C语言中的面向对象技术---模拟对象(百度移动端笔试题之一)
从网上看完这些资料后,太感慨了,任何技术都是递推演变形成的.
在用结构体 + 函数指针 模拟 对象的实现过程, 和 iOS 中的block 实现代理有些微妙
此时想到前几天的百度校招,大概也是这个设计题,当时没想到用函数指针,而且还很得意..哎,无知....
第一份:简单,明了
来源:http://blog.csdn.net/yusiguyuan/article/details/12355309
Linux内核的开发人员都是绝顶聪明的人,他们利用C语言的结构体,并在结构体中建立函数指针的字段,就好像C++中的所有字段都是 public,由此,实现了面向对象的思想。
下面,我写了一段测试代码,实现C语言的面向对象,如下所示:
- /**
- * @author DLUTBruceZhang
- * 2013.8.23
- */
- #include<stdio.h>
- #include<string.h>
- struct apple
- {
- char *color;
- float weight;
- float price;
- void (*buy)(struct apple ale);
- };
- void buy_apple(struct apple ale);
- int main(void)
- {
- struct apple MyApple;
- MyApple.color = (char*)malloc(sizeof(char) * 10);
- strcpy(MyApple.color, "red");
- MyApple.weight = 0.15;
- MyApple.price = 1.5;
- MyApple.buy = buy_apple;
- MyApple.buy(MyApple);
- free(MyApple.color);
- printf("\n");
- printf("You konw, this is C's OOP !\n");
- }
- void buy_apple(struct apple ale)
- {
- ("Today I buy a %s apple, it %f kg, it costs me %f $ .", ale.color, ale.weight, ale.price);
- }
第二份: 算是进阶吧,实现了继承,多态
来源:http://www.cnblogs.com/bakasen/archive/2012/08/20/2647561.html
其实早就想写这篇文章很久了,由于先前有个项目需要用到C来制作其系统架构,后来由于其他原因一直没有时间写出来,现在将把我那里学习到的东西一一道上。
应该很多人都认为面向对象的语言开发起来十分方便。由于其封装、继承等特性使面向对象语言更容易明确其结构,使开发过程中的结构清晰。从另一方面看面向对象语言在运行时将比非面向对象语言更耗资源、运行性能上也有所下降,这可能是导致现有的驱动程序大多使用C语言开发的原因。也许有人会问,现在IC能力都这么强,为什么还会执着着那个资源及运算能力呢?对于消费类电子可能这个影响不大,但对于工业方面来说这可能是致命的(实时要求较高)。好了,不扯远了,现在开始逐步进入正题。
重温面向对象语言:
在说到这里时,我当作大家都了解并开发过C++(及类似的面向对象的语言)。面向对象语言中,有几个重要概念:继承、多态、重载、封装。
继承主要是为了得到父类中的一些变量及函数(或方法),这样可以抽象出类的共性,当子类继承后可以减少一些变量和函数的重复声明,达到类的复用,也可以减少类与变量和函数的硬性绑定(全写在一个类中)。
多态是指利用父类指针/名称(C++中是指针,Java是名称)可以引用子类对象,来达到调用子类的函数。
重载是指一个类中的方法与另一个方法同名,但是参数表不同。
封装主要是通过确定变量和函数的访问类型来达到哪些变量函数可以对外使用(public),哪些变量函数不能对外使用(private),以及哪些变量函数可以被继承(protected)。
技术应用:
Unix和Linux都是利用C语言来开发的,但完全使用结构化式编程会使其结构混乱,据说开发者也把C语言“类面向对象化”,使其结构更加清晰(具体我没有研究过),大家可以看看Linux内核代码来了解这种编程方式。
应用实况:
由于本人是在ARM中开发,而且没有使用操作系统,因此为了防止内存泄漏等问题,所以我没有使用动态创建(malloc、calloc、realloc)。因此有些模仿可能叙述不到。
实例叙述:
要利用C语言模仿面向对象的功能是可以的,但并不能与面向对象的概念相混淆,只能说是功能相近,并不是相同。
下面将讲述本人的见解,如果不当之处,请高手指点!!
一、C语言中的“类”
1)定义“类”的成员变量
C语言没有类,但可以使用结构体充当一个类:
type struct CClass { struct CClass this; //获取结构体自身指针 int m_nNum; char *p; ... //自行添加更多变量 }CClass;
与类不同,结构体只能定义变量,不能够定义函数,可以通过函数指针的方法来实现其功能。
注:函数指针在很多情况下都不建议使用,这并不是它不好用,而是容易出错,而且出错后也难道测试出出错的位置。其实指针在C语言中是最强大的东西(个人认为),但由于容易出错才有那么多人反对使用。在使用指针(不管什么指针)都要注意,以防出错。
2)定义“类”的成员变量及函数
typedef struct CClass { struct CClass this; int m_nNum; char *p; ... //自行添加更多变量 void (*MyFunction)(struct CClass this,int Num); ... //自行添加更多函数 }CClass;
好了,这里定义了函数指针,感觉是不是很像一个类?也许有人会问,为什么加入一个struct CClass this 在函数第一个参数呢?
原因是这样的,由于结构体不像类,类中可以随意调用类中的成员,但是结构体却不一样,它无法得知结构体中的变量,因此可能通过参数形式传入。这里struct CClass this也方便了函数的调用。
3)定义“类”的构造函数
与面向对象不同,C语言的“类”的构造函数不能放在“类”中,只能放在“类”外。
CClass * CClassCtor(CClass *this);
其中函数名可以任意取(只要一看就明白,就行了),构造函数主要是变量的初始化,以及函数指针的赋值。
4)“类”中函数的绑定
void MyFunction(struct CClass this,int Num) { //具体操作 } CClass * CClassCtor(CClass *this) { this->m_nNum = 0; this->p = 'a'; this->MyFunction = MyFunction; }
这里MyFunction函数名称可以任取,主要通过赋值来匹配函数指针。
当调用“类”CClass中的MyFunction时,只要->MyFunction()就可以了,如下。
CClass *pClass,objClass; //定义一指针、一结构体变量
pClass = CClassCtor(&objClass); //调用构造函数
pClass->MyFunction(pClass,10); //调用MyFunction函数
5)“类”中的不足
C语言中的“类”并不能够像面向对象语言那样,通过public、protected、private来控制变量、函数的访问。
二、C语言中“类”的“继承”
其实结构体并没有继承可言,只是尽量做到类似继承。
1)“继承”方式1
由于没有继承机制,只能简单地重写变量函数(我觉得这方法很蠢,但是最直观,但也最容易出错,而且一但父类修改后,其所有子类都得修改)
typedef struct CFather { struct CFather *this char m_Name[10]; int m_Age; void (*Walk)(); }CFather; typedef struct CSon { struct CSon *this //这个来自父“类”,但要改为当前“类”指针类型 //来自父“类”的变量及函数 char m_Name[10]; int m_Age; void (*Walk)(); //子“类”定义的函数 int m_PocketMoney; void (*UsePocketMoney)(int nNum); }CSon;
可能有些人在编写面向对象语言时,会把变量和函数分开。但在C语言的“类”中,如果想达到“继承”,必须先写父“类”变量函数,再写新增的变量函数,而且变量及函数上的数量及顺序得完全一致(后面将讲述原因)。
注:“继承”时,子“类”应包含父“类”的所以变量及函数,而且顺序上完全一致,当写完父“类”变量及函数时,再写子“类”的变量和函数。
2)“继承”方式2
这种方式主要通过内嵌结构体指针来达到“继承”。这样可以减少重复的代码,而且可以减少漏写的问题。(这种方法当修改父类时,并不影响子类结构,只要修改相应函数功能即可。但是调用父类函数时,显得很臃肿)
typedef struct CFather { struct CFather *this char m_Name[10]; int m_Age; void (*Walk)(); }CFather; typedef struct CSon { //来自父“类”的变量及函数 CFather *m_pfather; //(或CFather m_father;) //子“类”定义的函数 int m_PocketMoney; void (*UsePocketMoney)(int nNum); }CSon;
当使用指针时,可以通过malloc、calloc等来动态创建父结点,也可以在全局中定义再向指针赋地址。
三、C语言中“类”的“多态”
前面说过,父“类”的顺序要与子“类”上的数量及顺序一致,主要是为了实现“多态”。那么C语言怎么实现“多态”呢?
由于结构体是一片连续的内存区域,因此当结构体被声明时,将分配特定的顺序,再加上各个类型有各自的大小(通过sizeof()可以得出),可以通过大小要获取某片区域的内容。
父“类”指针就像一个内存映射表,当父类指向子“类”时,父“类”会按其顺序从头到尾与子“类”开始对应,但通常子“类”声明的都比父类多,所以子“类”的部分变量及函数并没有被父“类”指针所以映射,也因此达到了“多态”的效果。
只有在使用“继承”方式1 和 “继承”方式2中的非指针父“类”时,才能够使用其“多态”特性。
使用“继承”方式1 好还是使用“继承”方式2,这就得看具体需求了。
1)方式1虽然比较蠢,但是这样只要“指针->函数()”即可调用其函数。
2)使用“继承”方式2,当子“类”还有多个子“类”时,将使用多个“指针->father.[father. ···]函数()”来调用。
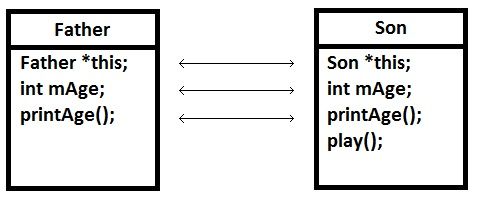
下图为方式一的“类”定义,其中“父类”中的成员,“子类”要全部重复写一遍,当“父类”指针指向“子类”时,可以通过调用printAge();来调用“子类”中对应的函数。
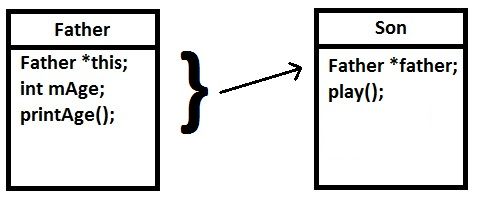
下图为方式二的“类”定义,其中“子类”包含了“父类”中的成员,使用些方法不利于“多态”,因为不管体积指针,都会占用相同大小的内存空间,导致内存地址并不对应,即当调用printAge()时,将会出现指针异常。
如果想使用类似上面的包含关系,而且又想利用“多态”,可以写成如下:
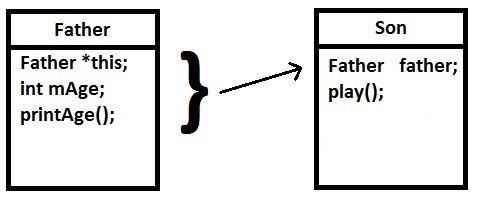
这样使用包含非指针的方法,可以达到又包含,又“多态”的效果,但是有没有不良效果,本人并没有仔细研究。
四、C语言中函数的重载
其实在C语言中,并不可以函数同名,因为重载在C语言中也成为不可能的事件了(可能只是我不会实现而已)。
五、C语言中的封装性
C语言中也并没有像C++那样的封装性,因为只要变量或函数在头文件中声明了,就可以被随意调用。如果不想变量或函数被调用,可以在.c文件中声明静态变量或函数。这样,即使头文件被包含了,也可以把数据封装在.c文件中,即使它没有像C++那优秀的封装性。
总结:
利用上面方法,可以提高代码的利用性,可以类似C++等面向对象语言一样,通过加“类”,来构建自己想要的效果。以上皆是本人学习时使用的方法及自身理解的一些观点。如果有不当之处请提出,方便我去改正。
第三份: 姑且当做高级篇吧,太晦涩了....
来源:
http://www.360doc.com/content/11/1219/15/1299815_173400715.shtml
Linux使用了struct这个来实现对象,函数指针来实现方法。比如说,设备是一个类,每一个驱动程序都将这个类实例化,然后交给内核。
linux内核大量地使用了oo的思想,只是没有用C++罢了。凡是那些结构体里有函数指针表的基本都借鉴了oo的思想,而这些函数的参数中又有一个参数是指向这个结构体的指针,相当于this指针。
linux内核大量使用面向对象的编码风格。然而linux内核是完全使用C写就。学习他们如何使用C模拟面向对象机制很有意思。这种做法很可能被人贬为扯淡,但是的确使用C模拟面向对象机制,使得程序员对类型构造/析构,拷贝/赋值等操作有了绝对的控制权,可以提高对效率的嗅觉,减少错误,同时也避免了对C++编译器各种不同类/对象实现机制的依赖。
类的多态特征是linux内核经常用到的。例如在驱动代码中常常使用函数指针来定义一组设备操作函数,从而模拟了多态的特点。
struct file_operations scull_fops = {
.owner = THIS_MODULE,
.llseek = scull_llseek,
.read = scull_read,
.write = scull_write,
.ioctl = scull_ioctl,
.open = scull_open,
.release = scull_release,
};
上面的例子是Linux Device Driver中抄来的示例代码。很好地展示了file operation结构体如何使用这种机制来定义一组文件操作的方式。用这种方式,Linux很好地贯彻了所有的设备都是文件这种概念。不同的设备可以有不同的处理函数,但使用相同的接口(read,write...),这样就把底层设备的差异在文件系统这一层隔离开来了。
Linux内核中也经常用到类的继承关系。这种关系使用C也很容易模拟,就是使用结构体嵌套。例如
struct scull_dev {
struct scull_qset *data;
int quantum;
int qset;
unsigned long size;
unsigned int access_key;
struct semaphore sem;
struct cdev cdev; //内嵌linux内核定义的cdev结构体
};
这个例子同样来自LDD。注意在自定义的cdev字符设备结构体中包含了struct cdev cdev成员。这个成员同样是一个结构体,由内核定义,是字符设备描述符。使用这种方式,可以一定程度模拟C++的继承机制,当然有他的局限,例如他不能如同在C++中一样直接引用cdev的成员,而必须通过scull_dev.cdev来引用。
另一方面,这种方式也无法通过“基类”,即cdev的指针,访问“子类”,即scull_dev的成员。精彩的部分来了,linux通过一组宏,巧妙的实现了这一点。在文件处理的函数中,入参会给入inode指针,从这个指针可获得其cdev成员。如何从这个cdev成员获取包含它的“子类”对象,scull_dev的指针呢?
container_of(ptr, type, member)
使用这个宏,container_of(inode->i_cdev, struct scull_dev, cdev)就可获得包含cdev的scull_dev的地址。这个巧妙的宏是如何实现的呢?
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr);
(type *)( (char *)__mptr - offsetof(type,member) );})
这个宏首先定义一个指向结构体成员的指针__mptr = (ptr),他的类型是const typeof(...)。这里用到了C语言一个较新的关键字typeof,可以在编译期获得变量的类型。而这个类型是((type*)0)->member,这里type和member分别是宏传入的参数。这一行代码就比较清晰了。得到这个__mptr之后,将他向回移动一个offset,(char*)__mprt - offsetof(...),而这个offset恰好为member相对于type的偏移量,offsetof(type,member),则移动完毕__mptr就指向type类型的起始地址了,只需将其转换为type*类型就可以了,(type*)(...)。
好了,这个宏已经看懂,神奇的地方就出在这个offsetof宏了,他是如何计算成员相对于结构体的偏移量呢?这里linux内核hacker们用了一个小小trick。
#define offsetof(s, m) (size_t)&(((s *)0)->m)
是的,代码非常简单。其思想是,假如结构体处于0地址,获取其成员的地址。这个地址就是成员相对于结构体初始地址的偏移量了。没错0地址是不能运行时访问的,但这句代码只在编译期使用了0地址,因此是合法的。当然其实使用成员指针和结构体指针相减也可做到,但用这种方式可以减少一次运算,确保了这个宏可以在编译期求出结果。可谓是精益求精。
我说错了。即使使用减法也可以做到编译期求值,因为结构体和成员指针地址都是可以编译期得到的,常量数值计算应该可以做到编译期优化,计算完成。这种做法应该是
&((type*)0)->member - ((type*)0)
这样的代码的一个直觉性的优化,减0的话,何必还要减呢。事实上两句代码的运行时间是一样的,但这样做可以减轻编译时间。
在container_of宏中,也有一句减法计算。这个计算引用了运行时求值的__mptr,所以无法做到编译期求值。
类似这种用法,在linux内核中经常出现。深深佩服大牛们的创造力,并且深深的意识到了即使是C语言也是学无止境的。
举例:面向对象的思想在linux设备模型中的应用分析.
通过设备模型,看到了面向对象编程思想用C语言的实现。内核中常见到封装了数据和方法的结构体,这是面向对象封装特性的实现。而这里展现的更多的是继承方面的实现。比如说pci_driver,它的父类是device_driver,而更上一层是一个kobject。在C++中,继承一个父类则子类中相应的包含父类的一个实例。内核中也是通过包含一个父类的实体来实现这种派生关系。因此,一个pci_driver内部必然包含一个device_driver,同样,device_driver内部必然包含一个kobject。
上面提到过,注册一个模型的过程类似于面向对象中构造函数的调用。子类需要调用父类构造函数来完成自身的构造。再来看看注册一个pci_driver的过程:
pci_register_driver(struct pci_driver *driver)
-->driver_register(&drv->driver);
-->kobject_register(&drv->kobj);
这不是OO中的继承么?
设备模型源码中还能找到多态(虚函数)的思想。看到pci_driver和device_driver中提供了差不多同名的方法不觉得奇怪吗??它们不同的地方在于参数。pci_driver中方法的参数是pci_device * dev ,而device_driver方法的参数则是 device *dev 。这么安排是有意的!
最典型的例子莫过于platform_driver和device_driver。
struct platform_driver {
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*resume)(struct platform_device *);
struct device_driver driver;
};
这显然比pci_driver来得简洁。platform_driver除了包含一个device_driver,其它就是5个与device_driver同名的方法。
注册一个platform_driver的过程:
int platform_driver_register(struct platform_driver *drv)
{
drv->driver.bus = &platform_bus_type;
if (drv->probe)
drv->driver.probe = platform_drv_probe;
if (drv->remove)
drv->driver.remove = platform_drv_remove;
if (drv->shutdown)
drv->driver.shutdown = platform_drv_shutdown;
if (drv->suspend)
drv->driver.suspend = platform_drv_suspend;
if (drv->resume)
drv->driver.resume = platform_drv_resume;
return driver_register(&drv->driver);
}
这里设置了platform_driver包含的device_driver的函数指针。看看这些函数中的platform_drv_probe。
static int platform_drv_probe(struct device *_dev)
{
struct platform_driver *drv = to_platform_driver(_dev->driver);
struct platform_device *dev = to_platform_device(_dev);
return drv->probe(dev);
}
这里出现了两个指针类型转换(通过container_of()宏实现的),然后调用platform_driver提供的probe函数。
考 虑一下platform_driver的注册过程。每个驱动注册过程相同。如前面分析过的,进入到driver_register后,设备驱动device_driver层的probe将会被调用来探测设备,这个函数像上面源码所指示的那样完成类型转化调用其子类platform_driver层的probe函数来完成具体的功能。那么,从device_driver层看来,相同的函数调用由子类来完成了不同的具体功能。这不是多态的思想么??
这里非常粗浅的分析了linux设备模型中使用C实现面向对象的三大要素(封装,继承,多态)的基本思想。用C来实现确实做的工作要多一些,不过灵活性更高了。怪不得linus炮轰C++.
"使用优秀的、高效的、系统级的和可移植的C++的唯一方式,最终还是限于使用C本身具有的所有特性。"