回顾四叉树LOD地形(上)
唉!~其实这是在差不多一年前实现的东西,但当时没作好记录。放了那么久了,如果不做点总结的话,好像有点对不起自己,于是·········还是做点什么吧。
我脑洞比较小,只能大量参考“
潘李亮
”大神的四叉树LOD地形论文和一个叫做“
曾涛
”大神的代码实现,小弟在此先向诸位致敬了。下面分享本人实践之后的一点心得。
也许看完了传说中的“龙书”有关地形那章,你就知道了一个简单的地形系统是怎么实现的,无非就是根据高度图提供的高度信息以及每个高度像素在高度图中所在的位置计算出地形顶点在3D空间中的世界坐标,然后根据各个地形顶点的拓扑关系计算出每个地形三角形面需要由哪三个顶点组成,这样就能够让渲染API以绘制三角面的方式拼接出三维地形了。
但是,我们应该注意到,若地形边长为n,那么组成地形的三角形个数就会是2*n^2。很明显,若直接将计算出来的三角形图元扔给渲染API,那么算法的复杂度就会是O(n^2),且渲染这些三角形的工作都必须在一帧的时间内完成。这样一来,无论是CPU或者是GPU的开销都非常大,地形稍微变大,机器要做的工作就要多很多,实时程序随时变成播放幻灯片。况且,如果地形比较大,那么在远处的地形三角形被投影到屏幕上时也许已经变成了几个像素点,甚至不可见了。既然远处的地形对我们的视觉贡献不大,那么为什么还要辛辛苦苦地让硬件做那么多的无用功呢?
有没有办法不渲染那些远到看不见的地形三角形呢?答案是有的。那就是LOD地形。LOD的全称是“Level Of Detail”(细节层级),基本的要求是:在近处的地形渲染得尽可能详细,在远处的地形渲染得尽可能简单。通常,LOD地形除了“远粗近细”的功能外,一般还加上了“视锥体可见性剔除”功能,即只考虑在视野范围内的地形三角形是否渲染,而绝不渲染在视野外的。这样的“简化”+“剔除”机制可以大幅度降低机器的开销,听起来是挺有吸引力的,但是究竟怎么实现呢?
实现LOD的难点:
根据我的经验,我觉的实现LOD有如下两个难点:1、以何种方式对地形进行简化;2、如何解决地形简化之后出现的T型裂缝;3、在视点移动时,原本远处被简化的地形区域在靠近视点后突然变得详细起来,或者原本在近处详细显示的地形区域远离视点之后突然被简化了,这样就可能造成某些地形细节的突然出现或者突然消失,在有光照的情况下,这种现象尤为明显,如何解决这个问题?
对于第三个问题,我当时由于时间原因来不及考虑,但是发现将地形进行平滑处理后可以减轻这种“突隐突现”现象,而且还能减少三角形面数的显示,于是将计就计了。如何对地形进行平滑?你可以在PS中事先对高度图进行模糊处理,又或者可以在程序中使用滤波算法对高度图进行滤波,方法应该很多,我就不纠结了。前两个问题是我回顾的重点。
地形的表示:
想要对地形进行简化,首先要知道地形是如何表示的。
我们先不理会地形在内存中的数据组成,我们先来理解下地形在逻辑上的表示。地形是由 (2^n+1) X (2^n+1) 个顶点组成,其中n>0,n究竟要多大?我觉得跟n有关系的计算都不溢出就好
。左下图就是个9X9的地形例子,实际上的地形不会那么小,几百X几百甚至成千上万也不奇怪,这里只是为了举例说明而已。另外,组成地形的基本单元也不再像龙书中那样使用一个个的独立三角形,而是使用三角形扇为地形基本单位,这里的三角形扇其实也是由8个三角形组成,在渲染API中使用9个顶点和10个索引表示。我们不妨把这样组成的三角形扇称为一个地形结点。如右下图表示:

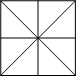
由三角形扇组成的地形 一个地形结点
为什么地形大小被限制为
(2^n+1) X (2^n+1) 个顶点呢?这是因为用四叉树来简化地形就必须使用这种的尺寸,这样在每一次分割地形结点时才能刚好划分成四个等分。大家可以
把每个交点都当成顶点,
自己比划一下左上方那幅图。从上面也可以看出,使用三角形扇来组成地形时,可以简单地用一个三角形扇来代替几个小的三角形扇组成的大块地形,这也是简化的关键所在之一。当然,这块地形要被评估为比较平坦的表面才可以这样替换。
简化流程预览:
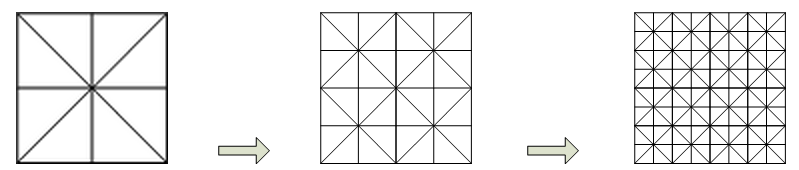
地形结点由低分辨率到高分辨率的过程
上面就是某
个大地形块被细分为多个小地形块的简单过程。大地形的简化实际上是从“粗糙”到“精细”的一个过程,而不是真正地由繁到简。
在实际的细化过程中,地形是按分辨率级别来处理的。地形四个角落的顶点以及四条边上的中点加上地形中间的那个顶点,就构成了最大的地形结点,这个结点算作第0级分辨率结点,之后每次划分得到的四个结点的分辨率就递增1个级别,最小的不可再分的地形结点就是最高级分辨率结点。这样划分分辨率级别有什么好处?这样方便我们在代码实现时使用分辨率级别快速确定地形结点的中心顶点在顶点缓冲区中的索引值。说起来很抽象,后面看代码就清楚了。
简化流程开始,首先评估0级结点是否需要被分割,通常来说都会被分成四个子节点,然后分别评估四个子结点是否需要继续划分。
若地形结点需要分割,则把它再分为四个结点,然后对四个结点分别再判断是否需要继续分割,如此递归下去,直到分割到最小地形结点或结点不可分为止。最小的地形结点无法再进行分割,只有送到渲染API进行渲染。
若地形结点不需要被分割,也是直接送入渲染API进行渲染。当
然,这些结点前提是要在我们的视野范围内才会进行上述的分割判断,否则,我们就直接忽略它们,不做任何处理。
在细化的过程中,若某地形结点被评估为不可分结点时,后面的细化步骤就被中断了,这时我们可以简单理解为该不可分结点的细节已经达到要求,可以代替一系列小的地形结点,我们就只显示该不可分结点,而不显示后续一系列小地形结点,这样我们就达到了简化目的。由于有些结点需要分割有些不需要,所以最后得到的结果不会像上面三幅图那么规则,也许像这样:

地形简化后可能的样子,这里假设视点在左上角
由上面的简化流程可以看出,简化过程实际上是个递归的过程,在实时性要求比较高的大地形系统中使用递归算法,实在不能算是一个比较好的解决方案。于是,潘大神提出“使用双队列来化解递归”的想法。
上面的图片展示了双队列化解递归的过程。格子代表地形结点,数字代表结点的级别。需要分割的结点将分割后得到的子结点压入第二条队列中,自己弹出第一条队列。不需要分割的结点直接弹出第一条队列并送入渲染API。在第一条队列中所有结点都被处理完毕后,两条队列交换身份,第二条队列变成第一条,然后重复之前处理步骤,直到两条队列中都没有结点为止。
结点评价系统:
上面说到了评估,对的,我们需要一个评价系统来确定一个地形结点是否需要被分割。
那么这个评价系统到底是怎么样的呢?
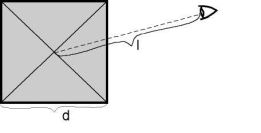
引用潘大神的图片
首先,我们的LOD需要实现地形“远简近繁”的效果,远和近靠什么来度量?潘大神使用“视点”到“地形结点中心”的距离。但是仅靠距离来衡量一个地形结点是否需要被分割是不够的。因为有可能一个结点大得离谱但却远在天边,若该结点不分割又会造成地形细节大量损失;又或者一个结点小得可怜却近在眼前,本来已经可以表示足够的地形细节了但却依然被分割了。所以,为了处理好这两种情况,我们还要考虑结点的大小。把两个因素放在一起考虑,由此得出潘大神的第一条评价公式:
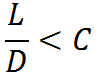
在上面的公式中,L代表视点到地形结点中心的距离,D代表地形结点的边长,C是一个调节因子。这个公式表示,当结点离视点越来越远,且地形结点越来越小时,两者的比值超过C,地形结点就不需要分割。这个调节因子是要根据地形显示的结果来确定的,也就是要在地形系统实现后,在测试阶段进行该因子的调整。
嗯,看似评价系统就是这样了,但细想一下,仅有上面这个条件就够了吗?假如有些地形块凹凸起伏很大,无论这些大地形块结点离视点的距离多远,我们都要求清楚地看到这块地形凹凸不平的特征,若仅靠上面的公式来对结点进行评判,距离一拉远,凹凸不平的地形就被一个平坦的地形结点代替了,这样一来地形就失真了。所以,我们还需要考虑地形结点的粗糙度。
如何定义地形结点的粗糙度?潘大神这样做:
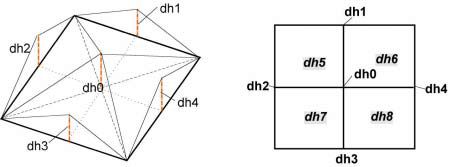
若一个地形结点被简化后才显示是和实际地形结点有误差的。比如左上图中,底下的平面代表简化后的地形结点,上面笼罩着的是实际的地形结点。直观上,我们会发现有5个误差,在图中显示为结点边上的dh1、dh2、dh3、dh4以及中心处的dh0。为保证误差测量结果尽量准确,我们还要考虑大地形结点被分割成4个子地形结点后,每个子节点的粗糙度,在右上图中表示为dh5、dh6、dh7、dh8。那子节点的粗糙程度怎么算?我们只需要重复地像计算大结点粗糙度那样就行了,很容易发现这是个递归的过程。那如果一个地形结点已经分割到没有子节点时怎么办?那就忽略dh5~8,只考虑前5个误差只就行了。
上面的粗糙度计算虽然是个递归过程,但是完全可以放在预处理阶段计算,将结果存放在一个与顶点缓冲区一样大的数组中就行了,评价结点时直接取值计算,不影响实时效率。
找出了这几个误差值之后还没完工,一个地形结点的粗糙程度 R 应该这样算:
R=Max(dh0 ,······ , dh8) / D
地形结点的粗糙度应该等于最大误差值除以地形结点的边长。那么,一个地形结点越粗糙就越不应该被简化,由此得出潘大神的第二条评价公式:
上面公式中的C2是粗糙调节因子,也是像第一条评价公式中的C那样,需要在地形系统实现后测试调整。那么,将两条评价公式一合并就变成了这样:
可以意识到,若C和C2越大,地形的细节就会越多,简化程度就越低,显示的三角形就会越多,机器的开销就会越大。前面我还说过,若将地形平滑处理,
“突隐突现”现象
就会减小,且三角形的渲染数也减少了,从上面的公式中也很容易就知道这是怎么回事。这是因为将地形进行平滑处理之后,地形的粗糙度R降低了,直观上看,简化显示和实际显示的误差不会太大,于是“突”现象就不那么明显了;从公式上看,R值小,地形结点被简化的几率增高了,于是相对显示的三角形就少了。
修补T型裂缝:
知道了地形怎么表示,大致的简化流程,以及如何评价一个结点是否需要分割,那么LOD是否就完成了呢?算是吧······但是还不够完美。
细想一下,有些结点需要分割,有些结点不需要分割,那么如果不加以控制的话,分割程度相差很大的结点接壤在一起时就会形成T型裂缝。如下图所示:
我相信上面的图片已经能很好地告诉读者T型裂缝是怎么产生的,以及在实际程序中裂缝是什么样子的。那如何修补T型裂缝呢?
首先,我们必须先控制好接壤的地形结点之间的级别差不能超过1。左上角图片那种就是典型的符合要求的接壤类型,而如下类型因为接壤结点之间的级别差已经超过1,所以不符合要求:
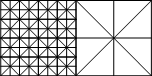
那该如何实现这样的控制呢?我们必须为地形增设一个标志数组,该数组的元素个数等于地形顶点数,元素类型不用太浪费,用char就好,只需表示0和1。
可以暂时将0理解为对应结点不存在,将1理解为对应结点存在。这句话不理解没关系,先记住。
该标志数组的作用是:在当前结点进行分割时提供四周结点的存在信息,若四周的结点都存在则当前结点可以分割,否则,只要四周任意一个结点不存在,当前结点就不能分割。这一步判断是在前面的评价系统之后才执行的,也就是说,评价系统的判断优先于这一步判断,只有两个阶段的判断都通过了,结点才能算真正地可以被分割。
那么标志数组中的存在信息是如何获得的呢?
这就需要我们在结点的分割操作中更新该标志数组。如何更新?当一个结点可以分割时,将自身对应的标志位设为1,同时将四个子结点对应的标志位也设为1。当一个结点不能分割时,
将自身对应的标志位也设为1,但同时将四个子结点对应的标志位设为0。我想大家一定会对“结点对应的标志位”这个说法很不解,其实在代码实现的时候,一个结点只需要用中心顶点的索引以及所属级别来表示就行了,只是送入渲染API时才转换成10个索引表示的三角形扇,到时看代码就知道了。很抽象是吧?下面我来用9X9的例子演示一下。
初始标志数组全0,现假设视点在左上角。一开始地形块太大,假设被评估为需要分割,那么标志数组改动就像下面左中两幅图:
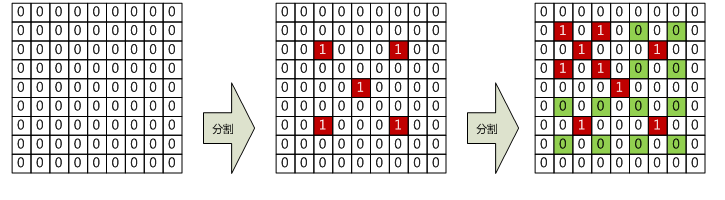
那么4个子结点在第二轮循环中被处理,逐一判断是否需要被分割。假设只有离视点比较近的左上角结点才能被分割,其他的都不能被分割,那么标志数组又会变成右上图的样子。
注意,右上图中左上角的那个结点能够被分割不是纯粹靠评价系统来评估的,还需要看看四周同等级结点的标志位是否都为1。大家应该能发现左上角结点的正右方结点和正下方结点的标志位确实为1,可是正左方和正上方的结点去哪找?这时我们只要简单地忽略不考虑就好了(PS:大地形中那些远离边缘的结点是要考虑四个方向的)。话说回来,中间那幅图的大地形结点在分割时需不需要考虑四周的标志位?当然要,但是去哪找?道理同前。现在看看判断四周标志后不可分的情况。

上图右方的结点的父结点是先被判断为不可分结点的,现在导致了右方结点实际不存在。所以,即使左方结点后来通过了评价系统的分割评估,但在查看四周结点标志时,发现右方结点不存在,所以左方结点分割失败。分析完毕。
到目前为止,接壤结点之间的级别差已经控制在1级之内,可以进行T型裂缝消除了。有了标志数组的帮助,消除T型裂缝实际上非常容易。前面提到过,在地形进行分割时,地形结点可以用结点中心顶点所在的索引和结点所属的级别表示,在送到渲染API时再转换成10个顶点索引表示的三角形扇。嘿!我们就是要在结点转换成10个索引的过程中消除裂缝。怎么做?请看下图:
看到了左图,我想大家应该更加理解标志数组中的1和0所表示的存在与不存在具体是什么意思了吧!实际上我也不知道怎么解释得更通俗易懂了。我直接说中间那幅图了。根据地形结点的中心顶点的索引和结点所属级别,我们可以很快地找到表示三角形扇的9个顶点的索引。中间那幅图图就是所谓的用9个顶点、10个索引表示的三角形扇。我们从左图可以发现,高分辨率级别的结点(即小结点)的正右方的标志位是0,代表正右方同等级别的结点不存在,根据这一信息,我们就可以把中间那幅图中的三角形扇的4号结点给忽略,这就导致0、3、5结点可以组成一个大点的三角面,而不再需要分别显示0、3、4和0、4、5组成的三角形。这个操作就消除掉了由4号结点引起的高度差,T型裂缝就是这样被消除掉了,如右上图。也就是说,我们可以根据一个结点四周相邻同等级别的结点对应的标志位是否为1来确定中间节点四条边中点的顶点是否参与渲染,从而消除裂缝。
修补T型裂缝到此结束。
LOD最终简化流程:
唉!~四叉树LOD的回顾就差不多这样了。感觉有必要做个重要代码回顾,还是改天有时间写个下篇吧。本文不作为个人技术的创新展示,只是学习心得的分享,所有知识都来自大神们的研究成果。关于潘李亮的论文和曾涛的代码实现,改天再补上链接,现在得休息············