MapReduce的input为小文件和har文件的相关实验
如果MapReduce的input是一些小文件(文件size小于hdfs的默认block大小),那么MapReduce job将会为每一个小文件开启一个单独的map——最后导致有大量的map,而每一个map其实只处理一小部分数据,却花了很大的时间在map自身的启动和停止上。
以下的实验将会验证小文件数量对map数量的影响,以及input为har文件时map数量的情况。
实验一:WordCount——input为5个小文件
执行WordCount job:$hadoop jar hadoop-example.jar wordcount /input01 /output01
Job执行完后,我们可以看到该Job一共启动了5个map:
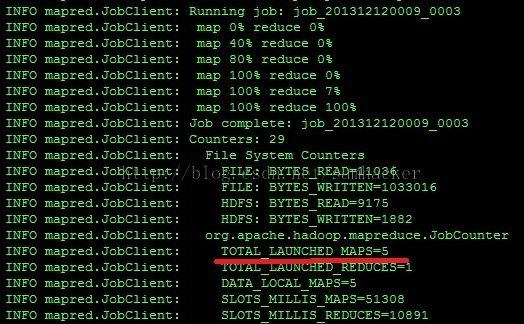
实验二:WordCount——input为6个小文件
执行WordCount job:$hadoop jar hadoop-example.jar wordcount /input01 /output01
Job执行完后,我们可以看到该Job一共启动了6个map:
实验三:WordCount——input为1个har文件,它包含了6个小文件
首先,我们把上面的6个小文件打包成为一个har文件:
hadoop archive -archiveName files.har -p /input01 /input-har
查看该har文件:
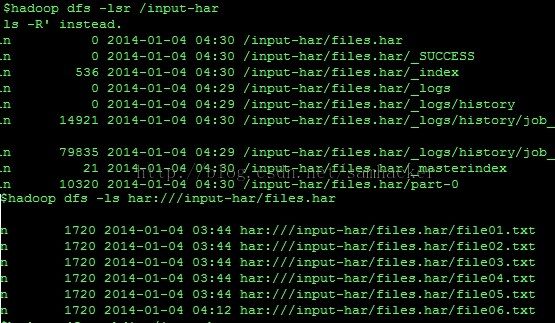
执行WordCount job:$hadoop jar hadoop-example.jar wordcount har://hdfs-host:9000/input-hars/files.har /output-hars
Job执行完后,我们可以看到该Job同样根据har包中的小文件数量一共启动了6个map:
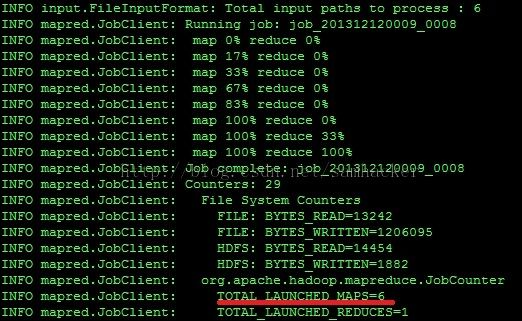
从MapReduce job的角度看,har 文件并没有带来什么变化。但是,由于使用har文件归档小文件,hdfs上的文件数变少了,namenode的压力也变小了。