HBase源码分析之HRegion上MemStore的flsuh流程(二)
继上篇《HBase源码分析之HRegion上MemStore的flsuh流程(一)》之后,我们继续分析下HRegion上MemStore flush的核心方法internalFlushcache(),它的主要流程如图所示:
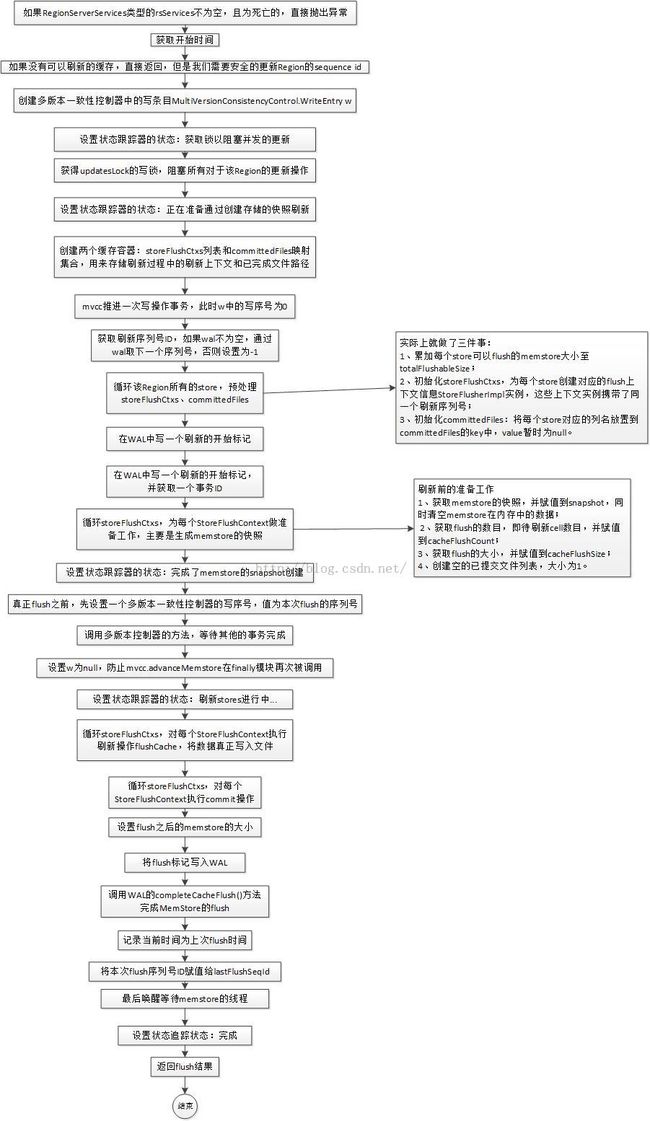
其中,internalFlushcache()方法的代码如下:
/**
* Flush the memstore. Flushing the memstore is a little tricky. We have a lot of updates in the
* memstore, all of which have also been written to the wal. We need to write those updates in the
* memstore out to disk, while being able to process reads/writes as much as possible during the
* flush operation.
* <p>This method may block for some time. Every time you call it, we up the regions
* sequence id even if we don't flush; i.e. the returned region id will be at least one larger
* than the last edit applied to this region. The returned id does not refer to an actual edit.
* The returned id can be used for say installing a bulk loaded file just ahead of the last hfile
* that was the result of this flush, etc.
* @return object describing the flush's state
*
* @throws IOException general io exceptions
* @throws DroppedSnapshotException Thrown when replay of wal is required
* because a Snapshot was not properly persisted.
*/
protected FlushResult internalFlushcache(MonitoredTask status)
throws IOException {
return internalFlushcache(this.wal, -1, status);
}
/**
* @param wal Null if we're NOT to go via wal.
* @param myseqid The seqid to use if <code>wal</code> is null writing out flush file.
* @return object describing the flush's state
* @throws IOException
* @see #internalFlushcache(MonitoredTask)
*/
protected FlushResult internalFlushcache(
final WAL wal, final long myseqid, MonitoredTask status) throws IOException {
// 如果RegionServerServices类型的rsServices不为空,且为夭折的,直接抛出异常
if (this.rsServices != null && this.rsServices.isAborted()) {
// Don't flush when server aborting, it's unsafe
throw new IOException("Aborting flush because server is aborted...");
}
// 获取开始时间
final long startTime = EnvironmentEdgeManager.currentTime();
// If nothing to flush, return, but we need to safely update the region sequence id
// 如果没有可以刷新的缓存,直接返回,但是我们需要安全的更新Region的sequence id
if (this.memstoreSize.get() <= 0) {
// Take an update lock because am about to change the sequence id and we want the sequence id
// to be at the border of the empty memstore.
// 获取一个更新锁,因为我们即将要更新一个序列ID,并且我们想让这个序列ID成为一个空的memstore的边界
MultiVersionConsistencyControl.WriteEntry w = null;
// 获取更新锁的写锁
this.updatesLock.writeLock().lock();
try {
if (this.memstoreSize.get() <= 0) {
// Presume that if there are still no edits in the memstore, then there are no edits for
// this region out in the WAL subsystem so no need to do any trickery clearing out
// edits in the WAL system. Up the sequence number so the resulting flush id is for
// sure just beyond the last appended region edit (useful as a marker when bulk loading,
// etc.)
// wal can be null replaying edits.
// 假设如果有memstore仍然没有数据,
if (wal != null) {
w = mvcc.beginMemstoreInsert();
long flushSeqId = getNextSequenceId(wal);
FlushResult flushResult = new FlushResult(
FlushResult.Result.CANNOT_FLUSH_MEMSTORE_EMPTY, flushSeqId, "Nothing to flush");
w.setWriteNumber(flushSeqId);
mvcc.waitForPreviousTransactionsComplete(w);
w = null;
return flushResult;
} else {
return new FlushResult(FlushResult.Result.CANNOT_FLUSH_MEMSTORE_EMPTY,
"Nothing to flush");
}
}
} finally {
this.updatesLock.writeLock().unlock();
if (w != null) {
mvcc.advanceMemstore(w);
}
}
}
LOG.info("Started memstore flush for " + this +
", current region memstore size " +
StringUtils.byteDesc(this.memstoreSize.get()) +
((wal != null)? "": "; wal is null, using passed sequenceid=" + myseqid));
// Stop updates while we snapshot the memstore of all of these regions' stores. We only have
// to do this for a moment. It is quick. We also set the memstore size to zero here before we
// allow updates again so its value will represent the size of the updates received
// during flush
// 当我们更新所有这些region存储的memstore的快照时,停止更新操作。
// 我们这样做一瞬间,它是非常迅速的。
// 在我们允许再次更新时,我们也设置memstore的大小为0,所以它的大小也代表了在flush期间接收到的更新的大小
// 创建多版本一致性控制器中的写条目
MultiVersionConsistencyControl.WriteEntry w = null;
// We have to take an update lock during snapshot, or else a write could end up in both snapshot
// and memstore (makes it difficult to do atomic rows then)
// 我们需要在快照期间的一个更新锁,否则一个写入最终在快照与内存之前完成(届时将很难做原子行的保证)
// 获得锁以阻塞并发的更新
// 设置状态跟踪器的状态:获取锁以阻塞并发的更新
status.setStatus("Obtaining lock to block concurrent updates");
// block waiting for the lock for internal flush
// 阻塞,等待flush的锁
// 获得updatesLock的写锁,阻塞所有对于该Region的更新操作。
this.updatesLock.writeLock().lock();
long totalFlushableSize = 0;
// 设置状态跟踪器的状态:正在准备通过创建存储的快照刷新
status.setStatus("Preparing to flush by snapshotting stores in " +
getRegionInfo().getEncodedName());
// 创建两个缓存容器:storeFlushCtxs列表和committedFiles映射集合,用来存储刷新过程中的刷新上下文和已完成文件路径
List<StoreFlushContext> storeFlushCtxs = new ArrayList<StoreFlushContext>(stores.size());
TreeMap<byte[], List<Path>> committedFiles = new TreeMap<byte[], List<Path>>(
Bytes.BYTES_COMPARATOR);
// 刷新的序列号ID
long flushSeqId = -1L;
long trxId = 0;
try {
try {
// mvcc推进一次写操作事务,此时w中的写序号为0
w = mvcc.beginMemstoreInsert();
// 获取刷新序列号ID,如果wal不为空,通过wal取下一个序列号,否则设置为-1
if (wal != null) {// 如果wal不为空
// startCacheFlush实际上做了两件事:
// 1、调用closeBarrier.beginOp()方法,确定开始一个flush操作;
// 2、Region名对应的最近序列化Id从数据结构
// oldestUnflushedRegionSequenceIds移动到lowestFlushingRegionSequenceIds中
// 疑问:oldestUnflushedRegionSequenceIds中数据是何时放入的?用它来做什么呢?
// 在FSHLog的append()方法中,如果entry.isInMemstore(),putIfAbsent放入的
if (!wal.startCacheFlush(this.getRegionInfo().getEncodedNameAsBytes())) {
// This should never happen.
String msg = "Flush will not be started for ["
+ this.getRegionInfo().getEncodedName() + "] - because the WAL is closing.";
status.setStatus(msg);
return new FlushResult(FlushResult.Result.CANNOT_FLUSH, msg);
}
// Get a sequence id that we can use to denote the flush. It will be one beyond the last
// edit that made it into the hfile (the below does not add an edit, it just asks the
// WAL system to return next sequence edit).
// wal不为空的话,获取下一个序列号
flushSeqId = getNextSequenceId(wal);
} else {
// use the provided sequence Id as WAL is not being used for this flush.
// 这里myseqid传递进来的是-1
flushSeqId = myseqid;
}
// 循环该Region所有的store,预处理storeFlushCtxs、committedFiles
// 1、累加每个store可以flush的memstore大小至totalFlushableSize;
// 2、初始化storeFlushCtxs,为每个store创建对应的flush上下文信息StoreFlusherImpl实例,这些上下文实例携带了同一个刷新序列号
// 2、将每个store对应的StoreFlushContext添加到ArrayList列表storeFlushCtxs中,实际生成的是StoreFlusherImpl实例
// 3、将每个store对应的FamilyName添加到TreeMap集合committedFiles中,以备
// 3、初始化committedFiles:将每个store对应的列名放置到committedFiles的key中,value暂时为null
for (Store s : stores.values()) {
totalFlushableSize += s.getFlushableSize();
// 这里只是构造一个StoreFlusherImpl对象,该对象只有cacheFlushSeqNum一个变量被初始化为flushSeqId
// 然后,加入到storeFlushCtxs列表
storeFlushCtxs.add(s.createFlushContext(flushSeqId));
committedFiles.put(s.getFamily().getName(), null); // for writing stores to WAL
}
// write the snapshot start to WAL
// 在WAL中写一个刷新的开始标记,并获取一个事务ID
if (wal != null) {
// 其实就是往WAL中append一条记录:row为Region所在的startKey,
// family为METAFAMILY,
// qualifier为HBASE::FLUSH,
// value为FlushDescriptor
FlushDescriptor desc = ProtobufUtil.toFlushDescriptor(FlushAction.START_FLUSH,
getRegionInfo(), flushSeqId, committedFiles);
trxId = WALUtil.writeFlushMarker(wal, this.htableDescriptor, getRegionInfo(),
desc, sequenceId, false); // no sync. Sync is below where we do not hold the updates lock
}
// Prepare flush (take a snapshot)
// 循环storeFlushCtxs,为每个StoreFlushContext做准备工作,主要是生成memstore的快照
for (StoreFlushContext flush : storeFlushCtxs) {
/**
* 刷新前的准备工作
* 1、获取memstore的快照,并赋值到snapshot;
* 2、获取flush的数目,即待刷新cell数目,并赋值到cacheFlushCount;
* 3、获取flush的大小,并赋值到cacheFlushSize;
* 4、创建空的已提交文件列表,大小为1。
*/
flush.prepare();
}
} catch (IOException ex) {
if (wal != null) {
if (trxId > 0) { // check whether we have already written START_FLUSH to WAL
try {
FlushDescriptor desc = ProtobufUtil.toFlushDescriptor(FlushAction.ABORT_FLUSH,
getRegionInfo(), flushSeqId, committedFiles);
WALUtil.writeFlushMarker(wal, this.htableDescriptor, getRegionInfo(),
desc, sequenceId, false);
} catch (Throwable t) {
LOG.warn("Received unexpected exception trying to write ABORT_FLUSH marker to WAL:" +
StringUtils.stringifyException(t));
// ignore this since we will be aborting the RS with DSE.
}
}
// we have called wal.startCacheFlush(), now we have to abort it
// 我们已经调用了wal的startCacheFlush()方法,现在我们不得不放弃它。
// 1、将Region名对应的SeqId从数据结构lowestFlushingRegionSequenceIds移回至oldestUnflushedRegionSequenceIds
// 2、调用closeBarrier.endOp(),终止一个操作
wal.abortCacheFlush(this.getRegionInfo().getEncodedNameAsBytes());
throw ex; // let upper layers deal with it.
}
} finally {
// 快照创建好后,释放写锁updatesLock
this.updatesLock.writeLock().unlock();
}
// 设置状态跟踪器的状态:完成了memstore的snapshot创建
String s = "Finished memstore snapshotting " + this +
", syncing WAL and waiting on mvcc, flushsize=" + totalFlushableSize;
status.setStatus(s);
if (LOG.isTraceEnabled()) LOG.trace(s);
// sync unflushed WAL changes
// see HBASE-8208 for details
if (wal != null) {
try {
wal.sync(); // ensure that flush marker is sync'ed
} catch (IOException ioe) {
LOG.warn("Unexpected exception while wal.sync(), ignoring. Exception: "
+ StringUtils.stringifyException(ioe));
}
}
// wait for all in-progress transactions to commit to WAL before
// we can start the flush. This prevents
// uncommitted transactions from being written into HFiles.
// We have to block before we start the flush, otherwise keys that
// were removed via a rollbackMemstore could be written to Hfiles.
// 在我们可以开始flush之前等待所有进行中的事务提交到WAL。这可以防止未提交的事务被写入HFiles。
// 我们在开始刷新之前,不得不阻塞,否则通过一个rollbackMemstore被删除的keys可能被写入到Hfiles。
// 真正flush之前,先设置一个多版本一致性控制器的写序号,值为本次flush的序列号
w.setWriteNumber(flushSeqId);
// 然后,调用多版本控制器的方法,等待其他的事务完成
mvcc.waitForPreviousTransactionsComplete(w);
// set w to null to prevent mvcc.advanceMemstore from being called again inside finally block
// 设置w为null,防止mvcc.advanceMemstore在finally模块再次被调用
w = null;
// 设置状态跟踪器的状态:刷新stores进行中...
s = "Flushing stores of " + this;
status.setStatus(s);
if (LOG.isTraceEnabled()) LOG.trace(s);
} finally {
if (w != null) {
// in case of failure just mark current w as complete
// 失败的情况下,标记当前w为已完成
mvcc.advanceMemstore(w);
}
}
// Any failure from here on out will be catastrophic requiring server
// restart so wal content can be replayed and put back into the memstore.
// Otherwise, the snapshot content while backed up in the wal, it will not
// be part of the current running servers state.
boolean compactionRequested = false;
try {
// A. Flush memstore to all the HStores.
// Keep running vector of all store files that includes both old and the
// just-made new flush store file. The new flushed file is still in the
// tmp directory.
// 循环storeFlushCtxs,对每个StoreFlushContext执行刷新操作flushCache,将数据真正写入文件
for (StoreFlushContext flush : storeFlushCtxs) {
// 调用HStore对象的flushCache()方法,将数据真正写入文件
flush.flushCache(status);
}
// Switch snapshot (in memstore) -> new hfile (thus causing
// all the store scanners to reset/reseek).
Iterator<Store> it = stores.values().iterator(); // stores.values() and storeFlushCtxs have
// same order
// 循环storeFlushCtxs,对每个StoreFlushContext执行commit操作
for (StoreFlushContext flush : storeFlushCtxs) {
boolean needsCompaction = flush.commit(status);
if (needsCompaction) {
compactionRequested = true;
}
committedFiles.put(it.next().getFamily().getName(), flush.getCommittedFiles());
}
storeFlushCtxs.clear();
// Set down the memstore size by amount of flush.
// 设置flush之后的memstore的大小
this.addAndGetGlobalMemstoreSize(-totalFlushableSize);
if (wal != null) {
// write flush marker to WAL. If fail, we should throw DroppedSnapshotException
// 将flush标记写入WAL,同时执行sync
FlushDescriptor desc = ProtobufUtil.toFlushDescriptor(FlushAction.COMMIT_FLUSH,
getRegionInfo(), flushSeqId, committedFiles);
WALUtil.writeFlushMarker(wal, this.htableDescriptor, getRegionInfo(),
desc, sequenceId, true);
}
} catch (Throwable t) {
// An exception here means that the snapshot was not persisted.
// The wal needs to be replayed so its content is restored to memstore.
// Currently, only a server restart will do this.
// We used to only catch IOEs but its possible that we'd get other
// exceptions -- e.g. HBASE-659 was about an NPE -- so now we catch
// all and sundry.
if (wal != null) {
try {
FlushDescriptor desc = ProtobufUtil.toFlushDescriptor(FlushAction.ABORT_FLUSH,
getRegionInfo(), flushSeqId, committedFiles);
WALUtil.writeFlushMarker(wal, this.htableDescriptor, getRegionInfo(),
desc, sequenceId, false);
} catch (Throwable ex) {
LOG.warn("Received unexpected exception trying to write ABORT_FLUSH marker to WAL:" +
StringUtils.stringifyException(ex));
// ignore this since we will be aborting the RS with DSE.
}
wal.abortCacheFlush(this.getRegionInfo().getEncodedNameAsBytes());
}
DroppedSnapshotException dse = new DroppedSnapshotException("region: " +
Bytes.toStringBinary(getRegionName()));
dse.initCause(t);
status.abort("Flush failed: " + StringUtils.stringifyException(t));
// Callers for flushcache() should catch DroppedSnapshotException and abort the region server.
// However, since we may have the region read lock, we cannot call close(true) here since
// we cannot promote to a write lock. Instead we are setting closing so that all other region
// operations except for close will be rejected.
this.closing.set(true);
if (rsServices != null) {
// This is a safeguard against the case where the caller fails to explicitly handle aborting
rsServices.abort("Replay of WAL required. Forcing server shutdown", dse);
}
throw dse;
}
// If we get to here, the HStores have been written.
if (wal != null) {
// 调用WAL的completeCacheFlush()方法完成MemStore的flush
// 将Region对应的最近一次序列化ID从数据结构lowestFlushingRegionSequenceIds中删除
// 调用closeBarrier.endOp()终止一个操作
wal.completeCacheFlush(this.getRegionInfo().getEncodedNameAsBytes());
}
// Record latest flush time
// 记录当前时间为上次flush时间
this.lastFlushTime = EnvironmentEdgeManager.currentTime();
// Update the last flushed sequence id for region. TODO: This is dup'd inside the WAL/FSHlog.
// 将本次flush序列号ID赋值给lastFlushSeqId
this.lastFlushSeqId = flushSeqId;
// C. Finally notify anyone waiting on memstore to clear:
// e.g. checkResources().
// 最后唤醒等待memstore的线程
synchronized (this) {
notifyAll(); // FindBugs NN_NAKED_NOTIFY
}
long time = EnvironmentEdgeManager.currentTime() - startTime;
long memstoresize = this.memstoreSize.get();
String msg = "Finished memstore flush of ~" +
StringUtils.byteDesc(totalFlushableSize) + "/" + totalFlushableSize +
", currentsize=" +
StringUtils.byteDesc(memstoresize) + "/" + memstoresize +
" for region " + this + " in " + time + "ms, sequenceid=" + flushSeqId +
", compaction requested=" + compactionRequested +
((wal == null)? "; wal=null": "");
LOG.info(msg);
// 设置状态追踪状态:完成
status.setStatus(msg);
// 返回flush结果
return new FlushResult(compactionRequested ? FlushResult.Result.FLUSHED_COMPACTION_NEEDED :
FlushResult.Result.FLUSHED_NO_COMPACTION_NEEDED, flushSeqId);
}
又是一个大方法。莫慌,我们慢慢来分析:
1、首先,需要判断下HRegion上的RegionServer相关的服务是否正常;
2、获取开始时间,方便记录耗时,以体现系统的性能;
3、如果没有可以刷新的缓存,直接返回,但是我们需要安全的更新Region的sequence id;
4、设置状态跟踪器的状态:获取锁以阻塞并发的更新,即Obtaining lock to block concurrent updates;
5、获得updatesLock的写锁,阻塞所有对于该Region上数据的更新操作,注意,这里用的是updatesLock,而不是lock;
6、设置状态跟踪器的状态:正在准备通过创建存储的快照刷新,即Preparing to flush by snapshotting stores in...;
7、创建两个缓存容器:storeFlushCtxs列表和committedFiles映射集合,用来存储刷新过程中的刷新上下文和已完成文件路径;
8、创建刷新的序列号ID,即flushSeqId,初始化为-1;
9、mvcc推进一次写操作事务,此时w中的写序号为0,获得多版本一致性控制器中的写条目;
10、获取刷新序列号ID,如果wal不为空,通过wal取下一个序列号,否则设置为-1:
10.1、调用wal的startCacheFlush()方法,在HRegion上开启一个flush操作:
10.1.1、调用closeBarrier.beginOp()方法,确定开始一个flush操作;
10.1.2、Region名对应的最近序列化Id从数据结构oldestUnflushedRegionSequenceIds移动到lowestFlushingRegionSequenceIds中;
10.2、 wal不为空的话,获取下一个序列号,赋值给flushSeqId;
11、循环该Region所有的store,预处理storeFlushCtxs、committedFiles:
11.1、累加每个store可以flush的memstore大小至totalFlushableSize;
11.2、将每个store对应的StoreFlushContext添加到ArrayList列表storeFlushCtxs中,实际生成的是StoreFlusherImpl实例,该对象只有cacheFlushSeqNum一个变量被初始化为flushSeqId;
11.3、初始化committedFiles:将每个store对应的列名放置到committedFiles的key中,value暂时为null;
12、在WAL中写一个刷新的开始标记,并获取一个事务ID--trxId,其实就是往WAL中append一条记录:row为Region所在的startKey,family为METAFAMILY,qualifier为HBASE::FLUSH,value为FlushDescriptor;
13、循环storeFlushCtxs,为每个StoreFlushContext做准备工作,主要是生成memstore的快照,刷新前的准备工作如下:
13.1、获取memstore的快照,并赋值到snapshot;
13.2、获取flush的数目,即待刷新cell数目,并赋值到cacheFlushCount;
13.3、获取flush的大小,并赋值到cacheFlushSize;
13.4、创建空的已提交文件列表,大小为1;
14、快照创建好后,释放写锁updatesLock;
15、设置状态跟踪器的状态:完成了memstore的snapshot创建;
16、真正flush之前,先设置一个多版本一致性控制器的写序号,值为本次flush的序列号;
17、然后,调用多版本控制器的方法,等待其他的事务完成;
18、设置w为null,防止mvcc.advanceMemstore在finally模块再次被调用;
19、设置状态跟踪器的状态:刷新stores进行中...;
20、失败的情况下,标记当前w为已完成;
21、循环storeFlushCtxs,对每个StoreFlushContext执行刷新操作flushCache,将数据真正写入文件:
21.1、调用HStore对象的flushCache()方法,将数据真正写入文件;
22、循环storeFlushCtxs,对每个StoreFlushContext执行commit操作;
23、设置flush之后的memstore的大小,减去totalFlushableSize;
24、将flush标记写入WAL,同时执行sync;
25、调用WAL的completeCacheFlush()方法完成MemStore的flush:将Region对应的最近一次序列化ID从数据结构lowestFlushingRegionSequenceIds中删除,并调用closeBarrier.endOp()终止一个操作;
26、记录当前时间为上次flush时间;
27、将本次flush序列号ID赋值给lastFlushSeqId;
28、最后唤醒等待memstore的线程;
29、设置状态追踪状态:完成;
30、返回flush结果。
我的天哪!在没有考虑异常的情况下,居然有整整30个步骤!这样一看,显得很啰嗦、麻烦,我们不如化繁为简,把握主体流程。实际上,整个flush的核心流程不外乎以下几大步骤:
第一步,上锁,标记状态,而且是上了两把锁:外层是控制HRegion整体行为的锁lock,内层是控制HRegion读写的锁updatesLock;
第二步,获取flush的序列化ID,并通过多版本一致性控制器mvcc推进一次写事务;
第三步,通过closeBarrier.beginOp()在HRegion上开启一个操作,避免其他操作(比如compact、split等)同时执行;
第四步,在WAL中写一个flush的开始标记,并获取一个事务ID;
第五步,生成memstore的快照;
第六步,快照创建好后,释放第一把锁updatesLock,此时客户端又可以发起读写请求;
第七步,利用多版本一致性控制器mvcc等待其他事务完成;
第八步,将数据真正写入文件,并提交;
第九步,在WAL中写一个flush的结束标记;
第十步,通过调用closeBarrier.endOp()在HRegion上终止一个操作,允许其他操作继续执行。
这样的话,我们看着就比较顺,比较简单了。不得不说,整个flush设计的还是比较严谨和巧妙地。为什么这么说呢?
首先,严谨之处体现在,宏观上,它利用closeBarrier.beginOp()和closeBarrier.endOp()很好的控制了HRegion上的多种整体行为,比如flush、compact、split等操作,使其不相互冲突;微观上,针对HRegion上,增加了updatesLock锁,使得数据的更新在flush期间不能进行,保证了数据的准确性;同时,还利用序列号在WAL中标记开始与结束,使得在flush过程中,如果出现异常,系统也能知道开始flush之后数据发生的变化,因为WAL的序列号是递增的,最后,也利用了多版本一致性控制器,保障了写数据时读数据的一致性和完整性,关于多版本一致性控制器相关的内容,将会撰写专门的文章进行介绍,请读者莫急。
其次,巧妙之处体现在,flush流程采用采用了两把锁,使得Region内部的行为和对外的服务互不影响,同时,利用快照技术,快速生成即将被flush的内存,生成之后立马释放控制写数据的写锁,极大地提高了HBase高并发低延迟的写性能。
这里,先简单说下写锁和快照的引入,是如何体现HBase高并发写的性能的。
整个flush的过程是比较繁琐,同时涉及到写真正的物理文件,也是比较耗时的。试想下,如果我们对整个flush过程全程加写锁,结果会怎么样?针对该HRegion的数据读写请求就必须等待整个flush过程的结束,那么对于客户端来说,将不得不经常陷入莫名其妙的等待。
通过对MemStore生成快照snapshot,并在生成前加更新锁updatesLock的写锁,阻止客户端对MemStore数据的读取与更新,确保了数据的一致性,同时,在快照snapshot生成后,立即释放更新锁updatesLock的写锁,让客户端的后续读写请求与快照flush到物理磁盘文件同步进行,使得客户端的访问请求得到快速的响应,不得不说是HBase团队一个巧妙地设计,也值得我们在以后的系统开发过程中借鉴。
身体是革命的本钱,不早了,要保证在12点前睡觉啊,还是先休息吧!剩下的细节,只能寄希望于(三)和其他博文了!