聚类算法-Hierarchical(MIN)-C++
程序流程图:
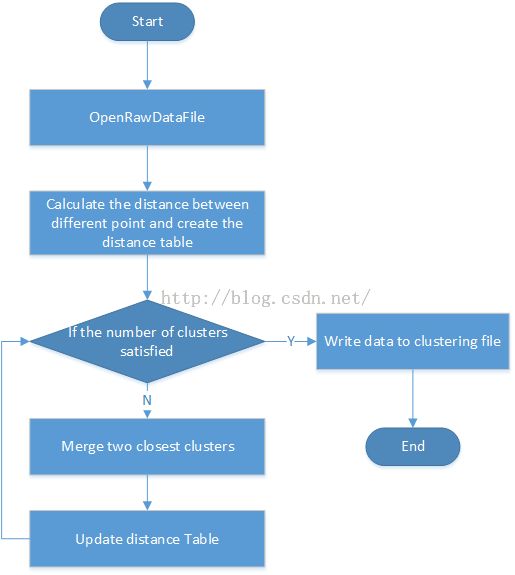
Hierarchical(MIN)核心功能函数,采用vector<vector<float> >::dTable存储两点之间的距离。计算每两个point间的距离并保存到distance table中;判断是否达到需要聚类的cluster数量,若是,将point信息写入clustering文件,程序结束。否则,合并两个具有最小距离的point,将两个point中的所有node全部加入到一个point中,删除拷贝node数组后的多余point,跟新dataset数组。然后更新distance table,删除被合并point对应的distance table中行与列,进入下一步循环。
/*
K-means Algorithm
15S103182
Ethan
*/
#include <iostream>
#include <sstream>
#include <fstream>
#include <vector>
#include <iterator>
#include <cmath>
#include <stack>
#include <limits>
using namespace std;
class node{
public:
float x;
float y;
node(float a,float b){
x = a;
y = b;
}
};
class point{
public:
float x;
float y;
vector<node> nds;
point (float a,float b){
x = a;
y = b;
node t(a,b);
nds.push_back(t);
}
};
float stringToFloat(string i){
stringstream sf;
float score=0;
sf<<i;
sf>>score;
return score;
}
vector<point> openFile(const char* dataset){
fstream file;
file.open(dataset,ios::in);
if(!file)
{
cout <<"Open File Failed!" <<endl;
vector<point> a;
return a;
}
vector<point> data;
while(!file.eof()){
string temp;
file>>temp;
int split = temp.find(',',0);
point p(stringToFloat(temp.substr(0,split)),stringToFloat(temp.substr(split+1,temp.length()-1)));
data.push_back(p);
}
file.close();
cout<<"Read data successfully!"<<endl;
return data;
}
float squareDistance(point a,point b){
return sqrt((a.x-b.x)*(a.x-b.x)+(a.y-b.y)*(a.y-b.y));
}
void HierarchicalClustering(vector<point> dataset,int clusters){
//Similarity table:distance table
vector<vector<float> > dTable;
for(int i=0;i<dataset.size();i++){
vector<float> temp;
for(int j=0;j<dataset.size();j++){
if(j>i)
temp.push_back(squareDistance(dataset[i],dataset[j]));
else if(j<i)
temp.push_back(dTable[j][i]);
else
temp.push_back(0);
}
dTable.push_back(temp);
}
int len = dataset.size();
cout<<"len:"<<len<<endl;
while(dataset.size()>clusters){
//Merge two closest clusters
float minDt =INT_MAX;
int mi,mj;
for(int i=0;i<dTable.size();i++){
for(int j=i+1;j<dTable[i].size();j++){
if(dTable[i][j]<minDt){
minDt = dTable[i][j];
mi = i;
mj = j;
}
}
}
for(int i=0;i<dataset[mj].nds.size();i++){
dataset[mi].nds.push_back(dataset[mj].nds[i]);
}
//rm
vector<point>::iterator imj = dataset.begin();
imj += mj;
dataset.erase(imj);
//Update the dTable
for(int j=0;j<dTable.size();j++){
if(j==mi||j==mj) continue;
if(dTable[mi][j]>dTable[mj][j]){
dTable[mi][j] = dTable[mj][j];
dTable[j][mi] = dTable[mi][j];
}
}
//rm
vector<vector<float> >::iterator ii = dTable.begin();
ii += mj;
dTable.erase(ii);
for(int i=0;i<dTable.size();i++){
vector<float>::iterator ij = dTable[i].begin();
ij += mj;
dTable[i].erase(ij);
}
}
fstream clustering;
clustering.open("clustering.txt",ios::out);
for(int i=0;i<dataset.size();i++){
for(int j=0;j<dataset[i].nds.size();j++)
clustering<<dataset[i].nds[j].x<<","<<dataset[i].nds[j].y<<","<<i+1<<"\n";
}
cout<<dataset.size();
clustering.close();
}
int main(int argc, char** argv) {
vector<point> dataset = openFile("dataset3.txt");
HierarchicalClustering(dataset,15);
return 0;
}
数据文件格式:(x,y)
运行结果格式:(x,y,cluster)
具体文件格式见DBSCAN篇:http://blog.csdn.net/k76853/article/details/50440182
图形化展现:
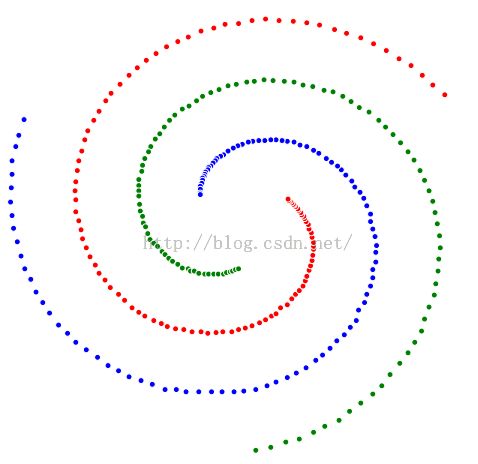
总结:
Hierarchical(MIN)算法能够很好处理非圆形状的数据。但对于噪音和离群点,Hierarchical(MIN)算法具有局限性。由于层次聚类具有不可恢复性,一旦聚类,就难以撤销聚类操作,刚开始编码的时候走了不少弯路,后来果断决定用数组存储node信息,方便cluster合并。对于近邻表的更新,也遇到一点小麻烦,由于二级指针对于行列的删除比较复杂,果断采用动态数组vector来存储距离信息,二级vector对于行的删除非常直接简单,对于列的删除也只需O(n)操作,比较简洁高效。