用图的存储结构实现ItemCF
其实,网上有很多基于item的协同过滤的方法,对于数据量大的情况下,一般用MapReduce处理,也有基于内存的Spark类MapReduce的处理方式。
由于最近在学GraphX,其实user和Item之间也可以用图的方式去描述,至于为什么要做这么做?会不会多余呢,其实还是可以拥有自己的观点。
其实公式如下,引入了时间因素和同个订单因素:
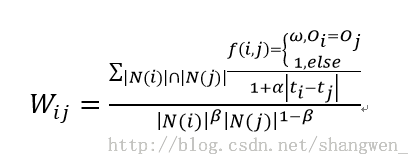
N(i)表示买了i物品的用户数量,分子是买了i物品和j物品的共同用户数,嗯,就类似这个意思,本片文章不是主要详细说公式。
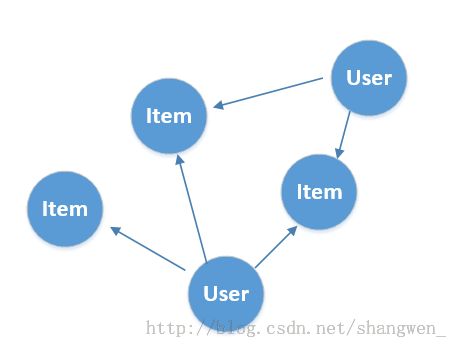
就像图描述的一样,如果user买了Item就有一条用户指向Item的一条边,所以user的邻居就是该user买过的所有商品的集合,而同理的Item的邻居就是买过该商品的User的集合,这样就很容易的计算上面的公式了。
对于Item来说,由于引入了时间因素和订单因素,item作为顶点要存储它属于哪个订单(如果一个订单的两个物品出现的频率高,他们的关联性就认为比较大)和有哪些用户买了它。所以构造了一个Item对象作为它的属性。

userIds记录为用户Id的key和array数组装的是用户多次买了该item的时间戳。
主要代码如下:
class Item extends Serializable {
var itemId = 0L
var orderIds = HashMap[Long, Boolean]()
var userIds = HashMap[Long, ArrayBuffer[Long]]()
def add(orderId: Long, userId: Long, time: Long, vid: Long) = {
itemId = vid
orderIds += (orderId -> true)
if (userIds.get(userId) == None) {
val arr = ArrayBuffer[Long]()
arr.append(time)
userIds += (userId -> arr)
} else {
val item = userIds(userId)
item.append(userId)
}
}
}
熟悉完以上的基本步骤后,那就要开始构造图了,这里主要说说基本的原理:
我们可以通过Edge的RDD转化为图:
构造好图之后,然后我们通过其相应的API收集邻居的节点的Id,和相应节点的属性
好了,对于图来说我们如何确定他是user的顶点还是item的顶点呢?通过观察上面的图可以知道,我们以userId为srcId,itemId为dstId,既user的顶点为所有出度的顶点,item顶点为所有入度的顶点。
// 找出所有Item节点的邻接顶点,该顶点集合即用户的id集合
val itemRDD = newGraph.collectNeighborIds(EdgeDirection.In).filter { case (vid, array) => array.length > 0 }
// 找出所有链接用户顶点的Item的id,和相应的属性
val userRDD = newGraph.collectNeighbors(EdgeDirection.Out).filter { case (vid, array) => array.length > 0 }
得到的结果就类似与 itemRDD = {{item1,Array(user1,user3,user5,...)}.....},而userRDD = {{userId,Array((item1,itemAttr),(item2,item2Attr)) ......} ...... } 等结构。
接下来通过spark的相关操作计算出结果
如下图:
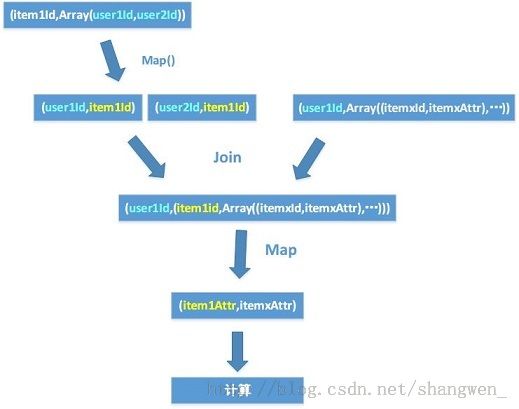
这种方式在数据量少的时候还是可以跑出结果的,但是数据量增大的时候,由于suffle量很大,spark出现了buffer超过Int.MaxValue的问题,这个目前还是个spark上未修复的问题。
解决这个问题的方式是:
1、采取别的编程方式,例如不使用图
2、优化原有的代码,减少suffle
3、可能还是机器少或者环境问题等等。