《python自然语言处理》笔记---chap2 获得文本语料和词汇资源(续)
---------我可以投诉吗?不知道为什么上午接着写了好多,明明发表了,可是还是没了,是不是不能写那么多?-----
载入你自己的语料库
待续。。。
2.3 更多关于python:代码重用
使用文本编辑器创建程序
函数
局部变量,不能在函数体外访问。函数在被“调用”之前不会做任何事情。
一个Python 函数:这个函数试图生成任何英语名词的复数形式。
#coding:utf-8
def plural(word):
if word.endswith('y'):
#以y结尾,把y该i,再加es
return word[:-1]+'ies'
elif word[-1] in 'sx' or word[:-2] in ['sh','ch']:
#以s,x,sh,ch,等结尾的单词,加es
return word+'es'
elif word.endswith('an'):
#以an结尾的,变为en
return word[:-2]+'en'
else:
#普通的,直接加s
return word+'s'
print plural('fairy')
print plural('woman')
模块
在一个文件中的变量和函数定义的集合被称为一个python模块。相关模块的集合称为一个包。NLTK的本身是包的集合,有时被称为一个库。
2.4 词典资源
如果我们定义了一个文本my_text,然后vocab = sorted(set(my_text))建立my_text 的词汇表,同时word_freq = FreqDist(my_text)计数文本中每个词的频率。
一个词项包括词目(也叫词条)以及其他附加信息,例如:词性和词意定义。两个不同的词拼写相同被称为同音异义词。

词汇列表语料库
过滤文本:此程序计算文本的词汇表,然后删除所有在现有的词汇列表中出现的元素,只留下罕见或拼写错误的词。
#coding:utf-8
import nltk
def unusual_words(text):
text_vocab=set(w.lower() for w in text if w.isalpha())
english_vocab=set(w.lower() for w in nltk.corpus.words.words())
unusual=text_vocab.difference(english_vocab) #求差集
return sorted(unusual)
print unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt'))
print unusual_words(nltk.corpus.nps_chat.words())
停用词语料库,即高频词汇,如:the、to
from nltk.corpus import stopwords
print stopwords.words('english')
结合两种不同类型的语料库(停用词语料库和路透社语料库),定义一个函数来计算文本中没有在停用词列表中的词的比例:
import nltk
def content_fraction(text):
stopwords=nltk.corpus.stopwords.words('english')
content=[w for w in text if w.lower() not in stopwords]
return len(content)*1.0/len(text) #注意整数除法和浮点数除法,
print content_fraction(nltk.corpus.reuters.words())
一个字母拼词谜题:在由随机选择的字母组成的网格中,选择里面的字母组成词。这个谜题叫做“目标”。图中文字的意思是:用这里显示的字母你能组成多少个4 字母或者更多字母的词?每个字母在每个词中只能被用一次。每个词必须包括中间的字母并且必须至少有一个9 字母的词。没有复数以“s”结尾;没有外来词;没有姓名。能组出21 个词就是“好”;32 个词,“很好”;42 个词,“非常好”。
puzzle_letters=nltk.FreqDist('egivrvonl')
obligatory='r'
wordlist=nltk.corpus.words.words()
print [w for w in wordlist if len(w)>=6 and obligatory in w and nltk.FreqDist(w)<=puzzle_letters]
名字语料库。,包括8000 个按性别分类的名字。男性和女性的名字存储在单独的文件中。让我们找出同时出现在两个文件中的名字即性别暧昧的名字:
#coding:utf-8
import nltk
names=nltk.corpus.names
male_names=names.words('male.txt')
female_names=names.words('female.txt')
print [w for w in male_names if w in female_names]#既在男性文件中也在女性文件中
cfd=nltk.ConditionalFreqDist((fileid,name[-1])
for fileid in names.fileids()
for name in names.words(fileid))
#第一维fileids()函数说明待续,
cfd.plot()
发音的词典
NLTK中包括美国英语的CMU 发音词典,它是为语音合成器使用而设计的。
entries = nltk.corpus.cmudict.entries()
print len(entries)
for entry in entries[39943:39951]:
print entry
对每一个词,这个词典资源提供语音的代码——不同的声音不同的标签——叫做音素
对发音的文本不熟,pass
比较词表
pass
词汇工具:Toolbox和Shoebox
2.5 WordNet
WordNet是面向语义的英语词典,类似与传统辞典,但具有更丰富的结构。NLTK 中包括英语WordNet,共有155,287 个词和117,659 个同义词集合
意义与同义词
(1).同义词。换掉一个词,句子中所有其他成分都保持不变,句子的意思几乎保持不变,则我们可以把它们看做同义词
#coding:utf-8
import nltk
from nltk.corpus import wordnet as wn
print wn.synsets('motorcar')
#[Synset('car.n.01')]
#motorcar被定义为car.n.01,car的第一个名词意义
#car.n.01被称为synset或“同义词集”,意义相同的词的集合
print wn.synsets('car')
print wn.synset('car.n.01').lemma_names
print wn.synset('car.n.01').definition
print wn.synset('car.n.01').examples
#[Synset('car.n.01'), Synset('car.n.02'), Synset('car.n.03'), Synset('car.n.04'), Synset('cable_car.n.01')]
#<bound method Synset.lemma_names of Synset('car.n.01')>
#<bound method Synset.definition of Synset('car.n.01')>
#<bound method Synset.examples of Synset('car.n.01')>
print wn.synset('car.n.01').lemmas
print wn.lemma('car.n.01.automobile')
print wn.lemma('car.n.01.automobile').synset
print wn.lemma('car.n.01.automobile').name
#Lemma('car.n.01.automobile')
#<bound method Lemma.synset of Lemma('car.n.01.automobile')>
#<bound method Lemma.name of Lemma('car.n.01.automobile')>
for synset in wn.synsets('car'):
print synset.lemma_names
'''
运行结果:不知道哪里调用是否有误
<bound method Synset.lemma_names of Synset('car.n.01')>
<bound method Synset.lemma_names of Synset('car.n.02')>
<bound method Synset.lemma_names of Synset('car.n.03')>
<bound method Synset.lemma_names of Synset('car.n.04')>
<bound method Synset.lemma_names of Synset('cable_car.n.01')>
'''
WordNet的层次结构
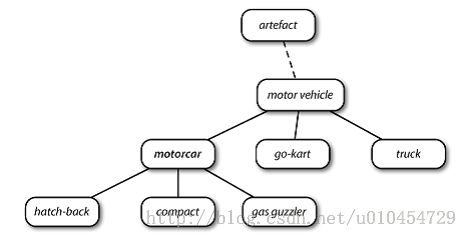
WordNet 概念层次片段:每个节点对应一个同义词集;边表示上位词/下位词关系,即
上级概念与从属概念的关系。
#coding:utf-8
import nltk
from nltk.corpus import wordnet as wn
motorcar=wn.synset('car.n.01')
#WordNet使在概念之间漫游变的容易,注意调用方法时,括号问题,lemma.name()和synset.lemmas(),原书上没加
types_of_motorcar = motorcar.hyponyms()
print types_of_motorcar
print sorted([lemma.name() for synset in types_of_motorcar for lemma in synset.lemmas()])
#coding:utf-8
import nltk
from nltk.corpus import wordnet as wn
motorcar=wn.synset('car.n.01')
#最一般的上位同义词集:
print motorcar.root_hypernyms()
#从car.n.01与entity.n.01之间的两条路径
paths= motorcar.hypernym_paths()
print len(paths)
print [synset.name() for synset in paths[0]]
print [synset.name() for synset in paths[1]]
更多的词汇关系
上位词和下位词被称为词汇关系,WorNet网络的漫游方式是从物品到它们的部分或到它们被包含其中的东西
#coding:utf-8
import nltk
from nltk.corpus import wordnet as wn
#一棵树的部分,是它的树干,树冠,即part_meronyms(),a part of
#树的实质,包括心材和边材组成,即substance_meronyms()
#树木的集合,形成一个森林,即member_holonyms()
print wn.synset('tree.n.01').part_meronyms()
print wn.synset('tree.n.01').substance_meronyms()
print wn.synset('tree.n.01').member_holonyms()
相互之间的关系
#coding:utf-8
import nltk
from nltk.corpus import wordnet as wn
for synset in wn.synsets('mint',wn.NOUN):
print synset.name()+":",synset.definition()
print wn.synset('mint.n.04').part_holonyms() #对比part_meronyms()
print wn.synset('mint.n.04').substance_holonyms()
#mint.n.04 是mint.n.02 的一部分,是组成mint.n.05 的材质。
print wn.synset('mint.n.02').part_meronyms()
print wn.synset('mint.n.05').substance_meronyms()
蕴含关系:entailments();走路的动作包括抬脚的动作,吃的动作包括吞咽
反义词:antonyms()
使用dir()查看词汇关系和同义词集上定义的其他方法。如:dir(wn.synset('harmony.n.02'))
print wn.synset('eat.v.01').entailments()
print wn.lemma('supply.n.02.supply').antonyms()
print wn.lemma('horizontal.a.01.horizontal').antonyms()
print dir(wn.synset('harmony.n.02'))
语义相似度
每个同义词集都有一个或多个上位词路径连接到一个根上位词(如entity.n.01)。连接到同一个根的两个同义词集可能有一些共同的上位词如果两个同义词集共用一个非常具体的上位词——在上位词层次结构中处于较低层的上位词——它们一定有密切的联系。
#coding:utf-8
import nltk
from nltk.corpus import wordnet as wn
right = wn.synset('right_whale.n.01')#[脊椎] 露脊鲸
orca = wn.synset('orca.n.01') # 逆戟鲸
minke = wn.synset('minke_whale.n.01')# 小须鲸
tortoise = wn.synset('tortoise.n.01')#[脊椎] 乌龟
novel = wn.synset('novel.n.01')
right.lowest_common_hypernyms(minke) #露脊鲸最小普通上位词,
[Synset('baleen_whale.n.01')] #须鲸
right.lowest_common_hypernyms(orca)
[Synset('whale.n.02')]
right.lowest_common_hypernyms(tortoise)
[Synset('vertebrate.n.01')] #脊椎动物
right.lowest_common_hypernyms(novel)
[Synset('entity.n.01')]
查找每个同义词集深度:min_depth()
wn.synset('baleen_whale.n.01').min_depth()
14
wn.synset('whale.n.02').min_depth()
13
wn.synset('vertebrate.n.01').min_depth()
8
wn.synset('entity.n.01').min_depth()
0
路径相似度:path_similarityassigns(),基于上位词层次结构中相互连接的概念之间的最短路径在0-1 范围的打分(两者之间没有路径就返回-1)
right.path_similarity(minke)#露脊鲸与小须鲸相似度较高 0.25 right.path_similarity(orca) 0.16666666666666666 right.path_similarity(tortoise) 0.076923076923076927 right.path_similarity(novel) #露脊鲸与小说相似度很低,当然,海洋生物到非生物,跨度大! 0.043478260869565216
2.8 练习
待续。。。