CT-压缩跟踪Compressive Tracking
转自:http://blog.csdn.net/zouxy09/article/details/8118360
Real-time Compressive Tracking简称CT
官网网址:http://www4.comp.polyu.edu.hk/~cslzhang/CT/CT.htm
一、实时压缩跟踪:
感谢香港理工大学的Kaihua Zhang,这是他即将在ECCV 2012上出现的paper:Real-timeCompressive Tracking。这里是他的介绍:
一种简单高效地基于压缩感知的跟踪算法。首先利用符合压缩感知RIP条件的随机感知矩对多尺度图像特征进行降维,然后在降维后的特征上采用简单的朴素贝叶斯分类器进行分类。该跟踪算法非常简单,但是实验结果很鲁棒,速度大概能到达40帧/秒。
实际上,感觉上面这几句话的介绍已经高度的概括了这个论文的主要思想。和一般的模式分类架构一样:先提取图像的特征,再通过分类器对其分类,不同在于这里特征提取采用压缩感知,分类器采用朴素贝叶斯。然后每帧通过在线学习更新分类器。当然,里面还包含着很多细节的推导和优化了,下面我们从论文中一起来学习一下。
上一博文中提到compressive sensing的主要原理就是用一个随机感知矩阵去降维一个高维信号,得到的低维信号可以完全保持高维信号的特性。这个随机感知矩阵要满足CS理论的RIP条件就可以完全从低维信号重建高维信号。
二、主要思想:
我再啰嗦一下:通过稀疏感知理论可以知道,我们通过一个满足RIP条件的非常稀疏的测量矩阵对原图像特征空间做投影,就可以得到一个低维压缩子空间。低维压缩子空间可以很好的保留高维图像特征空间的信息。所以我们通过稀疏测量矩阵去提取前景目标和背景的特征,作为在线学习更新分类器的正样本和负样本,然后使用该朴素贝叶斯分类器去分类下一帧图像的目标待测图像片(感知空间下)。
三、具体工作过程如下:
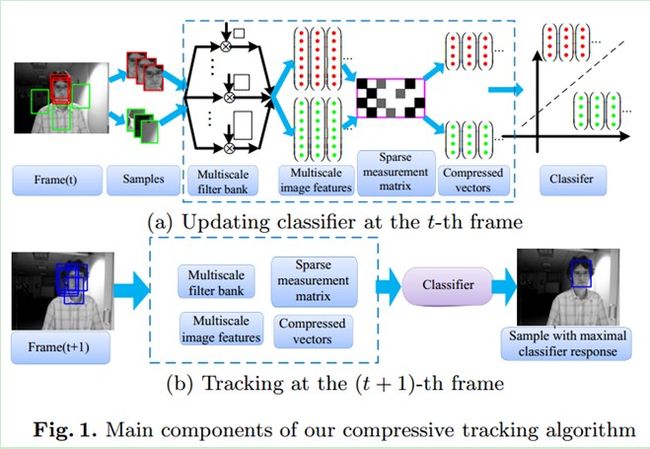
(1)在t帧的时候,我们采样得到若干张目标(正样本)和背景(负样本)的图像片,然后对他们进行多尺度变换,再通过一个稀疏测量矩阵对多尺度图像特征进行降维,然后通过降维后的特征(包括目标和背景,属二分类问题)去训练朴素贝叶斯分类器。
(2)在t+1帧的时候,我们在上一帧跟踪到的目标位置的周围采样n个扫描窗口(避免去扫描整幅图像),通过同样的稀疏测量矩阵对其降维,提取特征,然后用第t帧训练好的朴素贝叶斯分类器进行分类,分类分数最大的窗口就认为是目标窗口。这样就实现了从t帧到t+1帧的目标跟踪。
四、相关理论推导:
4.1、随机投影:
一个n x m的随机矩阵R,它可以将一个高维图像空间的x(m维)变换到一个低维的空间v(n维),数学表达就是:v = R x
在这里n远远小于m(这样才叫降维嘛)。最理想的情况,我们当然希望低维的v可以完全的保留高维的x的信息,或者说保持原始空间中各样本x的距离关系,这样在低维空间进行分类才有意义。
Johnson-Lindenstrauss推论表明:可以随机选择一个适当的高维子空间(当然,需要比原始空间维度小),原始空间两点的距离投影到这个子空间,能高概率的保留这种距离关系。(K+1次测量足以精确复原N维空间的K-稀疏信号)。
而Baraniuk证明了满足Johnson-Lindenstrauss推论的随机矩阵同样满足压缩感知理论中的restricted isometry property(RIP)条件。所以,如果随机矩阵R满足Johnson-Lindenstrauss推论,那么如果x是可压缩的(或者说是稀疏的),我们就可以通过最小化误差来从v中高概率恢复x。
所以原文就找到了一个非常稀疏的投影矩阵,不但满足Johnson-Lindenstrauss推论,而且可以高效的实时计算。
4.2、随机测量矩阵:
一个比较典型的满足RIP条件的测量矩阵是随机高斯矩阵,矩阵元素满足N(0,1)分布。但是,如果m的维数比较大的话,这个矩阵还是比较稠密的,它的运算和存储消耗还是比较大的。而在原文,采用了一个非常稀疏的随机测量矩阵,其矩阵元素定义为:
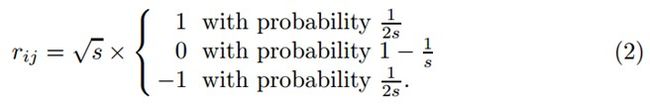
Achlioptas证明了,上式s取2或者3时,矩阵就满足Johnson-Lindenstrauss推论。这个矩阵非常容易计算,因为它只需要一个均匀随机数发生器就行,而且当s=3时,这个矩阵非常稀疏,计算量将会减少2/3。如果s=3,那么矩阵元素有1/6的概率为1.732(表示根号3,懒得插入公式了),有1/6的概率为-1.732,有2/3的概率为0;
本文中s=m/4,矩阵R的每一行只需要计算c(小于4)个元素的值。所以它的计算复杂度为O(cn)。另外,我们只需要存储R的非零元素即可,所以所需存储空间也很少。
4.3、提出的算法:
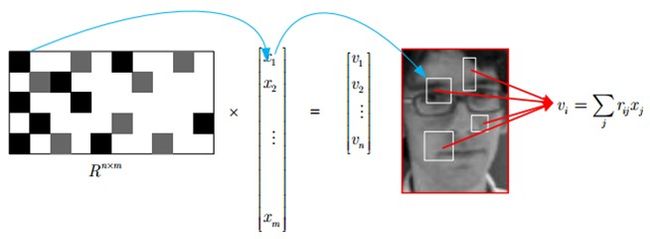
上图表明一个n x m的稀疏矩阵,它可以将一个高维图像空间的x(m维)变换到一个低维的空间v(n维),数学表达就是:v = R x ;
其中,矩阵R中,黑色、灰色和白色分别代表矩阵元素为负数、正数和零。蓝色箭头表示测量矩阵R的一行的一个非零元素感知x中的一个元素,等价于一个方形窗口滤波器和输入图像某一固定位置的灰度卷积。
为了实现尺度不变性,对每一个样本z∊Rwxh,通过将其与一系列多尺度的矩形滤波器{h1,1,…,hw,h}进行卷积,每一种尺度的矩形滤波器定义如下:
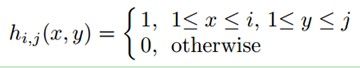
式中,i和j分别是矩形滤波器(模版)的宽和高。然后将滤波后的的图像矩阵展成一个wxh维的列向量。再将这些列向量连接成一个非常高维((wxh)2维)的多尺度图像特征向量x=(x1,…,xm)T。维数一般在10的6次方到10次方之间。
我们通过采用上面的稀疏随机矩阵R将x投影到低维空间的v。这个随机矩阵R只需要在程序启动时计算一次,然后在跟踪过程中保持不变。通过积分图,我们可以高效的计算v。
4.4、低维压缩特征的分析:
低维特征v的每一个元素vi是不同尺度的空间分布特征的线性组合。由于测量矩阵R的系数可正,可负,所以压缩特征可以像广义Haar-like特征一样计算相关灰度差。Haar-like特征的计算比较耗时,传统方法是通过boosting算法选择重要的特征来减少需要计算的特征数。本文中,我们通过稀疏测量矩阵对这些数目庞大的Haar-like特征进行压缩,稀疏感知理论保证了,压缩后的特征几乎保留原有图像的信息。因此,我们可以直接对压缩空间里面的投影特征进行分类,而避免了维数灾难。
4.5、分类器构建和更新:
对每个样本z(m维向量),它的低维表示是v(n维向量,n远小于m)。假定v中的各元素是独立分布的。可以通过朴素贝叶斯分类器来建模。
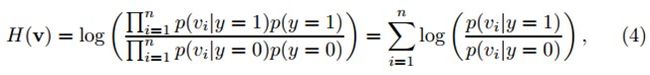
其中,y∊{0,1}代表样本标签,y=0表示负样本,y=1表示正样本,假设两个类的先验概率相等。p(y=1)=p(y=0)=0.5。Diaconis和Freedman证明了高维随机向量的随机投影几乎都是高斯分布的。因此,我们假定在分类器H(v)中的条件概率p(vi|y=1)和p(vi|y=0)也属于高斯分布,并且可以用四个参数来描述:
![]()
上式中的四个参数会进行增量更新:
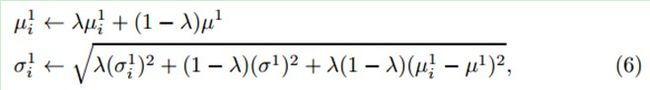
式中,学习因子λ>0,![]()
上式可以由最大化似然估计得到。
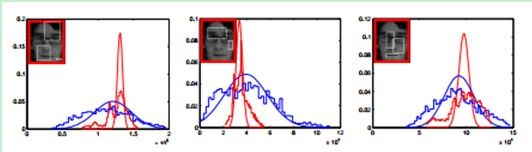
图中显示了从某帧中的正样本和负样本提取出的三个不同特征(低维空间下)的概率分布。红色和蓝色阶梯线分别代表正样本和负样本的直方图。而红色和蓝色的曲线表示通过我们的增量更新模型得到的相应的分布估计。图说明了在投影空间,通过上式描述的在线更新的高斯分布模型是特征的一个良好估计。
五、压缩跟踪算法:
输入:第t帧图像
1、在t-1帧跟踪到的目标位置It-1的周围(也就是满足Dγ={z|||l(z)−lt−1||<γ,与It-1距离小于γ)采样n个图像片,然后对这些图像片进行特征提取(降维),得到每个图像片的特征向量v。
2、使用式(4)中分类器H(v)对这些v进行分类,找到最大分类分数的图像片作为当前帧跟踪到的目标,位置为It;
3、采样两个样本集:Dα= {z|||l(z) − lt|| < α}和 Dζ ,β= {z|ζ < ||l(z)−lt|| <β}其中,α< ζ < β;
4、提取上述两个样本集的特征,通过式(6)来更新分类器参数。
输出:跟踪到的目标位置It和更新后的分类器参数。