可以处理负权的单源最短路径的SPFA算法带图详解(自己画的图)
可以处理负权的单源最短路径的SPFA算法带图详解(自己画的图)
算法大致流程是用一个队列来进行维护。 初始时将源加入队列。 每次从队列中取出一个元素,并对所有与他相邻的点进行松弛,若某个相邻的点松弛成功,则将其入队。 直到队列为空时算法结束。
这个算法,简单的说就是队列优化的bellman-ford,利用了每个点不会更新次数太多的特点发明的此算法
SPFA——Shortest Path Faster Algorithm,它可以在O(kE)的时间复杂度内求出源点到其他所有点的最短路径,可以处理负边。SPFA的实现甚至比Dijkstra或者Bellman_Ford还要简单:
设Dist代表S到I点的当前最短距离,Fa代表S到I的当前最短路径中I点之前的一个点的编号。开始时Dist全部为+∞,只有Dist[S]=0,Fa全部为0。
维护一个队列,里面存放所有需要进行迭代的点。初始时队列中只有一个点S。用一个布尔数组记录每个点是否处在队列中。
每次迭代,取出队头的点v,依次枚举从v出发的边v->u,设边的长度为len,判断Dist[v]+len是否小于Dist[u],若小于则改进Dist[u],将Fa[u]记为v,并且由于S到u的最短距离变小了,有可能u可以改进其它的点,所以若u不在队列中,就将它放入队尾。这样一直迭代下去直到队列变空,也就是S到所有的最短距离都确定下来,结束算法。若一个点入队次数超过n,则有负权环。
SPFA 在形式上和宽度优先搜索非常类似,不同的是宽度优先搜索中一个点出了队列就不可能重新进入队列,但是SPFA中一个点可能在出队列之后再次被放入队列,也就是一个点改进过其它的点之后,过了一段时间可能本身被改进,于是再次用来改进其它的点,这样反复迭代下去。设一个点用来作为迭代点对其它点进行改进的平均次数为k,有办法证明对于通常的情况,k在2左右。
SPFA算法(Shortest Path Faster Algorithm),也是求解单源最短路径问题的一种算法,用来解决:给定一个加权有向图G和源点s,对于图G中的任意一点v,求从s到v的最短路径。 SPFA算法是Bellman-Ford算法的一种队列实现,减少了不必要的冗余计算,他的基本算法和Bellman-Ford一样,并且用如下的方法改进: 1、第二步,不是枚举所有节点,而是通过队列来进行优化 设立一个先进先出的队列用来保存待优化的结点,优化时每次取出队首结点u,并且用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在当前的队列中,就将v点放入队尾。这样不断从队列中取出结点来进行松弛操作,直至队列空为止。 2、同时除了通过判断队列是否为空来结束循环,还可以通过下面的方法: 判断有无负环:如果某个点进入队列的次数超过V次则存在负环(SPFA无法处理带负环的图)。
上面的是引用网上的解释。
下面举例子具体说明,如下图:
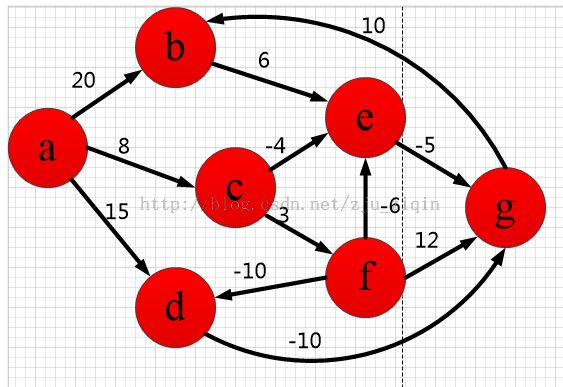
1.a点到其他点的最短路径,首先a点入队:
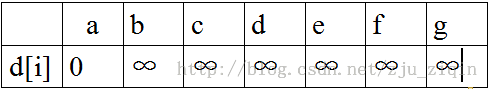
2.a出队,对以a为起始点的所有边的终点依次进行松弛操作(此处有b,c,d三个点),此时路径表格状态为:
在松弛时三个点的最短路径估值变小了,而这些点队列中都没有出现,这些点
需要入队,此时,队列中新入队了三个结点b,c,d
队首元素b点出队,对以b为起始点的所有边的终点依次进行松弛操作(此处只有e点),此时路径表格状态为:

在最短路径表中,e的最短路径估值也变小了,e在队列中不存在,因此e也要
入队,此时队列中的元素为c,d,e
队首元素c点出队,对以c为起始点的所有边的终点依次进行松弛操作(此处有e,f两个点),此时路径表格状态为:

在最短路径表中,e,f的最短路径估值变小了,e在队列中存在,f不存在。因此
e不用入队了,f要入队,此时队列中的元素为d,e,f
队首元素d点出队,对以d为起始点的所有边的终点依次进行松弛操作(此处只有g这个点),此时路径表格状态为:

最短路径表中,g的最短路径变小了,g不在队列中,g入队,此时队列中元素,e,f,g
队首元素e出队,对以e为起始点的所有边的终点依次进行松弛操作,g的最短路径变小了但是g在队列中,因此队列中元素是f,g
此时路径表为:
队首元素f出队,对以f为起始点的所有边的终点依次进行松弛操作,d的最短路径变小了,d不在队列中,放入队列中,队列元素是g,d
此时路径表为:

最后g,d出队都不会引起路径表的变化。。
可得出a到其他点最短路径。