觉得写的搓也请拍一下啊。
到此为止,闪也~
-----------------------
PS:再一次以最严重的程度鄙视CSDN的垃圾blog系统!