你不再需要动态网页——编辑-发布-开发分离
尽管没有特别的动力去构建一个全新的CMS,但是我还是愿意去撰文一篇来书写如何去做这样的事——编辑-发布-开发分离模式是如何工作的。微服务是我们对于复杂应用的一种趋势,编辑-发布-开发分离模式则是另外一种趋势。在上篇文章《Repractise架构篇一: CMS的重构与演进》中,我们说到编辑-发布-开发分离模式。
系统架构
如先前提到的,Carrot使用了下面的方案来搭建他们的静态内容的CMS。
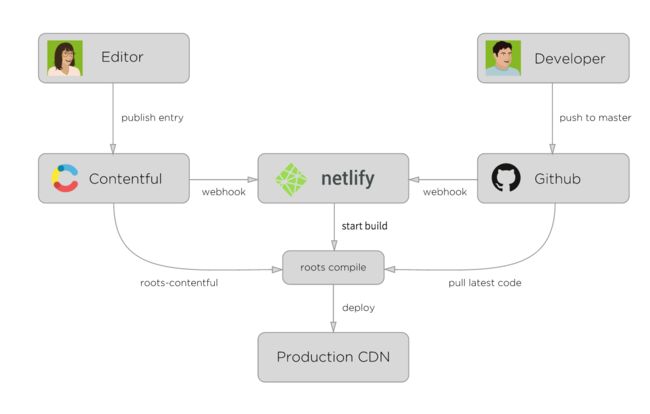
在这个方案里内容是用Contentful来发布他们的内容。而在我司ThoughtWorks的官网里则采用了Github来管理这些内容。于是如果让我们写一个基于Github的CMS,那么架构变成了这样:
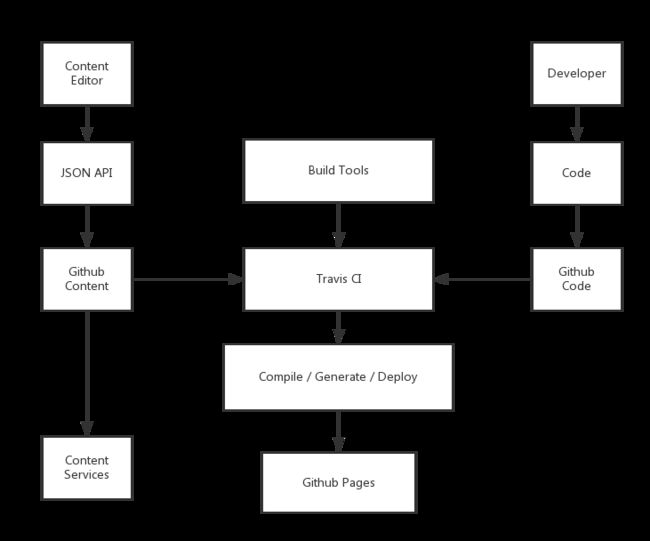
或许你也用过Hexo / Jekyll / Octopress这样的静态博客,他们的原理都是类似的。我们有一个代码库用于生成静态页面,然后这些静态页面会被PUSH到Github Pages上。
从我们设计系统的角度来说,我们会在Github上有三个代码库:
- Content。用于存放编辑器生成的JSON文件,这样我们就可以GET这些资源,并用Backbone / Angular / React 这些前端框架来搭建SPA。
- Code。开发者在这里存放他们的代码,如主题、静态文件生成器、资源文件等等。
- Builder。在这里它是运行于Travis CI上的一些脚本文件,用于Clone代码,并执行Code中的脚本。
以及一些额外的服务,当且仅当你有一些额外的功能需求的时候。
- Extend Service。当我们需要搜索服务时,我们就需要这样的一些服务。如我正考虑使用Python的whoosh来完成这个功能,这时候我计划用Flask框架,但是只是计划中——因为没有合适的中间件。
- Editor。相比于前面的那些知识这一步适合更重要,也就是为什么生成的格式是JSON而不是Markdown的原理。对于非程序员来说,要熟练掌握Markdown不是一件容易的事。于是,一个考虑中的方案就是使用 Electron + Node.js来生成API,最后通过GitHub API V3来实现上传。
So,这一个过程是如何进行的。
用户场景
整个过程的Pipeline如下所示:
- 编辑使用他们的编辑器来编辑的内容并点击发布,然后这个内容就可以通过GitHub API上传到Content这个Repo里。
- 这时候需要有一个WebHooks监测到了Content代码库的变化,便运行Builder这个代码库的Travis CI。
- 这个Builder脚本首先,会设置一些基本的git配置。然后clone Content和Code的代码,接着运行构建命令,生成新的内容。
- 然后Builder Commit内容,并PUSH内容。
这里还依赖于WebHook这个东西——还没想到一个合适的解决方案。下面,我们对里面的内容进行一些拆解,Content里面由于是JSON就不多解释了。
Builder: 构建工具
Github与Travis之间,可以做一个自动部署的工具。相信已经有很多人在Github上玩过这样的东西——先在Github上生成Token,然后用travis加密:
travis encrypt-file ssh_key --add加密后的Key就会保存到.travis.yml文件里,然后就可以在Travis CI上push你的代码到Github上了。
接着,你需要创建个deploy脚本,并且在after_success执行它:
after_success:
- test $TRAVIS_PULL_REQUEST == "false" && test $TRAVIS_BRANCH == "master" && bash deploy.sh在这个脚本里,你所需要做的就是clone content和code中的代码,并执行code中的生成脚本,生成新的内容后,提交代码。
#!/bin/bash
set -o errexit -o nounset
rev=$(git rev-parse --short HEAD)
cd stage/
git init
git config user.name "Robot"
git config user.email "[email protected]"
git remote add upstream "https://$GH_TOKEN@github.com/phodal-archive/echeveria-deploy.git"
git fetch upstream
git reset upstream/gh-pages
git clone https://github.com/phodal-archive/echeveria-deploy code
git clone https://github.com/phodal-archive/echeveria-content content
pwd
cp -a content/contents code/content
cd code
npm install
npm install grunt-cli -g
grunt
mv dest/* ../
cd ../
rm -rf code
rm -rf content
touch .
if [ ! -f CNAME ]; then
echo "deploy.baimizhou.net" > CNAME
fi
git add -A .
git commit -m "rebuild pages at ${rev}"
git push -q upstream HEAD:gh-pages这就是这个builder做的事情——其中最主要的一个任务是grunt,它所做的就是:
grunt.registerTask('default', ['clean', 'assemble', 'copy']);Code: 静态页面生成
Assemble是一个使用Node.js,Grunt.js,Gulp,Yeoman 等来实现的静态网页生成系统。这样的生成器有很多,Zurb Foundation, Zurb Ink, Less.js / lesscss.org, Topcoat, Web Experience Toolkit等组织都使用这个工具来生成。这个工具似乎上个Release在一年多以前,现在正在开始0.6。虽然,这并不重要,但是还是顺便一说。
我们所要做的就是在我们的Gruntfile.js中写相应的生成代码。
assemble: {
options: {
flatten: true,
partials: ['templates/includes/*.hbs'],
layoutdir: 'templates/layouts',
data: 'content/blogs.json',
layout: 'default.hbs'
},
site: {
files: {'dest/': ['templates/*.hbs']}
},
blogs: {
options: {
flatten: true,
layoutdir: 'templates/layouts',
data: 'content/*.json',
partials: ['templates/includes/*.hbs'],
pages: pages
},
files: [
{ dest: './dest/blog/', src: '!*' }
]
}
}配置中的site用于生成页面相关的内容,blogs则可以根据json文件的文件名生成对就的html文件存储到blog目录中。
生成后的目录结果如下图所示:
.
├── about.html
├── blog
│ ├── blog-posts.html
│ └── blogs.html
├── blog.html
├── css
│ ├── images
│ │ └── banner.jpg
│ └── style.css
├── index.html
└── js
├── jquery.min.js
└── script.js
7 directories, 30 files这里的静态文件内容就是最后我们要发布的内容。
还需要做的一件事情就是:
grunt.registerTask('dev', ['default', 'connect:server', 'watch:site']);用于开发阶段这样的代码就够了,这个和你使用WebPack + React 似乎相差不了多少。
编辑-发布-开发分离
在这种情形中,编辑能否完成工作就不依赖于网站——脱稿又少了 个借口。这时候网站出错的概率太小了——你不需要一个缓存服务器、HTTP服务器,由于没有动态生成的内容,你也不需要守护进程。这些内容都是静态文件,你可以将他们放在任何可以提供静态文件托管的地方——CloudFront、S3等等。或者你再相信自己的服务器,Nginx可是全球第二好(第一还没出现)的静态文件服务器。
开发人员只在需要的时候去修改网站的一些内容。
So,你可能会担心如果这时候修改的东西有问题了怎么办。
- 使用这种模式就意味着你需要有测试来覆盖这些构建工具、生成工具。
- 相比于自己的代码,别人的CMS更可靠?
需要注意的是如果你上一次构建成功,你生成的文件都是正常的,那么你只需要回滚开发相关的代码即可。旧的代码仍然可以工作得很好。
其次,由于生成的是静态文件,查错的成本就比较低。
最后,重新放上之前的静态文件。