Flume相关技术汇总
这些知识基本来源网络,我自己收集了一下做个汇总。
1、简介
Flume支持在日志系统中定制各类数据发送方,用于收集数据。Flume最早是Cloudera提供的日志收集系统,目前是Apache下的一个孵化项目。
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
官网:http://flume.apache.org/。源码可以从git 获取,地址:https://git-wip-us.apache.org/repos/asf/flume.git,或者从官网获取:http://flume.apache.org/download.html。解压即可,下面是解压后得到的文件:
bin目录放的是启动脚本,conf目录放的是配置文件,lib是放的是所必须的jar包,logs是日志目录。其他几个基本上不会使用到。
2、原理
flume-ng 是由一个个agent组成的。一个agent就像一个细胞一样。
每个agent里都有三部分构成:source、channel和sink。
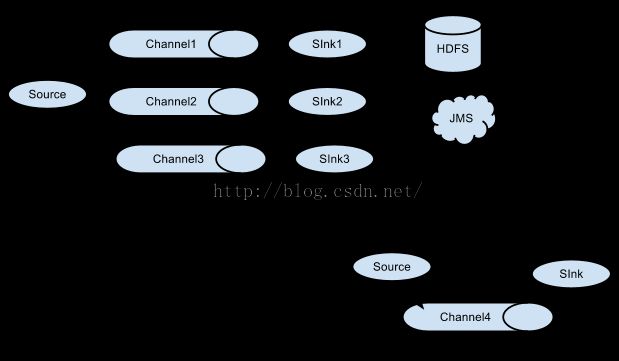
就相当于source接收数据,通过channel传输数据,sink把数据写到下一端。其中source有很多种可以选择,channel有很多种可以选择,sink也同样有多种可以选择,并且都支持自定义。同时,agent还支持选择器,就是一个source支持多个channel和多个sink,这样就完成了数据的分发。其架构图如下:

当然可以自由组合,如下图:

时序图如下:
Flume为了保证数据的完整性和一致性,在每个agent里面都加了事务。
当然,也可以这么配:
3、组件
Flume-ng(现网使用的是1.5.2)支持的主要几个组件如下:
| 组件 |
类型 |
描述 |
实现类 |
| Channel |
memory |
写入内存,特点快,容易内存溢出 |
MemoryChannel |
| Channel |
file |
写入文件,特点稳定、慢 |
FileChannel |
| Channel |
spillablememory |
内存与文件结合使用 |
SpillableMemoryChannel |
| Channel |
jdbc |
基于jdbc的持久化传输(derby) |
JDBCChannel |
| Channel |
recoverablememory |
持久化结合本地文件存储 |
RecoverableMemoryChannel |
| Channel |
org.apache.flume.channel.PseudoTxnMemoryChannel |
用于测试,不适合生产使用。 |
PseudoTxnMemoryChannel |
| Channel |
(custom FQCN) |
自定义channel实现 |
(custom FQCN) |
| Source |
avro |
使用Avro Netty RPC协议 |
AvroSource |
| Source |
exec |
从Unix读取tail -F |
ExecSource |
| Source |
netcat |
网关数据源 |
NetcatSource |
| Source |
seq |
单调递增序列发生器的事件源 |
SequenceGeneratorSource |
| Source |
org.apache.flume.source.StressSource |
用于测试,不适合生产使用。 |
org.apache.flume.source.StressSource |
| Source |
syslogtcp |
|
SyslogTcpSource |
| Source |
syslogudp |
|
SyslogUDPSource |
| Source |
org.apache.flume.source.avroLegacy. AvroLegacySource |
|
AvroLegacySource |
| Source |
org.apache.flume.source.thriftLegacy. ThriftLegacySource |
|
ThriftLegacySource |
| Source |
org.apache.flume.source.scribe.ScribeSource |
|
ScribeSource |
| Source |
(custom FQCN) |
自定义source |
(custom FQCN) |
| Sink |
hdfs |
写入HDFS |
HDFSEventSink |
| Sink |
org.apache.flume.sink.hbase.HBaseSink |
写入HBase |
org.apache.flume.sink.hbase.HBaseSink |
| Sink |
org.apache.flume.sink.hbase.AsyncHBaseSink |
|
org.apache.flume.sink.hbase. AsyncHBaseSink |
| Sink |
logger |
写入日志 |
LoggerSink |
| Sink |
avro |
使用AVRO RPC机制 |
AvroSink |
| Sink |
file_roll |
|
RollingFileSink |
| Sink |
irc |
|
IRCSink |
| Sink |
null |
丢弃所有events |
NullSink |
| Sink |
(custom FQCN) |
自定义sink |
(custom FQCN) |
| ChannelSelector |
replicating |
|
ReplicatingChannelSelector |
| ChannelSelector |
multiplexing |
|
MultiplexingChannelSelector |
| ChannelSelector |
(custom type) |
自定义ChannelSelector 实现 |
(custom FQCN) |
| SinkProcessor |
default |
|
DefaultSinkProcessor |
| SinkProcessor |
failover |
failover的机器是一直发送给其中一个 优先级高的sink,当这个sink不可用的时候, 自动发送到下一个sink |
FailoverSinkProcessor |
| SinkProcessor |
load_balance |
处理一个sink的group组,为每个sink 提供了负载平衡流的能力。 |
LoadBalancingSinkProcessor |
| SinkProcessor |
(custom FQCN) |
自定义SinkProcessor 实现 |
(custom FQCN) |
| Interceptor$Builder |
host |
使用IP或hostname拦截 |
HostInterceptor$Builder |
| Interceptor$Builder |
timestamp |
使用时间戳拦截 |
TimestampInterceptor$Builder |
| Interceptor$Builder |
static |
可以自定义event的header的value |
StaticInterceptor$Builder |
| Interceptor$Builder |
regex_filter |
提取正则表达式匹配组 |
RegexFilteringInterceptor$Builder |
| Interceptor$Builder |
(custom FQCN) |
自定义 Interceptor$Builder实现 |
(custom FQCN) |
* 1.6的版本还提供了kafkaChannel,性能比memoryChannel差,但比fileChannel好;而且稳定性不输fileChannel,比memoryChannel更稳定。
Flume1.5.2提供的jar包:
4、实现
实现很简单,通过配置。
案例1、avro
a1.channels = c1 a1.sources = r1 a1.sinks = k1 a1.channels.c1.type = memory a1.sources.r1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 41414 a1.sinks.k1.channel = c1 a1.sinks.k1.type = logger
案例2:Spool
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.channels = c1 a1.sources.r1.spoolDir = /home/hadoop/flume-1.5.0-bin/logs a1.sources.r1.fileHeader = true a1.sinks.k1.type = logger a1.sinks.k1.channel = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
案例3:Exec
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.channels = c1 a1.sources.r1.command = tail -F /home/hadoop/flume-1.5.0-bin/log_exec_tail a1.sinks.k1.type = logger a1.sinks.k1.channel = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
案例4:Syslogtcp
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = syslogtcp a1.sources.r1.port = 5140 a1.sources.r1.host = localhost a1.sources.r1.channels = c1 a1.sinks.k1.type = logger a1.sinks.k1.channel = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
案例5:JSONHandler
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = org.apache.flume.source.http.HTTPSource a1.sources.r1.port = 8888 a1.sources.r1.channels = c1 a1.sinks.k1.type = logger a1.sinks.k1.channel = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
启动脚本:
bin/flume-ng agent --conf ./conf/ -f conf/flume.conf -Dflume.root.logger=DEBUG,console -n a1
对应的agent名字a1 ,依赖的环境JDK1.6+。
5、自定义组件
如果是自定义的source、sink,(channel不建议自定义),可以这么配置:
agent01.sources = kafka0 agent01.channels = ch0 agent01.sinks = sink0 agent01.sources.kafka0.type = cn.com.coreware.source.KafkaSource agent01.sources.kafka0.channels = ch0 agent01.sources.kafka0.zookeeper.connect = 127.0.0.1:2181 agent01.sources.kafka0.batchSize = 15000 agent01.channels.ch3.type = memory agent01.channels.ch3.keep-alive = 30 agent01.channels.ch3.transactionCapacity = 10000 agent01.channels.ch3.capacity = 100000 agent01.sinks.sink0.type = cn.com.coreware.sink.ScalaSink agent01.sinks.sink0.channel = ch0 agent01.sinks.sink0.batchsize = 1000
红色部分是自定义的类(全包名),把自定义的类打成jar包,放到lib目录。
为了减少IO访问,提高性能。一般都要设置batchSize。
自定义的source类需要继承org.apache.flume.source.AbstractSource,并实现org.apache.flume.conf.Configurable、org.apache.flume.EventDrivenSource接口。
重写父类的方法:configure(初始化配置)、start(启动入口,非必须)、stop(停止)、process(处理)。
自定义sink也是一样需要继承需要继承org.apache.flume.sink.AbstractSink,并实现Configurable接口。
重写父类的方法:configure(初始化配置)、start(启动入口,非必须)、stop(停止)、process(处理)。
自定义拦截器Interceptor都实现了org.apache.flume.interceptor.Interceptor接口,该接口有四个方法以及一个内部接口:
1、public void initialize()运行前的初始化,一般不需要实现(上面的几个都没实现这个方法);
2、public Event intercept(Event event)处理单个event;
3、public List<Event> intercept(List<Event> events)批量处理event,实际上市循环调用上面的2;
4、public void close()可以做一些清理工作,上面几个也都没有实现这个方法;
5、public interface Builder extends Configurable 构建Interceptor对象,外部使用这个Builder来获取Interceptor对象。
Builder类是构造interceptor对象的,它会首先通过configure(Context context)方法获取配置文件中interceptor的参数,然后方法build()用来返回一个interceptor对象
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new Interceptor();
}
@Override
public void configure(Context context) {
//TO-DO
}
}
自定义拦截器的配置
a1.sources.r1.interceptors=i1 a1.sources.r1.interceptors.i1.type=com.coreware.flume.RegexInterceptor$Builder a1.sources.r1.interceptors.i1.regex=(.*)\\.(.*)\\.(.*) a1.sources.r1.interceptors.i1.extractorHeader=true a1.sources.r1.interceptors.i1.extractorHeaderKey=basename a1.sources.r1.interceptors.i1.serializers=s1 s2 s3 a1.sources.r1.interceptors.i1.serializers.s1.name=one a1.sources.r1.interceptors.i1.serializers.s2.name=two a1.sources.r1.interceptors.i1.serializers.s3.name=three
正则表达式按“.”分隔抽取三部分,分别放到header中的key:one,two,three当中去,如:event body有这样的内容
a.log.2014-07-31,通过拦截器后,在header当中就会增加三个key: one=a,two=log,three=2014-07-31。
6、Flume 内置监控
Flume的内置监控可以使用Cloudera Manager、Ganglia有图形的监控工具,以及从浏览器获取json串(Http),或者自定义向其他监控系统汇报信息。
Flume天生支持这两种监控方式:HTTP方式(就是json串)和Ganglia,后者需要安装Ganglia,前者非常简单,只需要在Flume的启动命令中加上:-Dflume.monitoring.type=http -Dflume.monitoring.port=XXXX ,最后的XXXX是你需要设置的端口!然后你就可以在浏览器上通过访问这个Flume所在节点的IP:XXXX/metrics,不断刷新就可以看到最新的组件统计信息。关于Ganglia的请读者自行组建Ganglia集群并参考用户指南来操作。
目前只对三大组件:source、sink、channel进行统计分别是SourceCounter、SinkCounter、ChannelCounter,这三个计数器的统计项是固定的,就是你不能自己设置自己的统计项;他们都继承自MonitoredCounterGroup。
(1)、构造方法MonitoredCounterGroup(Type type, String name, String... attrs),这个方法主要是设置组件的类型、名称;然后将所有的attrs(这是设定的各个统计项)加入Map<String, AtomicLong> counterMap,值设定为0;然后初始化计数器的开始时间和结束时间,都设为0。
(2)、start()方法,会先注册计数器,然后对所有统计项的统计值设为0;将开始时间设置为当前时间
(3)、register()方法,如果这个计数器还未注册,将这个计数器的MBean进行注册,就可以进行跟踪了
(4)、stop()方法,会设置结束时间为当前时间;输出各个统计项的信息。
三个组件中各种统计项及其含义:
一、SourceCounter,主要统计项如下:
(1)、"src.events.received",表示source接受的event个数;
(2)、"src.events.accepted",表示source处理成功的event个数,和上面的区别就是上面虽然接受了可能没处理成功;
(3)、"src.append.received",表示调用append次数,在avrosource和thriftsource中调用;
(4)、"src.append.accepted",表示append处理成功次数;
(5)、"src.append-batch.received",表示appendBatch被调用的次数,在avrosource和thriftsource中调用;
(6)、"src.append-batch.accepted",表示appendBatch处理成功次数;
(7)、"src.open-connection.count",用在avrosource中表示打开连接的数量;
一般source调用都集中在前俩。
一、SinkCounter,主要统计项如下:
(1)、"sink.connection.creation.count",这个调用的地方颇多,都表示“链接”创建的数量,比如与HBase、avrosource建立链接以及文件的打开等;
(2)、"sink.connection.closed.count",对应于上面的stop操作、destroyConnection、close文件操作等。
(3)、"sink.connection.failed.count",表示上面所表示“链接”时异常、失败的次数;
(4)、"sink.batch.empty",表示这个批次处理的event数量为0的情况;
(5)、"sink.batch.underflow",表示这个批次处理的event的数量介于0和配置的batchSize之间;
(6)、"sink.batch.complete",表示这个批次处理的event数量等于设定的batchSize;
(7)、"sink.event.drain.attempt",准备处理的event的个数;
(8)、"sink.event.drain.sucess",这个表示处理成功的event数量,与上面不同的是上面的是还未处理的。
三、ChannelCounter,主要统计项如下:
(1)、"channel.current.size",这个表示这个channel的当前容量;
(2)、"channel.event.put.attempt",一般指的是在channel的事务当中,source的put操作中记录尝试发送event的个数;
(3)、"channel.event.take.attempt",一般指的是在channel的事务中,sink的take操作记录尝试拿event的个数;
(4)、"channel.event.put.success",一般指的是在channel的事务中,put成功的event的数量;
(5)、"channel.event.take.success",一般指的是channel事务中,take成功的event的数量;
(6)、"channel.capacity",指的是channel的容量,在channel的start方法中设置。
上面这些统计项都是固定的,我们可以根据需要增加相应项的值,可以在监控中查看组件的变化情况,从而掌握flume进程的运行情况。比如可以查看channel的容量从而了解到source和sink的相对处理速度,还有可以看source或者sink每个批次处理成功与失败的次数,了解组件的运行状况等等。
自定义Counter必须要继承MonitoredCounterGroup这个抽象类并实现SourceCounterMBean接口,设定自己的统计项,然后将统计项设置成数组调用MonitoredCounterGroup的构造函数;然后在自定义的计数器中增加更新数值的方法。最后在自定义的组件中构造自定义的计数器,并启用它的start方法,剩下的就是在该更新统计项数值的地方更新就可以了。例:
private static final String COUNTER_KAFKA_SEND_FLOW = "sink.kafka.send.flow";
private static final String[] ATTRIBUTES = {COUNTER_KAFKA_SEND_FLOW };
public KafkaSinkCounter(String name) {
super(name, ATTRIBUTES);
}
public long countKafkaSendFlow(long delta) {
return addAndGet(COUNTER_KAFKA_SEND_FLOW, delta);
}
public long getKafkaSendFlowCount() {
return get(COUNTER_KAFKA_SEND_FLOW);
}
然后将计数器、监控类、自定义组件(source、sink、channel)打包放到lib下,在启动命令后加-Dflume.monitoring.type=AAAAA -Dflume.monitoring.node=BBBB,就可以了
7、实现案例
我们来看source是怎么把数据msg放到channel的:
ChannelProcessor channelProcessor = source.getChannelProcessor(); Event eTmp = EventBuilder.withBody(msg.getBytes()); channelProcessor.processEvent(eTmp);
sink又是怎么取出来的:
Channel channel = getChannel();
Transaction tx = channel.getTransaction();
tx.begin();//事务
List<KeyedMessage<byte[], byte[]>> batch = Lists.newLinkedList();
for (int i = 0; i < batchSize; i++) {
Event event = channel.take();//获取event(一条日志)
byte[] bs=event.getBody();
batch.add(new KeyedMessage<byte[], byte[]>(topic, bs));
}
producer.send(batch);//发送给kafka
tx.commit();//提交事务
之前介绍flume可以配置多个channel和sink,在flume的设计上,实现这一点是很容易的,下面是我们的实际的案例:
agent01.sources = kafka0 agent01.channels = ch0 ch1 agent01.sinks = sink0 sink1 agent01.sources.kafka0.type = cn.com.coreware.source.KafkaSource agent01.sources.kafka0.channels = ch0 ch1 agent01.sources.kafka0.zookeeper.connect = 192.168.117.131:2181 agent01.sources.kafka0.zookeeper.session.timeout.ms = 50000 agent01.sources.kafka0.zookeeper.connection.timeout.ms = 40000 #replicating,multiplexing agent01.sources.kafka0.selector.type= replicating agent01.channels.ch0.type = memory agent01.channels.ch0.capacity = 40000 agent01.channels.ch0.transactionCapacity = 10000 agent01.channels.ch1.type = memory agent01.channels.ch1.capacity = 40000 agent01.channels.ch1.transactionCapacity = 10000 agent01.sinks.sink0.channel = ch0 agent01.sinks.sink0.type=FILE_ROLL agent01.sinks.sink0.sink.directory=Z:/flume/data agent01.sinks.sink0.sink.rollSize=1000000 agent01.sinks.sink1.channel = ch1 agent01.sinks.sink1.type = hdfs agent01.sinks.sink1.hdfs.useLocalTimeStamp = true agent01.sinks.sink1.hdfs.path = hdfs://127.0.0.1:9000/flume/events/%y/%m/%d agent01.sinks.sink1.hdfs.filePrefix = flume-%H%M agent01.sinks.sink1.hdfs.batchSize = 5000 #DataStream,SequenceFile,CompressedStream agent01.sinks.sink1.hdfs.fileType = DataStream #HEADER_AND_TEXT,TEXT,AVRO_EVENT agent01.sinks.sink1.hdfs.writeFormat = TEXT agent01.sinks.sink1.hdfs.minBlockReplicas = 1 agent01.sinks.sink1.hdfs.rollInterval = 3600 agent01.sinks.sink1.hdfs.rollSize = 0 agent01.sinks.sink1.hdfs.rollCount = 0 agent01.sinks.sink1.hdfs.idleTimeout = 0
Agent Source的selector.type有两种方式:replicating,multiplexing。
采用replicating的方式进行复制,对收到的报文复制成两份,发往不同的channel,最终送给相应的sink。如上面的配置
采用multiplexing的方式进行选择,对收到的报文进行分类,发往不同的channel,最终送给相应的sink。
agent1.sources.kafka0.channels = ch0 ch1 agent1.sources.kafka0.header = LOG_TYPE agent1.sources.kafka0.selector.type = multiplexing agent1.sources.kafka0.selector.header = LOG_TYPE agent1.sources.kafka0.selector.mapping.CREDIT = ch0 agent1.sources.kafka0.selector.mapping.OTHER = ch1 agent1.sources.kafka0.selector.default = ch1
这里标红的header 是指在获取的报文里面的header属性。一个event分为header和body两部分。在header里面有一个LOG_TYPE字段,LOG_TYPE字段有两个值:CREDIT 、OTHER ,针对CREDIT 的发送到ch0,而OTHER 的发送到ch1,默认是选择ch1。使用这种方式需要对数据进行加工,把LOG_TYPE放入到header里面。
Event event = channel.take();
event.getHeaders().put("LOG_TYPE","CREDIT");
//event.getHeaders().put("LOG_TYPE","OTHER");
为了数据的可靠性及程序的性能,可以在多个sink里面设置成sinkgroups,实现如下:
实现load balance功能(处理一个sink的group组,为每个sink提供了负载均衡的能力)
a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 k3 a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.backoff = true a1.sinkgroups.g1.processor.selector = round_robin a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
实现 failover 功能 ( failover的机器是一直发送给其中一个优先级高的sink,当这个sink不可用的时候,自动发送到下一个sink)
a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 k3 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 7 a1.sinkgroups.g1.processor.priority.k3 = 6 a1.sinkgroups.g1.processor.maxpenalty = 20000
我们只要稍微修改一下配置,就可以实现不同的功能需求,在这点flume非常适用。
8、Flume-NG的一些注意事项
A、关于Source:
1、spool-source:适合静态文件,即文件本身不是动态变化的;
2、avro source可以适当提高线程数量来提高此source性能;
3、ThriftSource在使用时有个问题需要注意,使用批量操作时出现异常并不会打印异常内容而是"Thrift source %s could not append events to the channel.",这是因为源码中在出现异常时,它并未捕获异常而是获取组件名称,这是源码中的一个bug,也可以说明thrift很少有人用,否则这个问题也不会存在在很多版本中;
4、如果一个source对应多个channel,默认就是每个channel是同样的一份数据,会把这批数据复制N份发送到N个channel中,所以如果某个channel满了会影响整体的速度的哦;
5、ExecSource官方文档已经说明是异步的,可能会丢数据哦,尽量使用tail -F,注意是大写的;
B、关于Channel:
1、采集节点建议使用新的复合类型的SpillableMemoryChannel,汇总节点建议采用memory channel,具体还要看实际的数据量,一般每分钟数据量超过120MB大小的flume agent都建议用memory channel(自己测的file channel处理速率大概是2M/s,不同机器、不同环境可能不同,这里只提供参考),因为一旦此agent的channel出现溢出情况,将会导致大多数时间处于file channel(SpillableMemoryChannel本身是file channel的一个子类,而且复合channel会保证一定的event的顺序的使得读完内存中的数据后,再需要把溢出的拿走,可能这时内存已满又会溢出。。。),性能大大降低,汇总一旦成为这样后果可想而知;
2、调整memory 占用物理内存空间,需要两个参数byteCapacityBufferPercentage(默认是20)和byteCapacity(默认是JVM最大可用内存的0.8)来控制,计算公式是:byteCapacity = (int)((context.getLong("byteCapacity", defaultByteCapacity).longValue() * (1 - byteCapacityBufferPercentage * .01 )) /byteCapacitySlotSize),很明显可以调节这两个参数来控制,至于byteCapacitySlotSize默认是100,将物理内存转换成槽(slot)数,这样易于管理,但是可能会浪费空间;
3、还有一个有用的参数"keep-alive"这个参数用来控制channel满时影响source的发送,channel空时影响sink的消费,就是等待时间,默认是3s,超过这个时间就甩异常,一般不需配置,但是有些情况很有用,比如你得场景是每分钟开头集中发一次数据,这时每分钟的开头量可能比较大,后面会越来越小,这时你可以调大这个参数,不至于出现channel满了得情况;
C、关于Sink:
1、avro sink的batch-size可以设置大一点,默认是100,增大会减少RPC次数,提高性能;
2、内置hdfs sink的解析时间戳来设置目录或者文件前缀非常损耗性能,因为是基于正则来匹配的,可以通过修改源码来替换解析时间功能来极大提升性能;
3、RollingFileSink文件名不能自定义,而且不能定时滚动文件,只能按时间间隔滚动,可以自己定义sink,来做定时写文件;
4、hdfs sink的文件名中的时间戳部分不能省去,可增加前缀、后缀以及正在写的文件的前后缀等信息;"hdfs.idleTimeout"这个参数很有意义,指的是正在写的hdfs文件多长时间不更新就关闭文件,建议都配置上,比如你设置了解析时间戳存不同的目录、文件名,而且rollInterval=0、rollCount=0、rollSize=1000000,如果这个时间内的数据量达不到rollSize的要求而且后续的写入新的文件中了,就是一直打开,类似情景不注意的话可能很多;"hdfs.callTimeout"这个参数指的是每个hdfs操作(读、写、打开、关闭等)规定的最长操作时间,每个操作都会放入"hdfs.threadsPoolSize"指定的线程池中得一个线程来操作;
如果启用压缩,则rollSize指的是未压缩文件大小,压缩后大小未知。
5、关于HBase sink(非异步hbase sink:AsyncHBaseSink),rowkey不能自定义,而且一个serializer只能写一列,一个serializer按正则匹配多个列,性能可能存在问题,建议自己根据需求写一个hbase sink;
6、avro sink可以配置failover和loadbalance,所用的组件和sinkgroup中的是一样的,而且也可以在此配置压缩选项,需要在avro source中配置解压缩;
D、关于SinkGroup:
1、不管是loadbalance或者是failover的多个sink需要共用一个channel;
2、loadbalance的多个sink如果都是直接输出到同一种设备,比如都是hdfs,性能并不会有明显增加,因为sinkgroup是单线程的它的process方法会轮流调用每个sink去channel中take数据,并确保处理正确,使得是顺序操作的,但是如果是发送到下一级的flume agent就不一样了,take操作是顺序的,但是下一级agent的写入操作是并行的,所以肯定是快的;
3、其实用loadbalance在一定意义上可以起到failover的作用,生产环境量大建议loadbalance;
E、关于监控monitor:
1、监控我这边做得还是比较少的,但是目前已知的有以下几种吧:cloudera manager(前提是你得安装CDH版本)、ganglia(这个天生就是支持的)、http(其实就是将统计信息jmx信息,封装成json串,使用jetty展示在浏览器中而已)、再一个就是自己实现收集监控信息,自己做(可以收集http的信息或者自己实现相应的接口实现自己的逻辑,具体可以参考我以前的博客);
2、简单说一下cloudera manager这种监控,最近在使用,确实很强大,可以查看实时的channel进出数据速率、channel实时容量、sink的出速率、source的入速率等等,图形化的东西确实很丰富很直观,可以提供很多flume agent整体运行情况的信息和潜在的一些信息;
3、自定义的监控要放到包:org.apache.flume 的包里面,否则不会加载。
F、关于flume启动:
1、flume组件启动顺序:channels——>sinks——>sources,关闭顺序:sources——>sinks——>channels;
2、自动加载配置文件功能,会先关闭所有组件,再重启所有组件;
3、关于AbstractConfigurationProvider中的Map<Class<? extends Channel>, Map<String, Channel>> channelCache这个对象,始终存储着agent中得所有channel对象,因为在动态加载时,channel中可能还有未消费完的数据,但是需要对channel重新配置,所以用以来缓存channel对象的所有数据及配置信息;
4、通过在启动命令中添加"no-reload-conf"参数为true来取消自动加载配置文件功能;