如何使用Hadoop的ChainMapper和ChainReducer
Hadoop的MR作业支持链式处理,类似在一个生产牛奶的流水线上,每一个阶段都有特定的任务要处理,比如提供牛奶盒,装入牛奶,封盒,打印出厂日期,等等,通过这样进一步的分工,从而提高了生产效率,那么在我们的Hadoop的MapReduce中也是如此,支持链式的处理方式,这些Mapper像Linux管道一样,前一个Mapper的输出结果直接重定向到下一个Mapper的输入,形成一个流水线,而这一点与Lucene和Solr中的Filter机制是非常类似的,Hadoop项目源自Lucene,自然也借鉴了一些Lucene中的处理方式。
举个例子,比如处理文本中的一些禁用词,或者敏感词,等等,Hadoop里的链式操作,支持的形式类似正则Map+ Rrduce Map*,代表的意思是全局只能有一个唯一的Reduce,但是在Reduce的前后是可以存在无限多个Mapper来进行一些预处理或者善后工作的。
下面来看下的散仙今天的测试例子,先看下我们的数据,以及需求。
数据如下:
<pre name="code" class="java">手机 5000
电脑 2000
衣服 300
鞋子 1200
裙子 434
手套 12
图书 12510
小商品 5
小商品 3
订餐 2</pre>
需求是:
<pre name="code" class="java">/**
* 需求:
* 在第一个Mapper里面过滤大于10000万的数据
* 第二个Mapper里面过滤掉大于100-10000的数据
* Reduce里面进行分类汇总并输出
* Reduce后的Mapper里过滤掉商品名长度大于3的数据
*/</pre>
<pre name="code" class="java">
预计处理完的结果是:
手套 12
订餐 2
</pre>
散仙的hadoop版本是1.2的,在1.2的版本里,hadoop支持新的API,但是链式的ChainMapper类和ChainReduce类却不支持新 的,新的在hadoop2.x里面可以使用,差别不大,散仙今天给出的是旧的API的,需要注意一下。
代码如下:
<pre name="code" class="java">
package com.qin.test.hadoop.chain;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.lib.ChainMapper;
import org.apache.hadoop.mapred.lib.ChainReducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import com.qin.reducejoin.NewReduceJoin2;
/**
*
* 测试Hadoop里面的
* ChainMapper和ReduceMapper的使用
*
* @author qindongliang
* @date 2014年5月7日
*
* 大数据交流群: 376932160
*
*
*
*
* ***/
public class HaoopChain {
/**
* 需求:
* 在第一个Mapper里面过滤大于10000万的数据
* 第二个Mapper里面过滤掉大于100-10000的数据
* Reduce里面进行分类汇总并输出
* Reduce后的Mapper里过滤掉商品名长度大于3的数据
*/
/**
*
* 过滤掉大于10000万的数据
*
* */
private static class AMapper01 extends MapReduceBase implements Mapper&lt;LongWritable, Text, Text, Text&gt;{
@Override
public void map(LongWritable key, Text value, OutputCollector&lt;Text, Text&gt; output, Reporter reporter)
throws IOException {
String text=value.toString();
String texts[]=text.split(" ");
System.out.println("AMapper01里面的数据: "+text);
if(texts[1]!=null&amp;&amp;texts[1].length()&gt;0){
int count=Integer.parseInt(texts[1]);
if(count&gt;10000){
System.out.println("AMapper01过滤掉大于10000数据: "+value.toString());
return;
}else{
output.collect(new Text(texts[0]), new Text(texts[1]));
}
}
}
}
/**
*
* 过滤掉大于100-10000的数据
*
* */
private static class AMapper02 extends MapReduceBase implements Mapper&lt;Text, Text, Text, Text&gt;{
@Override
public void map(Text key, Text value,
OutputCollector&lt;Text, Text&gt; output, Reporter reporter)
throws IOException {
int count=Integer.parseInt(value.toString());
if(count&gt;=100&amp;&amp;count&lt;=10000){
System.out.println("AMapper02过滤掉的小于10000大于100的数据: "+key+" "+value);
return;
} else{
output.collect(key, value);
}
}
}
/**
* Reuduce里面对同种商品的
* 数量相加数据即可
*
* **/
private static class AReducer03 extends MapReduceBase implements Reducer&lt;Text, Text, Text, Text&gt;{
@Override
public void reduce(Text key, Iterator&lt;Text&gt; values,
OutputCollector&lt;Text, Text&gt; output, Reporter reporter)
throws IOException {
int sum=0;
System.out.println("进到Reduce里了");
while(values.hasNext()){
Text t=values.next();
sum+=Integer.parseInt(t.toString());
}
//旧API的集合,不支持foreach迭代
// for(Text t:values){
// sum+=Integer.parseInt(t.toString());
// }
output.collect(key, new Text(sum+""));
}
}
/***
*
* Reduce之后的Mapper过滤
* 过滤掉长度大于3的商品名
*
* **/
private static class AMapper04 extends MapReduceBase implements Mapper&lt;Text, Text, Text, Text&gt;{
@Override
public void map(Text key, Text value,
OutputCollector&lt;Text, Text&gt; output, Reporter reporter)
throws IOException {
int len=key.toString().trim().length();
if(len&gt;=3){
System.out.println("Reduce后的Mapper过滤掉长度大于3的商品名: "+ key.toString()+" "+value.toString());
return ;
}else{
output.collect(key, value);
}
}
}
/***
* 驱动主类
* **/
public static void main(String[] args) throws Exception{
//Job job=new Job(conf,"myjoin");
JobConf conf=new JobConf(HaoopChain.class);
conf.set("mapred.job.tracker","192.168.75.130:9001");
conf.setJobName("t7");
conf.setJar("tt.jar");
conf.setJarByClass(HaoopChain.class);
// Job job=new Job(conf, "2222222");
// job.setJarByClass(HaoopChain.class);
System.out.println("模式: "+conf.get("mapred.job.tracker"));;
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(Text.class);
//Map1的过滤
JobConf mapA01=new JobConf(false);
ChainMapper.addMapper(conf, AMapper01.class, LongWritable.class, Text.class, Text.class, Text.class, false, mapA01);
//Map2的过滤
JobConf mapA02=new JobConf(false);
ChainMapper.addMapper(conf, AMapper02.class, Text.class, Text.class, Text.class, Text.class, false, mapA02);
//设置Reduce
JobConf recduceFinallyConf=new JobConf(false);
ChainReducer.setReducer(conf, AReducer03.class, Text.class, Text.class, Text.class, Text.class, false, recduceFinallyConf);
//Reduce过后的Mapper过滤
JobConf reduceA01=new JobConf(false);
ChainReducer.addMapper(conf, AMapper04.class, Text.class, Text.class, Text.class, Text.class, true, reduceA01);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
conf.setInputFormat(org.apache.hadoop.mapred.TextInputFormat.class);
conf.setOutputFormat(org.apache.hadoop.mapred.TextOutputFormat.class);
FileSystem fs=FileSystem.get(conf);
//
Path op=new Path("hdfs://192.168.75.130:9000/root/outputchain");
if(fs.exists(op)){
fs.delete(op, true);
System.out.println("存在此输出路径,已删除!!!");
}
//
//
org.apache.hadoop.mapred.FileInputFormat.setInputPaths(conf, new Path("hdfs://192.168.75.130:9000/root/inputchain"));
org.apache.hadoop.mapred.FileOutputFormat.setOutputPath(conf, op);
//
//System.exit(conf.waitForCompletion(true)?0:1);
JobClient.runJob(conf);
}
}
</pre>
运行日志如下:
<pre name="code" class="java">
模式: 192.168.75.130:9001
存在此输出路径,已删除!!!
WARN - JobClient.copyAndConfigureFiles(746) | Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
WARN - NativeCodeLoader.&lt;clinit&gt;(52) | Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
WARN - LoadSnappy.&lt;clinit&gt;(46) | Snappy native library not loaded
INFO - FileInputFormat.listStatus(199) | Total input paths to process : 1
INFO - JobClient.monitorAndPrintJob(1380) | Running job: job_201405072054_0009
INFO - JobClient.monitorAndPrintJob(1393) | map 0% reduce 0%
INFO - JobClient.monitorAndPrintJob(1393) | map 50% reduce 0%
INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 0%
INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 33%
INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 100%
INFO - JobClient.monitorAndPrintJob(1448) | Job complete: job_201405072054_0009
INFO - Counters.log(585) | Counters: 30
INFO - Counters.log(587) | Job Counters
INFO - Counters.log(589) | Launched reduce tasks=1
INFO - Counters.log(589) | SLOTS_MILLIS_MAPS=11357
INFO - Counters.log(589) | Total time spent by all reduces waiting after reserving slots (ms)=0
INFO - Counters.log(589) | Total time spent by all maps waiting after reserving slots (ms)=0
INFO - Counters.log(589) | Launched map tasks=2
INFO - Counters.log(589) | Data-local map tasks=2
INFO - Counters.log(589) | SLOTS_MILLIS_REDUCES=9972
INFO - Counters.log(587) | File Input Format Counters
INFO - Counters.log(589) | Bytes Read=183
INFO - Counters.log(587) | File Output Format Counters
INFO - Counters.log(589) | Bytes Written=19
INFO - Counters.log(587) | FileSystemCounters
INFO - Counters.log(589) | FILE_BYTES_READ=57
INFO - Counters.log(589) | HDFS_BYTES_READ=391
INFO - Counters.log(589) | FILE_BYTES_WRITTEN=174859
INFO - Counters.log(589) | HDFS_BYTES_WRITTEN=19
INFO - Counters.log(587) | Map-Reduce Framework
INFO - Counters.log(589) | Map output materialized bytes=63
INFO - Counters.log(589) | Map input records=10
INFO - Counters.log(589) | Reduce shuffle bytes=63
INFO - Counters.log(589) | Spilled Records=8
INFO - Counters.log(589) | Map output bytes=43
INFO - Counters.log(589) | Total committed heap usage (bytes)=336338944
INFO - Counters.log(589) | CPU time spent (ms)=1940
INFO - Counters.log(589) | Map input bytes=122
INFO - Counters.log(589) | SPLIT_RAW_BYTES=208
INFO - Counters.log(589) | Combine input records=0
INFO - Counters.log(589) | Reduce input records=4
INFO - Counters.log(589) | Reduce input groups=3
INFO - Counters.log(589) | Combine output records=0
INFO - Counters.log(589) | Physical memory (bytes) snapshot=460980224
INFO - Counters.log(589) | Reduce output records=2
INFO - Counters.log(589) | Virtual memory (bytes) snapshot=2184105984
INFO - Counters.log(589) | Map output records=4
</pre>
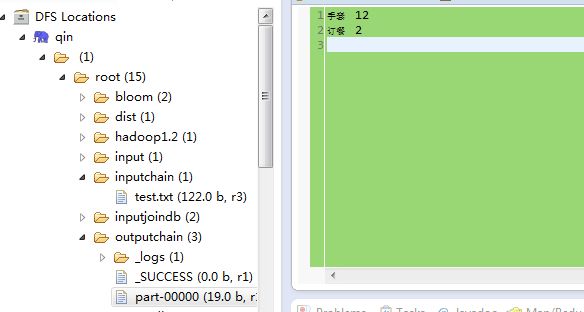
产生的数据如下:
举个例子,比如处理文本中的一些禁用词,或者敏感词,等等,Hadoop里的链式操作,支持的形式类似正则Map+ Rrduce Map*,代表的意思是全局只能有一个唯一的Reduce,但是在Reduce的前后是可以存在无限多个Mapper来进行一些预处理或者善后工作的。
下面来看下的散仙今天的测试例子,先看下我们的数据,以及需求。
数据如下:
<pre name="code" class="java">手机 5000
电脑 2000
衣服 300
鞋子 1200
裙子 434
手套 12
图书 12510
小商品 5
小商品 3
订餐 2</pre>
需求是:
<pre name="code" class="java">/**
* 需求:
* 在第一个Mapper里面过滤大于10000万的数据
* 第二个Mapper里面过滤掉大于100-10000的数据
* Reduce里面进行分类汇总并输出
* Reduce后的Mapper里过滤掉商品名长度大于3的数据
*/</pre>
<pre name="code" class="java">
预计处理完的结果是:
手套 12
订餐 2
</pre>
散仙的hadoop版本是1.2的,在1.2的版本里,hadoop支持新的API,但是链式的ChainMapper类和ChainReduce类却不支持新 的,新的在hadoop2.x里面可以使用,差别不大,散仙今天给出的是旧的API的,需要注意一下。
代码如下:
<pre name="code" class="java">
package com.qin.test.hadoop.chain;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.lib.ChainMapper;
import org.apache.hadoop.mapred.lib.ChainReducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import com.qin.reducejoin.NewReduceJoin2;
/**
*
* 测试Hadoop里面的
* ChainMapper和ReduceMapper的使用
*
* @author qindongliang
* @date 2014年5月7日
*
* 大数据交流群: 376932160
*
*
*
*
* ***/
public class HaoopChain {
/**
* 需求:
* 在第一个Mapper里面过滤大于10000万的数据
* 第二个Mapper里面过滤掉大于100-10000的数据
* Reduce里面进行分类汇总并输出
* Reduce后的Mapper里过滤掉商品名长度大于3的数据
*/
/**
*
* 过滤掉大于10000万的数据
*
* */
private static class AMapper01 extends MapReduceBase implements Mapper&lt;LongWritable, Text, Text, Text&gt;{
@Override
public void map(LongWritable key, Text value, OutputCollector&lt;Text, Text&gt; output, Reporter reporter)
throws IOException {
String text=value.toString();
String texts[]=text.split(" ");
System.out.println("AMapper01里面的数据: "+text);
if(texts[1]!=null&amp;&amp;texts[1].length()&gt;0){
int count=Integer.parseInt(texts[1]);
if(count&gt;10000){
System.out.println("AMapper01过滤掉大于10000数据: "+value.toString());
return;
}else{
output.collect(new Text(texts[0]), new Text(texts[1]));
}
}
}
}
/**
*
* 过滤掉大于100-10000的数据
*
* */
private static class AMapper02 extends MapReduceBase implements Mapper&lt;Text, Text, Text, Text&gt;{
@Override
public void map(Text key, Text value,
OutputCollector&lt;Text, Text&gt; output, Reporter reporter)
throws IOException {
int count=Integer.parseInt(value.toString());
if(count&gt;=100&amp;&amp;count&lt;=10000){
System.out.println("AMapper02过滤掉的小于10000大于100的数据: "+key+" "+value);
return;
} else{
output.collect(key, value);
}
}
}
/**
* Reuduce里面对同种商品的
* 数量相加数据即可
*
* **/
private static class AReducer03 extends MapReduceBase implements Reducer&lt;Text, Text, Text, Text&gt;{
@Override
public void reduce(Text key, Iterator&lt;Text&gt; values,
OutputCollector&lt;Text, Text&gt; output, Reporter reporter)
throws IOException {
int sum=0;
System.out.println("进到Reduce里了");
while(values.hasNext()){
Text t=values.next();
sum+=Integer.parseInt(t.toString());
}
//旧API的集合,不支持foreach迭代
// for(Text t:values){
// sum+=Integer.parseInt(t.toString());
// }
output.collect(key, new Text(sum+""));
}
}
/***
*
* Reduce之后的Mapper过滤
* 过滤掉长度大于3的商品名
*
* **/
private static class AMapper04 extends MapReduceBase implements Mapper&lt;Text, Text, Text, Text&gt;{
@Override
public void map(Text key, Text value,
OutputCollector&lt;Text, Text&gt; output, Reporter reporter)
throws IOException {
int len=key.toString().trim().length();
if(len&gt;=3){
System.out.println("Reduce后的Mapper过滤掉长度大于3的商品名: "+ key.toString()+" "+value.toString());
return ;
}else{
output.collect(key, value);
}
}
}
/***
* 驱动主类
* **/
public static void main(String[] args) throws Exception{
//Job job=new Job(conf,"myjoin");
JobConf conf=new JobConf(HaoopChain.class);
conf.set("mapred.job.tracker","192.168.75.130:9001");
conf.setJobName("t7");
conf.setJar("tt.jar");
conf.setJarByClass(HaoopChain.class);
// Job job=new Job(conf, "2222222");
// job.setJarByClass(HaoopChain.class);
System.out.println("模式: "+conf.get("mapred.job.tracker"));;
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(Text.class);
//Map1的过滤
JobConf mapA01=new JobConf(false);
ChainMapper.addMapper(conf, AMapper01.class, LongWritable.class, Text.class, Text.class, Text.class, false, mapA01);
//Map2的过滤
JobConf mapA02=new JobConf(false);
ChainMapper.addMapper(conf, AMapper02.class, Text.class, Text.class, Text.class, Text.class, false, mapA02);
//设置Reduce
JobConf recduceFinallyConf=new JobConf(false);
ChainReducer.setReducer(conf, AReducer03.class, Text.class, Text.class, Text.class, Text.class, false, recduceFinallyConf);
//Reduce过后的Mapper过滤
JobConf reduceA01=new JobConf(false);
ChainReducer.addMapper(conf, AMapper04.class, Text.class, Text.class, Text.class, Text.class, true, reduceA01);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
conf.setInputFormat(org.apache.hadoop.mapred.TextInputFormat.class);
conf.setOutputFormat(org.apache.hadoop.mapred.TextOutputFormat.class);
FileSystem fs=FileSystem.get(conf);
//
Path op=new Path("hdfs://192.168.75.130:9000/root/outputchain");
if(fs.exists(op)){
fs.delete(op, true);
System.out.println("存在此输出路径,已删除!!!");
}
//
//
org.apache.hadoop.mapred.FileInputFormat.setInputPaths(conf, new Path("hdfs://192.168.75.130:9000/root/inputchain"));
org.apache.hadoop.mapred.FileOutputFormat.setOutputPath(conf, op);
//
//System.exit(conf.waitForCompletion(true)?0:1);
JobClient.runJob(conf);
}
}
</pre>
运行日志如下:
<pre name="code" class="java">
模式: 192.168.75.130:9001
存在此输出路径,已删除!!!
WARN - JobClient.copyAndConfigureFiles(746) | Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
WARN - NativeCodeLoader.&lt;clinit&gt;(52) | Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
WARN - LoadSnappy.&lt;clinit&gt;(46) | Snappy native library not loaded
INFO - FileInputFormat.listStatus(199) | Total input paths to process : 1
INFO - JobClient.monitorAndPrintJob(1380) | Running job: job_201405072054_0009
INFO - JobClient.monitorAndPrintJob(1393) | map 0% reduce 0%
INFO - JobClient.monitorAndPrintJob(1393) | map 50% reduce 0%
INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 0%
INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 33%
INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 100%
INFO - JobClient.monitorAndPrintJob(1448) | Job complete: job_201405072054_0009
INFO - Counters.log(585) | Counters: 30
INFO - Counters.log(587) | Job Counters
INFO - Counters.log(589) | Launched reduce tasks=1
INFO - Counters.log(589) | SLOTS_MILLIS_MAPS=11357
INFO - Counters.log(589) | Total time spent by all reduces waiting after reserving slots (ms)=0
INFO - Counters.log(589) | Total time spent by all maps waiting after reserving slots (ms)=0
INFO - Counters.log(589) | Launched map tasks=2
INFO - Counters.log(589) | Data-local map tasks=2
INFO - Counters.log(589) | SLOTS_MILLIS_REDUCES=9972
INFO - Counters.log(587) | File Input Format Counters
INFO - Counters.log(589) | Bytes Read=183
INFO - Counters.log(587) | File Output Format Counters
INFO - Counters.log(589) | Bytes Written=19
INFO - Counters.log(587) | FileSystemCounters
INFO - Counters.log(589) | FILE_BYTES_READ=57
INFO - Counters.log(589) | HDFS_BYTES_READ=391
INFO - Counters.log(589) | FILE_BYTES_WRITTEN=174859
INFO - Counters.log(589) | HDFS_BYTES_WRITTEN=19
INFO - Counters.log(587) | Map-Reduce Framework
INFO - Counters.log(589) | Map output materialized bytes=63
INFO - Counters.log(589) | Map input records=10
INFO - Counters.log(589) | Reduce shuffle bytes=63
INFO - Counters.log(589) | Spilled Records=8
INFO - Counters.log(589) | Map output bytes=43
INFO - Counters.log(589) | Total committed heap usage (bytes)=336338944
INFO - Counters.log(589) | CPU time spent (ms)=1940
INFO - Counters.log(589) | Map input bytes=122
INFO - Counters.log(589) | SPLIT_RAW_BYTES=208
INFO - Counters.log(589) | Combine input records=0
INFO - Counters.log(589) | Reduce input records=4
INFO - Counters.log(589) | Reduce input groups=3
INFO - Counters.log(589) | Combine output records=0
INFO - Counters.log(589) | Physical memory (bytes) snapshot=460980224
INFO - Counters.log(589) | Reduce output records=2
INFO - Counters.log(589) | Virtual memory (bytes) snapshot=2184105984
INFO - Counters.log(589) | Map output records=4
</pre>
产生的数据如下:
总结,测试过程中,发现如果Reduce后面,还有Mapper执行,那么注意一定要,在ChainReducer里面先set一个全局唯一的Reducer,然后再add一个Mapper,否则,在运行的时候,会报空指针异常,这一点需要特别注意!
来源: http://www.iteye.com/topic/1134144