【深度学习介绍系列之一】——深度强化学习
前言介绍了机器学习与深度学习的基本概念,本系列的目录,深度学习的优势等。
本节乘热打铁先说说深度强化学习吧。
说到机器学习最酷的分支,非Deep learning和Reinforcement learning莫属(以下分别简称DL和RL)。这两者不仅在实际应用中表现的很酷,在机器学习理论中也有不俗的表现。深度强化学习是啥呢?简单点说就是 深度学习 + 强化学习。深度学习和强化学习都不是啥新鲜事了,但是深度强化学习在Google 的DeepMind团队的运作下,一下子变得非常红火了。这是源自 DeepMind团队在《Nature》杂志发表论文(Human-level control through deep reinforcement learning),公布玩游戏比人厉害的 AI 是如何做出来的。他们在Stella模拟机上让机器自己玩了7个Atari 2600的游戏,结果是玩的冲出美洲,走向世界,超越了物种的局限。不仅战胜了其他机器人,甚至在其中3个游戏中超越了人类游戏专家。根据他们的论文,其中的AI就是深度强化算法,而且结果比其他算法要好,当然比人也要好,同时这篇论文发表在世界级顶级杂志,引发很多人的兴趣,我当然就是很多人之一,我本来是想如何将此算法应用到公司产品中去,但是最近也没想到啥好的解决方案,那就先熟悉熟悉这种算法了,顺便记录一下。(引用了http://36kr.com/p/220012.html 与 http://www.infoq.com/cn/articles/atari-reinforcement-learning)
为了让大家能稍微详细的了解深度强化学习算法,我们先分别介绍强化学习算法与深度学习算法,再说说他们如何结合的,最后大概总结下。
首先我们说说什么是强化学习吧。百度百科的定义:强化学习(reinforcement learning,又称再励学习,评价学习)是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。 一听起来挺抽象的啊!我们来举个例子简单说明下强化学习在生活中是咋样的:我们小时候看到马戏团的狗尽然可以算加减法,鸽子也会走钢丝了,就差猪也会飞了(扯远了),这是如何做到的?其实啊,拿鸽子来说,每当鸽子走到钢丝尽头或者中间某时刻(可以设计)的时候,训练人员就会给它一些奖励,这些奖励的作用是让它“知道”,鸽子啊,你刚才的动作是对的(或者是不错的,你要继续保持啊)。如此一来,鸽子无形之中就受到了暗示,我只要那样做,就有奖励(食物)吃。何乐而不为呢。如果你看懂了这段话,那么强化学习的通俗理解正是如此!这样一说大概了解了吧,强化学习本质就是告诉你什么情况下做什么决定是有利的,做什么决定是有害的,当遇到类似的情况的时候,你就根据之前的经验来做决策。
现在来点学术点的描述:强化学习其实就是一个连续决策的过程。传统的机器学习中的监督学习(supervised learning)就是给定一些标注数据,这些标注作为监督者(supervisor),学习一个好的函数,来对未知数据作出很好的决策。但是有时候你不知道标注是什么,即一开始不知道什么是“好”的结果,所以RL不是给定标注,而是给一个回报函数,这个回报函数决定当前状态得到什么样的结果(“好”还是“坏”)。 其数学本质是一个马尔科夫决策过程。最终的目的是决策过程中整体的回报函数期望最优。如下图示:

强化学习设置(reinforcement learning setup) 隐马尔可夫模型—— HMM(hidden Markov model)
上面讲到了马尔科夫决策,马尔科夫决策是啥玩意呢?马尔可夫决策过程(MDPs)以安德烈马尔可夫的名字命名 ,针对一些决策的输出结果部分随机而又部分可控的情况,给决策者提供一个决策制定的数学建模框架。MDPs对通过动态规划和强化学习来求解的广泛的优化问题是非常有用的。下面我们简单说说马尔科夫决策的理论:

下面给个形象的图表示这个过程:

当这一切都确定了,剩下的事情就是寻找一种最优策略(policy)。所谓策略,就是状态到动作的映射。我们的目的是,找到一种最优策略,使得遵循这种策略进行的决策过程,得到的全局回报最大。所以,RL的本质就是在这些信号下找到这个最佳策略。

上面啰嗦了那么多,就是说明了强化学习概念和理论,同时我们应该认识到强化学习跟人类积累经验很类似。下面该说说深度强化学习了。
上面讲到的强化学习比较牛了,为啥还要加个深度学习呢?难道仅仅是为了跟深度学习凑近乎么?(当然这个也是一个原因吧?),当然不仅仅是。在最开始说的那篇牛逼的nature文章中说:
简单点说就是普通的强化学习虽然应用的比较成功,但是特征状态需要人工设定,对于复杂的场景,是个很困难的事情,特别容易造成维数灾难,同时表达的还不好。那解决办法是啥呢?记得昨天介绍深度学习时说到深度学习的本质就是自动学习特征,这不正好解了强化学习的渴么!于是乎谷歌的那帮牛人开始用深度学习提取特征,再应用在强化学习上面,得到了很好的结果。谷歌用的卷积神经网络(Convolutional Neural Network,CNN)进行特征提取,
CNN + RL = Deep Q-network(深度强化学习算法DQN)。
CNN又是啥玩意?本来是要先介绍卷积神经网络,再介绍深度强化的,这里有点插叙了,我还是先简单说下吧,今后会有专门的篇章介绍的。
卷积神经网络是人工神经网络的一种,已成为当前语音分析和图像识别领域的研究热点这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性。一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。如下图所示,展示了一个33的卷积核在55的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。

做完卷积后,接下来还要做池化,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。

下面再看看完整的CNN:
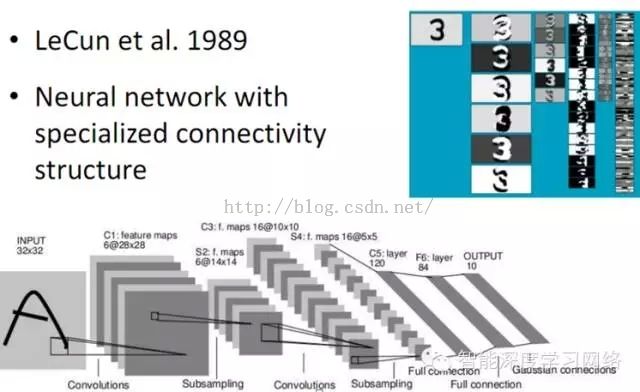
谷歌训练DQN的算法说明如下:

上面啰嗦介绍那么多,也只能说个大概。下面大概总结下:深度强化学习就是用深度学习网络自动学习动态场景的特征,然后通过强化学习学习对应场景特征的决策动作序列。
说明:
本文引用了一些论坛的文章以及论文的图片,不一 一列举了,如有雷同,纯属正常。