Impala 2、Impala Shell 和 Impala SQL
1、Impala 外部 Shell
Impala外部Shell 就是不进入Impala内部,直接执行的ImpalaShell 例如通过外部Shell查看Impala帮助可以使用: $ impala-shell -h 这样就可以查看了;
再例如显示一个SQL语句的执行计划: $ impala-shell -p select count(*) from t_stu
下面是Impala的外部Shell的一些参数:
• -h (--help) 帮助
• -v (--version) 查询版本信息
• -V (--verbose) 启用详细输出
• --quiet 关闭详细输出
• -p 显示执行计划
• -i hostname (--impalad=hostname) 指定连接主机格式hostname:port 默认端口21000
• -r(--refresh_after_connect)刷新所有元数据
• -q query (--query=query) 从命令行执行查询,不进入impala-shell
• -d default_db (--database=default_db) 指定数据库
• -B(--delimited)去格式化输出
• --output_delimiter=character 指定分隔符
• --print_header 打印列名
• -f query_file(--query_file=query_file)执行查询文件,以分号分隔
• -o filename (--output_file filename) 结果输出到指定文件
• -c 查询执行失败时继续执行
• -k (--kerberos) 使用kerberos安全加密方式运行impala-shell
• -l 启用LDAP认证
• -u 启用LDAP时,指定用户名
2、Impala内部Shell
使用命令 $ impala-sehll 可以进入impala,在这里可以像Hive一样正常使用SQL,而且还有一些内部的impala命令:
• help
• connect <hostname:port> 连接主机,默认端口21000
• refresh <tablename> 增量刷新元数据库
• invalidate metadata 全量刷新元数据库
• explain <sql> 显示查询执行计划、步骤信息
• set explain_level 设置显示级别(0,1,2,3)
• shell <shell> 不退出impala-shell执行Linux命令
• profile (查询完成后执行) 查询最近一次查询的底层信息
例:查看帮助可以直接使用: help ,要刷新一个表的增量元数据可以使用 refresh t_stu;
3、Impala 的监护管理
可以通过下面的链接来访问Impala的监护管理页面:
• 查看StateStore
– http://node1:25020/
• 查看Catalog
– http://node1:25010/
4、Impala 存储&&分区
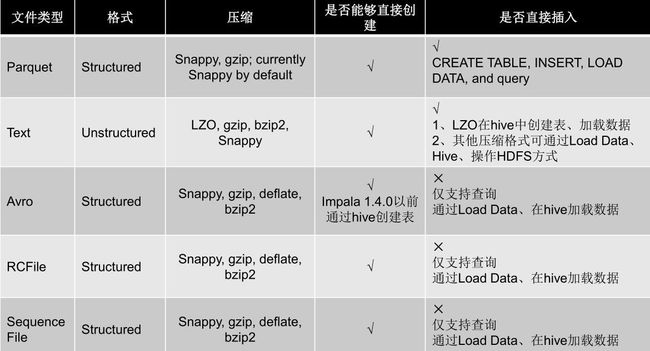
下面是Impala对文件的格式及压缩类型的支持

• 添加分区方式
– 1、partitioned by 创建表时,添加该字段指定分区列表
– 2、使用alter table 进行分区的添加和删除操作
create table t_person(id int, name string, age int) partitioned by (type string); alter table t_person add partition (sex=‘man'); alter table t_person drop partition (sex=‘man'); alter table t_person drop partition (sex=‘man‘,type=‘boss’);
• 分区内添加数据
insert into t_person partition (type='boss') values (1,’zhangsan’,18),(2,’lisi’,23) insert into t_person partition (type='coder') values(3,wangwu’,22),(4,’zhaoliu’,28),(5,’tianqi’,24)
• 查询指定分区数据
select id,name from t_person where type=‘coder
5、Impala SQL VS HiveQL
下面是Impala对基础数据类型和扩展数据类型的支持
• 此外,Impala不支持HiveQL以下特性:
– 可扩展机制,例如:TRANSFORM、自定义文件格式、自定义SerDes
– XML、JSON函数
– 某些聚合函数:
• covar_pop, covar_samp, corr, percentile, percentile_approx,histogram_numeric, collect_set
• Impala仅支持:AVG,COUNT,MAX,MIN,SUM
– 多Distinct查询
– HDF、UDAF
– 以下语句:
ANALYZE TABLE (Impala:COMPUTE STATS)、DESCRIBE COLUMN、
DESCRIBE DATABASE、EXPORT TABLE、IMPORT TABLE、SHOW
TABLE EXTENDED、SHOW INDEXES、SHOW COLUMNS
6、Impala SQL
--创建数据库 create database db1; use db1; -- 删除数据库 use default; drop database db1; --创建表(内部表) -- 默认方式创建表: create table t_person1( id int, name string) --指定存储方式: create table t_person2( id int, name string ) row format delimited fields terminated by ‘\0’ (impala1.3.1版本以上支持‘\0’ ) stored as textfile; --其他方式创建内部表 --使用现有表结构: create table tab_3 like tab_1; --指定文本表字段分隔符: alter table tab_3 set serdeproperties(‘serialization.format’=‘,’,’field.delim’=‘,’); --插入数据 -- 直接插入值方式: insert into t_person values (1,hex(‘hello world’)); --从其他表插入数据: insert (overwrite) into tab_3 select * form tab_2 ; --批量导入文件方式方式: load data local inpath ‘/xxx/xxx’ into table tab_1; --创建表(外部表) --默认方式创建表: create external table tab_p1( id int, name string ) location ‘/user/xxx.txt’ --指定存储方式: create external table tab_p2 like parquet_tab ‘/user/xxx/xxx/1.dat’ partition (year int , month tinyint, day tinyint) location ‘/user/xxx/xxx’ stored as parquet; --视图 --创建视图: create view v1 as select count(id) as total from tab_3 ; --查询视图: select * from v1; --查看视图定义: describe formatted v1
• 注意:
– 1)不能向impala的视图进行插入操作
– 2)insert 表可以来自视图
• 数据文件处理
– 加载数据:
• 1、insert语句:插入数据时每条数据产生一个数据文件,不建议用此方式加载批量数据
• 2、load data方式:再进行批量插入时使用这种方式比较合适
• 3、来自中间表:此种方式使用于从一个小文件较多的大表中读取文件并写入新的表生产少量的数据文件。也可以通过此种方式进行格式转换。
– 空值处理:
• impala将“\n”表示为NULL,在结合sqoop使用是注意做相应的空字段过滤,
• 也可以使用以下方式进行处理:
alter table name set tblproperties(“serialization.null.format”=“null”)