搭建eclipse下运行mapreduce代码的环境
搭建eclipse下运行mapreduce代码的环境
准备:基本的hadoop环境搭建好,并启动hadoop。
Hadoop集群环境: 10.20.153.125 h5 master
10.20.153.126 h6 slave
10.20.153.127 h7 slave
版本:hadoop-1.0.0;
eclipse-SDK-3.7.2-linux-gtk
系统:VMWare下的ubuntu
第一步:由于hadoop-1.0.0源码中没有自带eclipse的插件,所幸,师傅帮我编译生成了org.apache.hadoop.eclipse_1.0.0.jar。把这个插件拷到 eclipse安装目录/plugins/ 下。
第二步:重启eclipse,配置hadoop installation directory。
若插件安装成功的话,打开Window-->Preferens,会发现Hadoop Map/Reduce选项,在这个选项里需要配置Hadoop installation directory。配置完成后退出。

这里需要注意的是:根据你即将要跑的代码是在当前这个hadoop版本的目录下。
第三步:配置Map/Reduce Locations。
在Window-->Show View中打开Map/Reduce Locations。Eclipse窗口下会有如下显示。

在这个View中,右键-->New Hadoop Location。弹出如下对话框:
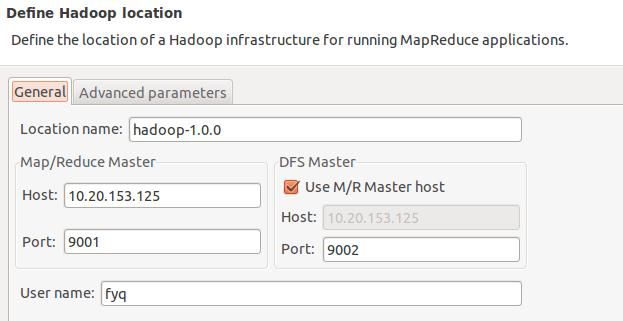
需要配置Location name,还有Map/Reduce Master和DFS Master。这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。
这个对话框下面的这个可以不管。
配置完了,会在eclipse窗口看到

这里我是建了两个DFS Locations,hadoop连接的192.168.71.128就是没有配置好,下面的hadoop-1.0.0就是配置好了。
第四步:新建项目。
File-->New-->Other-->Map/Reduce Project。
随便可以取个工程名。现在以hadoop自带的WordCount.java为例来说明如何运行这个mapreduce任务。
把hadoop安装目录下的/src/example/org/apache/hadoop/example/WordCount.java复制到刚才新建的项目下面。
第五步:创建输入文件。
1.在终端连上机器10.20.153.125,在这台机器上新建input文件夹:
[email protected]:/home/hadoop/hadoop-1.0.0>mkdir input;
接着创建两个file文件:

2.将本机上的输入文件上传到hdfs上:
[email protected]:/home/hadoop/hadoop-1.0.0/bin>hadoop fs -put /home/hadoop/hadoop-1.0.0/input input
这个输入文件input被创建在hdfs上的/user/hadoop/input这里
第六步:运行代码。
1. 在新建的项目WordCount,点击WordCount.java,右键-->Run As-->Run Configurations
2.在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
3.配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,

这里主要的设置就是Arguments,hdfs:10.20.153.125:9002/user/hadoop/input是输入文件目录,hdfs:10.20.153.125:9002/user/hadoop/output是输出目录。
4.设置完了就点下这个Run,运行程序,过段时间将运行完成,等运行结束后,可以在终端中用命令:hadoop fs –ls /user/hadoop/output
结果如下:

OK,结束啦~~~