简单的爬行--静态网页爬虫+下一篇实例
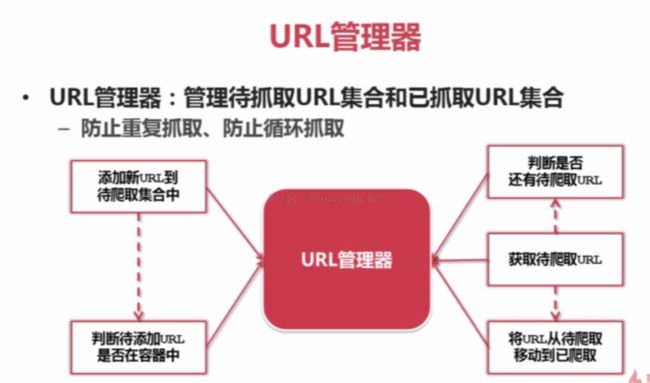
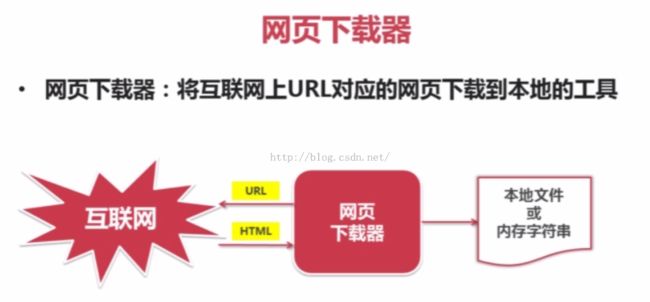


1、有些网页需要用户登录才能访问,需要添加cookie的处理
2、有些网页需要代理才能访问
3、有些网页是使用HTTPS加密访问的
4、有些网页的URL存在相互自动的跳转关系


<span style="font-size:18px;">#coding=utf-8
import urllib2
url='https://www.baidu.com/'
print '第一种方法'
response1=urllib2.urlopen(url)
print response1.getcode()#打印code看是否读取成功
print len(response1.read())#打印下载网页的长度
print '第二种方法'
request=urllib2.Request(url)
request.add_header("user-agent","Mozilla/5.0")#把URL伪装成了一个浏览器
response2=urllib2.urlopen(request)
print response2.getcode()#打印code看是否读取成功
print len(response2.read())#打印下载网页的长度
print '第三种方法'
cj=cookielib.CookieJar()#创建一个cookie的容器
opener=urllib2.build_opener(urllib2.HTTPCookiePrecessor(cj))
urllib2.install_opener(opener)#给urllib2增加opener功能
response3=urllib2.urlopen(url)
print response3.getcode()#打印code看是否读取成功
print cj
print response3.read()#打印下载网页</span>
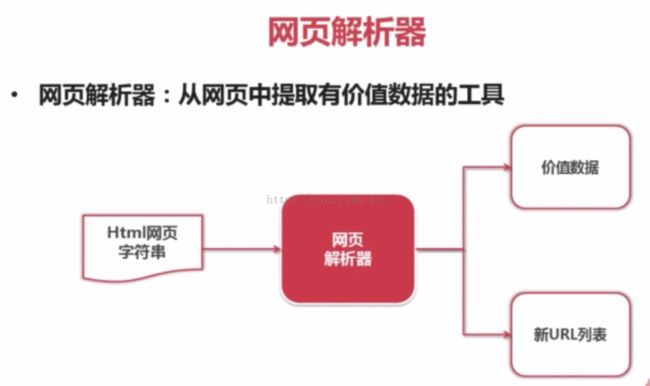




<span style="font-size:18px;">#coding=utf-8
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from BeautifulSoup import BeautifulSoup
soup=BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8')
print '获取所有的链接'
links =soup.find_all('a')
for link in links:
print link.name,link['href'],link.get_text()
print '获取lacie的链接'
link_node=soup.find('a',href='http://example.com/lacie')
print link_node.name,link_node['href'],link_node.get_text()
print '正则匹配'
link_node=soup.find('a',href=re.compile (r'ill'))
print link_node.name,link_node['href'],link_node.get_text()
print '获取P段落文字'
p_node=soup.find('p',class_="title")
print p_node.name,link_node.get_text()</span>
【没运行出来,不知道问题在哪】