Java单例模式和volatile关键字
单例模式是最简单的设计模式,实现也非常“简单”。一直以为我写没有问题,直到被 Coverity 打脸。
1. 暴露问题
前段时间,有段代码被 Coverity 警告了,简化一下代码如下,为了方便后面分析,我在这里标上了一些序号:
private static SettingsDbHelper sInst = null;public static SettingsDbHelper getInstance(Context context) {if (sInst == null) { // 1 synchronized (SettingsDbHelper.class) { // 2 SettingsDbHelper inst = sInst; // 3 if (inst == null) { // 4 inst = new SettingsDbHelper(context); // 5 sInst = inst; // 6 }}}return sInst; // 7 }大家知道,这可是高大上的 Double Checked locking 模式,保证多线程安全,而且高性能的单例实现,比下面的单例实现,“逼格”不知道高到哪里去了:
private static SettingsDbHelper sInst = null;public static synchronized SettingsDbHelper getInstance(Context context) {if (sInst == null) {
sInst = new SettingsDbHelper(context);}return sInst;}你一个机器人竟敢警告我代码写的不对,我一度怀疑它不认识这种写法(后面将证明我是多么幼稚,啪。。。)。然后,它认真的给我分析这段代码为什么有问题,如下图所示:
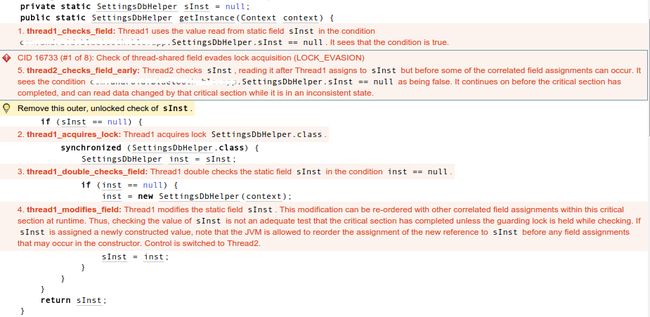
2. 原因分析
Coverity 是静态代码分析工具,它会模拟其实际运行情况。例如这里,假设有两个线程进入到这段代码,其中红色的部分是运行的步骤解析,开头的标号表示其运行顺序。关于 Coverity 的详细文档可以参考这里,这里简单解析一下其运行情况如下:
- 线程 1 运行到 1 处,第一次进入,这里肯定是为
true的; - 线程 1 运行到 2 处,获得锁
SettingsDbHelper.class; - 线程 1 运行到 3 和 4 处,赋值
inst = sInst,这时 sInst 还是 null,所以继续往下运行,创建一个新的实例; - 线程 1 运行到 6 处,修改 sInst 的值。这一步非常关键,这里的解析是,因为这些修改可能因为和其他赋值操作运行被重新排序(Re-order),这就可能导致先修改了 sInst 的值,而
new SettingsDbHelper(context)这个构造函数并没有执行完。而在这个时候,程序切换到线程 2; - 线程 2 运行到 1 处,因为第 4 步的时候,线程 1 已经给 sInst 赋值了,所以
sInst == null的判断为false,线程 2 就直接返回 sInst 了,但是这个时候 sInst 并没有被初始化完成,直接使用它可能会导致程序崩溃。
上面解析得好像很清楚,但是关键在第 4 步,为什么会出现 Re-Order?赋值了,但没有初始化又是怎么回事?这是由于 Java 的内存模型决定的。问题主要出现在这 5 和 6 两行,这里的构造函数可能会被编译成内联的(inline),在 Java 虚拟机中运行的时候编译成执行指令以后,可以用如下的伪代码来表示:
inst = allocat(); // 分配内存
sInst = inst;
constructor(inst); // 真正执行构造函数
说到内存模型,这里就不小心触及了 Java 中比较复杂的内容——多线程编程和 Java 内存模型。在这里,我们可以简单的理解就是,构造函数可能会被分为两块:先分配内存并赋值,再初始化。关于 Java 内存模型(JMM)的详解,可以参考这个系列文章 《深入理解Java内存模型》,一共有 7 篇(一,二,三,四,五,六,七)。
3. 解决方案
上面的问题的解决方法是,在 Java 5 之后,引入扩展关键字 volatile 的功能,它能保证:
对
volatile变量的写操作,不允许和它之前的读写操作打乱顺序;对volatile变量的读操作,不允许和它之后的读写乱序。
关于 volatile 关键字原理详解请参考上面的 深入理解内存模型(四)。
所以,上面的操作,只需要对 sInst 变量添加 volatile 关键字修饰即可。但是,我们知道,对 volatile 变量的读写操作是一个比较重的操作,所以上面的代码还可以优化一下,如下:
private static volatile SettingsDbHelper sInst = null; // <<< 这里添加了 volatile public static SettingsDbHelper getInstance(Context context) {
SettingsDbHelper inst = sInst; // <<< 在这里创建临时变量 if (sInst == null) {synchronized (SettingsDbHelper.class) {
inst = sInst;if (inst == null) {
inst = new SettingsDbHelper(context);
sInst = inst;}}}return inst; // <<< 注意这里返回的是临时变量 }通过这样修改以后,在运行过程中,除了第一次以外,其他的调用只要访问 volatile 变量 sInst 一次,这样能提高 25% 的性能(Wikipedia)。
有读者提到,这里为什么需要再定义一个临时变量 inst?通过前面的对 volatile 关键字作用解释可知,访问 volatile 变量,需要保证一些执行顺序,所以的开销比较大。这里定义一个临时变量,在 sInst 不为空的时候(这是绝大部分的情况),只要在开始访问一次 volatile 变量,返回的是临时变量。如果没有此临时变量,则需要访问两次,而降低了效率。
最后,关于单例模式,还有一个更有趣的实现,它能够延迟初始化(lazy initialization),并且多线程安全,还能保证高性能,如下:
class Foo {private static class HelperHolder {public static final Helper helper = new Helper();}public static Helper getHelper() {return HelperHolder.helper;}}延迟初始化,这里是利用了 Java 的语言特性,内部类只有在使用的时候,才回去加载,从而初始化内部静态变量。关于线程安全,这是 Java 运行环境自动给你保证的,在加载的时候,会自动隐形的同步。在访问对象的时候,不需要同步 Java 虚拟机又会自动给你取消同步,所以效率非常高。
另外,关于 final 关键字的原理,请参考 深入理解Java内存模型(六)。
补充一下,有同学提醒有一种更加 Hack 的实现方式--单个成员的枚举,据称是最佳的单例实现方法,如下:
public enum Foo {
INSTANCE;}详情可以参考 这里。
4. 总结
在 Java 中,涉及到多线程编程,问题就会复杂很多,有些 Bug 甚至会超出你的想象。通过上面的介绍,开始对自己的代码运行情况都不那么自信了。其实大可不必这样担心,这种仅仅发生在多线程编程中,遇到有临界值访问的时候,直接使用 synchronized 关键字能够解决绝大部分的问题。
对于 Coverity,开始抱着敬畏知心,它是由一流的计算机科学家创建的。Coverity 作为一个程序,本身知道的东西比我们多得多,而且还比我认真,它指出的问题必须认真对待和分析。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@NotThreadSafe
public
class
NumberRange{
private
int
lower,upper;
public
int
getLower(){
return
lower;
}
public
int
getUpper(){
return
upper;
}
public
void
setLower(
int
value){
if
(value > upper)
throw
new
IllegalArgumentException(...);
lower = value;
}
public
void
setUpper(
int
value){
if
(value < lower)
throw
new
IllegalArgumentException(...);
upper = value;
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
volatile
boolean shutdownRequested;
...
public
void
shutdown()
{
shutdownRequested=
true
;
}
public
void
doWork()
{
while
(!shutdownRequested)
{
//dostuff
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public
class
BackgroundFloobleLoader{
public
volatile
Flooble theFlooble;
public
void
initInBackground(){
//dolotsofstuff
theFlooble = newFlooble();
//this is the only write to theFlooble
}
}
public
class
SomeOtherClass{
public
void
doWork(){
while
(
true
){
//dosomestuff...
//usetheFlooble,butonlyifitisready
if
(floobleLoader.theFlooble!=
null
)doSomething(floobleLoader.theFlooble);
}
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public
class
UserManager{
public
volatile
String lastUser;
public
boolean
authenticate(String user, String password){
boolean
valid = passwordIsValid(user, password);
if
(valid){
User u =
new
User();
activeUsers.add(u);
lastUser = user;
}
return
valid;
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@ThreadSafe
public
class
Person{
private
volatile
String firstName;
private
volatile
String lastName;
private
volatile
intage;
public
String getFirstName(){
return
firstName;
}
public
String getLastName(){
return
lastName;
}
public
int
getAge(){
return
age;
}
public
void
setFirstName(String firstName){
this
.firstName = firstName;
}
public
void
setLastName(String lastName){
this
.lastName = lastName;
}
public
void
setAge(
int
age){
this
.age = age;
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@ThreadSafe
public
class
CheesyCounter{
//Employs the cheap read-write lock trick
//All mutative operations MUST be done with the 'this' lock held
@GuardedBy
(
"this"
)
private
volatile
int
value;
public
int
getValue(){
return
value;
}
public
synchronized
int
increment(){
return
value++;
}
}
|