块设备驱动1--自编ramdisk(在linux-3.2.36上的新接口)
这是块设备驱动的第一期,我们就从ldd3的sbull开始吧,但是ldd3用的linux版本太老了,你直接用它的例子在linux-3.2.x上是很麻烦的。
我主要做的就是在高版本上的移植。
里面有个NOQUEUE宏,可以选择不用一个请求队列 。
自己对着ldd3中的讲解看看吧
/***********************************
Copyright(C), 2013 LDP
FileName: bdev.c
Author:
Date:
Description:
History:
Author Date Desc
************************************/
#include <linux/module.h>//MODULE_*
#include <linux/fs.h>//fops
#include <linux/init.h>//printk
#include <linux/slab.h>//kzalloc() kfree()
#include <linux/blkdev.h>//register_blkdev
#include <linux/bio.h>//strucut bio
#include <linux/spinlock.h>//spinlock
#include <linux/hdreg.h> //HDIO_GETGEO
#include <asm/uaccess.h>//copy_to_user
#define DEV_NAME "vDisk"
#define NOQUEUE//不用一个请求队列
#define vDisk_MINORS 1 //磁盘分区数
#define HARDSECT_SIZE 512 //硬件的扇区大小
#define KERNEL_SECTOR_SIZE 512 //内核与快设备驱动交互的扇区单位
#define SECTOR_CNT 1024 //扇区数
/*****************************************************
module description
*****************************************************/
MODULE_LICENSE("GPL");//GPL, GPL v2, GPL and additional rights, Dual BSD/GPL, Dual MPL/GPL, Proprietary.
MODULE_AUTHOR("...");
MODULE_DESCRIPTION("...");
MODULE_VERSION("...");
MODULE_ALIAS("...");
/****************************************************/
static int vDisk_major = 0;
module_param(vDisk_major, int, 0);
/***************************************************/
struct LDP_vDisk
{
int size;
u8 *data;
struct gendisk *gd;
struct request_queue *queue;
bool media_change;
spinlock_t lock;
};
/****************************************************
request operation
****************************************************/
static void vDisk_transfer(struct LDP_vDisk *dev, unsigned long sector,
unsigned long nsect, char *buffer, int write)
{
unsigned long offset = sector * KERNEL_SECTOR_SIZE;
unsigned long nbytes = nsect * KERNEL_SECTOR_SIZE;
if ((offset + nbytes) > dev->size)
{
printk (KERN_NOTICE "Beyond-end write (%ld %ld)\n", offset, nbytes);
return;
}
if (write)
{
memcpy(dev->data + offset, buffer, nbytes);
}
else
{
memcpy(buffer, dev->data + offset, nbytes);
}
}
static int vDisk_xfer_bio(struct LDP_vDisk *dev, struct bio *bio)
{
int i;
struct bio_vec *bvec;
sector_t sector = bio->bi_sector;
char *buffer;
/* Do each segment independently. */
bio_for_each_segment(bvec, bio, i)
{
buffer = __bio_kmap_atomic(bio, i, KM_USER0);
vDisk_transfer(dev, sector, bio_cur_bytes(bio) >> 9, buffer, bio_data_dir(bio) == WRITE);
sector += bio_cur_bytes(bio) >> 9;
__bio_kunmap_atomic(bio, KM_USER0);
}
return 0; /* Always "succeed" */
}
#ifdef NOQUEUE
static void vDisk_make_request(struct request_queue *q, struct bio *bio)
{
struct LDP_vDisk *dev = q->queuedata;
int status;
status = vDisk_xfer_bio(dev, bio);
bio_endio(bio, status);
}
#else
static void vDisk_request(struct request_queue *q)
{
struct request *req;
//int sectors_xferred = 0;
struct bio *bio;
struct LDP_vDisk *dev = q->queuedata;
req = blk_fetch_request(q);
while (req != NULL)
{
if (req->cmd_type != REQ_TYPE_FS)//文件系统请求
{
__blk_end_request_all(req, 1);
continue;
}
__rq_for_each_bio(bio, req)
{
vDisk_xfer_bio(dev, bio);
}
if (!__blk_end_request_cur(req, 0)) //通知设备层,
{
//add_disk_randomness(req->rq_disk);//for random
req = blk_fetch_request(q);
}
}
}
#endif
/***************************************************/
/*
* Open and close.
*/
static int vDisk_open(struct block_device *bdevice, fmode_t fmt)
{
return 0;
}
static int vDisk_release(struct gendisk * gdisk, fmode_t fmt)
{
return 0;
}
static struct gendisk *vdisk_gendisk;
static struct kobject *vdisk_find(dev_t dev, int *part, void *data)
{
*part = 0;
return get_disk(vdisk_gendisk);
}
/*
* The device operations structure.
*/
static struct block_device_operations vDisk_ops = {
.owner = THIS_MODULE,
.open = vDisk_open,
.release = vDisk_release,
};
static struct LDP_vDisk *vDisk_dev = NULL;
static int __init vDisk_init(void)
{
int ret = 0;
vDisk_dev = kzalloc(sizeof(struct LDP_vDisk), GFP_KERNEL);
if (vDisk_dev == NULL)
{
ret = -ENOMEM;
goto fail5;
}
vDisk_dev->size = SECTOR_CNT * HARDSECT_SIZE;
vDisk_dev->data = kzalloc(vDisk_dev->size, GFP_KERNEL);
if (vDisk_dev->data == NULL)
{
ret = -ENOMEM;
goto fail4;
}
spin_lock_init(&vDisk_dev->lock);
vDisk_dev->media_change = 0;
vdisk_gendisk = vDisk_dev->gd = alloc_disk(vDisk_MINORS);
if (vDisk_dev->gd == NULL)
{
ret = -1;
goto fail3;
}
vDisk_major = register_blkdev(vDisk_major, DEV_NAME);
if (vDisk_major <= 0)
{
ret = -EIO;
goto fail2;
}
#ifdef NOQUEUE
vDisk_dev->queue = blk_alloc_queue(GFP_KERNEL);
if (vDisk_dev->queue == NULL)
{
ret = -1;
goto fail1;
}
blk_queue_make_request(vDisk_dev->queue, vDisk_make_request);
#else
vDisk_dev->queue = blk_init_queue(vDisk_request, &vDisk_dev->lock);
if (vDisk_dev->queue == NULL)
{
ret = -1;
goto fail1;
}
#endif
//blk_queue_logical_block_size(vDisk_dev->queue, HARDSECT_SIZE);
blk_queue_max_hw_sectors(vDisk_dev->queue, SECTOR_CNT);
vDisk_dev->queue->queuedata = vDisk_dev;
vDisk_dev->gd->major = vDisk_major;
vDisk_dev->gd->first_minor = 0;
vDisk_dev->gd->fops = &vDisk_ops;
vDisk_dev->gd->queue = vDisk_dev->queue;
vDisk_dev->gd->private_data = vDisk_dev;
snprintf (vDisk_dev->gd->disk_name, 32, DEV_NAME);
set_capacity(vDisk_dev->gd, SECTOR_CNT * (HARDSECT_SIZE / KERNEL_SECTOR_SIZE));
add_disk(vDisk_dev->gd);
blk_register_region(MKDEV(vDisk_major, 0), 1, THIS_MODULE, vdisk_find, NULL, NULL);
return ret;
fail1:
unregister_blkdev(vDisk_major, DEV_NAME);
fail2:
del_gendisk(vDisk_dev->gd);
fail3:
kfree(vDisk_dev->data);
fail4:
kfree(vDisk_dev);
fail5:
return ret;
}
static void __exit vDisk_exit(void)
{
blk_unregister_region(MKDEV(vDisk_major, 0), 1);
if (vDisk_dev->gd)
{
del_gendisk(vDisk_dev->gd);
put_disk(vDisk_dev->gd);
}
#ifdef NOQUEUE
blk_put_queue(vDisk_dev->queue);
#else
blk_cleanup_queue(vDisk_dev->queue);
#endif
unregister_blkdev(vDisk_major, DEV_NAME);
kfree(vDisk_dev->data);
kfree(vDisk_dev);
}
module_init(vDisk_init);
module_exit(vDisk_exit);
我的板子遇到这个问题。
http://blog.chinaunix.net/uid-22731254-id-3948456.html
已解决!
你可以想我的方法执行:
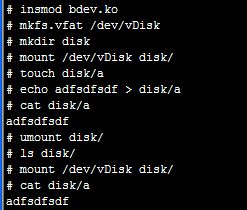
内核中的ramdisk使用的就是不用一个请求队列,原因:ldd3原话
前面, 我们已经讨论了内核所作的在队列中优化请求顺序的工作; 这个工作包括排列请求和, 或许, 甚至延迟队列来允许一个预期的请求到达. 这些技术在
处理一个真正的旋转的磁盘驱动器时有助于系统的性能. 但是, 使用一个象 sbull 的设备它们是完全浪费了. 许多面向块的设备, 例如闪存阵列, 用于数
字相机的存储卡的读取器, 并且 RAM 盘真正地有随机存取的性能, 包含从高级的请求队列逻辑中获益. 其他设备, 例如软件 RAID 阵列或者被逻辑卷管理
者创建的虚拟磁盘, 没有这个块层的请求队列被优化的性能特征. 对于这类设备, 它最好直接从块层接收请求, 并且根本不去烦请求队列.
我顺便说一下,内核中IO调度的电梯算法有:
as(Anticipatory)
cfq(Complete Fairness Queueing)
deadline
noop(No Operation)
看我的虚拟机的
[root@localhost ramdisk]# cat /sys/block/hdc/queue/scheduler
noop anticipatory deadline [cfq]
你可以看一下/sys/block/ram0/下,没有queue。
对于我的例子,你可以选有或没有。
在嵌入式板子上,即使你选择有queue,也不一定涉及电梯算法,因为你还须别的配置。
我的板子就没有
# cat /sys/block/vDisk/queue/scheduler
none
思考:
你可以想想如何修改vDisk_transfer,让一个i2c接口的eeprom(不过要够大),变成一个块设备