Hive:ORC File Format存储格式详解
Hive:ORC File Format存储格式详解
在Hive中,我们应该都听过RCFile这种格式吧,关于这种文件格式的结构什么的我就不介绍了,感兴趣的可以去网上找找。今天这篇文章要说的主题是ORC File。
一、定义
ORC File,它的全名是Optimized Row Columnar (ORC) file,其实就是对RCFile做了一些优化。据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。
和RCFile格式相比,ORC File格式有以下优点:
(1)、每个task只输出单个文件,这样可以减少NameNode的负载;
(2)、支持各种复杂的数据类型,比如: datetime, decimal, 以及一些复杂类型(struct, list, map, and union);
(3)、在文件中存储了一些轻量级的索引数据;
(4)、基于数据类型的块模式压缩:a、integer类型的列用行程长度编码(run-length encoding);b、String类型的列用字典编码(dictionary encoding);
(5)、用多个互相独立的RecordReaders并行读相同的文件;
(6)、无需扫描markers就可以分割文件;
(7)、绑定读写所需要的内存;
(8)、metadata的存储是用 Protocol Buffers的,所以它支持添加和删除一些列。
二、ORC File文件结构
ORC File包含一组组的行数据,称为stripes,除此之外,ORC File的file footer还包含一些额外的辅助信息。在ORC File文件的最后,有一个被称为postscript的区,它主要是用来存储压缩参数及压缩页脚的大小。
在默认情况下,一个stripe的大小为250MB。大尺寸的stripes使得从HDFS读数据更高效。
在file footer里面包含了该ORC File文件中stripes的信息,每个stripe中有多少行,以及每列的数据类型。当然,它里面还包含了列级别的一些聚合的结果,比如:count, min, max, and sum。下图显示出可ORC File文件结构:
ORC File Format
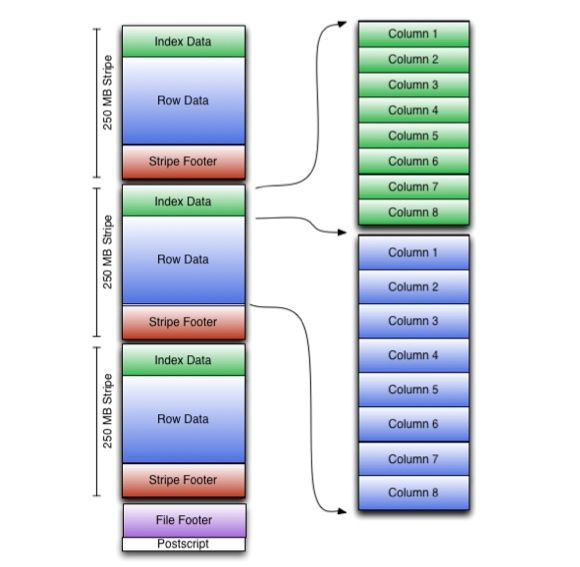 

三、Stripe结构
从上图我们可以看出,每个Stripe都包含index data、row data以及stripe footer。Stripe footer包含流位置的目录;Row data在表扫描的时候会用到。
Index data包含每列的最大和最小值以及每列所在的行。行索引里面提供了偏移量,它可以跳到正确的压缩块位置。具有相对频繁的行索引,使得在stripe中快速读取的过程中可以跳过很多行,尽管这个stripe的大小很大。在默认情况下,最大可以跳过10000行。拥有通过过滤谓词而跳过大量的行的能力,你可以在表的 secondary keys 进行排序,从而可以大幅减少执行时间。比如你的表的主分区是交易日期,那么你可以对次分区(state、zip code以及last name)进行排序。
四、Hive里面如何用ORCFile
在建Hive表的时候我们就应该指定文件的存储格式。所以你可以在Hive QL语句里面指定用ORCFile这种文件格式,如下:
CREATE TABLE ... STORED AS ORC ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC SET hive.default.fileformat=Orc
所有关于ORCFile的参数都是在Hive QL语句的TBLPROPERTIES字段里面出现,他们是:
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.stripe.size | 268435456 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
下面的例子是建立一个没有启用压缩的ORCFile的表
create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties ("orc.compress"="NONE");
五、序列化和压缩
对ORCFile文件中的列进行压缩是基于这列的数据类型是integer或者string。具体什么序列化我就不涉及了。。想深入了解的可以看看下面的英文:
Integer Column Serialization
Integer columns are serialized in two streams.
1、present bit stream: is the value non-null?
2、data stream: a stream of integers
Integer data is serialized in a way that takes advantage of the common distribution of numbers:
1、Integers are encoded using a variable-width encoding that has fewer bytes for small integers.
2、Repeated values are run-length encoded.
3、Values that differ by a constant in the range (-128 to 127) are run-length encoded.
The variable-width encoding is based on Google's protocol buffers and uses the high bit to represent whether this byte is not the last and the lower 7 bits to encode data. To encode negative numbers, a zigzag encoding is used where 0, -1, 1, -2, and 2 map into 0, 1, 2, 3, 4, and 5 respectively.
Each set of numbers is encoded this way:
1、If the first byte (b0) is negative:
-b0 variable-length integers follow.
2、If the first byte (b0) is positive:
it represents b0 + 3 repeated integers
the second byte (-128 to +127) is added between each repetition
1 variable-length integer.
In run-length encoding, the first byte specifies run length and whether the values are literals or duplicates. Duplicates can step by -128 to +128. Run-length encoding uses protobuf style variable-length integers.
String Column Serialization
Serialization of string columns uses a dictionary to form unique column values The dictionary is sorted to speed up predicate filtering and improve compression ratios.
String columns are serialized in four streams.
1、present bit stream: is the value non-null?
2、dictionary data: the bytes for the strings
3、dictionary length: the length of each entry
4、row data: the row values
Both the dictionary length and the row values are run length encoded streams of integers.
本博客文章除特别声明,全部都是原创!
尊重原创,转载请注明: 转载自过往记忆(http://www.iteblog.com/)
本文链接: 【Hive:ORC File Format存储格式详解】(http://www.iteblog.com/archives/1014)