深度分析:Magic Leap与微软Hololens有哪些异同
深度分析:Magic Leap与微软Hololens有哪些异同

本文作者:@胡伯涛 Botao Amber Hu,清华大学姚班本科,斯坦福计算机系研究生毕业,方向为计算摄影和人工智能,目前从事以无人机和虚拟现实技术实现的计算摄影研究。光流科技CEO,CTO,C*O。曾在Google, Microsoft Research, Pinterest, Twitter工作或实习过。
最近看到国内网络上突然Magic Leap的话题火了,并且跟着很多人无理由和根据的赞或黑Magic Leap。我在斯坦福计算机系上学的时候,对Magic Leap很好奇,正好在学校能接触到各路和Magic Leap相关的大神,所以在这方面做了些研究,我觉得可以分享点技术性干货,解释一些原理,让大家有点材料来赞或黑。
目前Magic Leap只有一个公开视频是实际拍摄的(如下,桌腿后的机器人和太阳系),本文只以这个视频的例子来做阐释。
先说一下我关于Magic Leap的信息来源:
1、2014年11月10日,Magic Leap在2014年9月融了5个亿以后,来Stanford招人,开了一个Info Session,标题是“The World is Your New Desktop”(世界就是你的新桌面)多么霸气!当时是Magic Leap感知研究的高级副总裁(VP of Perception)Gary Bradski和计算视觉的技术负责人(Lead of Computer Vision)Jean-Yves Bouguet来作演讲。Gary是计算机视觉领域的领军人物,在柳树车库(Willow Garage)创造了OpenCV(计算视觉工具库),同时也是Stanford顾问教授。Jean-Yves原来在Google负责谷歌街景车(Street View Car)的制造,是计算视觉技术的大牛。他们加入Magic Leap是非常令人震惊的。我参加了这次Info Session,当时Gary来介绍Magic Leap在感知部分的技术和简单介绍传说中的数字光场Cinematic Reality的原理,并且在允许录影的部分都有拍照记录。本文大部分的干货来自这次演讲。

2、我今年年初上了Stanford计算摄影和数字光场显示的大牛教授Gordon Wetzstein的一门课:EE367 Computational Imaging and Display(计算影像和显示器):其中第四周的Computational illumination,Wearable displays和Displays Blocks(light field displays)这三节都讲到Magic Leap的原理。现在大家也可以去这个课程网站上看到这些资料,EE367 / CS448I: Computational Imaging and Display
顺便介绍一下Gordon所在的Stanford计算图形组,Marc Levoy(后来跑去造Google Glass的大牛教授)一直致力于光场的研究,从Marc Levoy提出光场相机,到他的学生Ren Ng开创Lytro公司制造光场相机,到现在Gordon教授制造光场显示器(裸眼光场3D显示器),这个组在光场方面的研究一直是世界的领头羊。而Magic Leap可能正在成为光场显示器的最大应用。(相关内容可参考:Computational Imaging Research Overview)
3、今年参加了光场影像技术的研讨会Workshop on Light Field Imaging ,现场有很多光场技术方面的展示,我和很多光场显示技术的大牛交流了对Magic Leap的看法。特别的是,现场体验了接近Magic Leap的光场技术Demo,来自Nvidia的Douglas Lanman的Near-Eye Light Field Displays 。(相关内容可参考:Near-Eye Light Field Displays)

4、今年年中去了微软研究院Redmond访问,研究院的首席研究员Richard Szeliski(计算机视觉大神,计算机视觉课本的作者,Computer Vision: Algorithms and Applications)让我们试用了Hololens。感受了Hololens牛逼无比的定位感知技术。有保密协议,本文不提供细节,但提供与Magic Leap原理性的比较。
下面是干货:
首先呢,科普一下Magic Leap和Hololens这类AR眼镜设备,都是为了让你看到现实中不存在的物体和现实世界融合在一起的图像并与其交互。从技术上讲,可以简单的看成两个部分:
对现实世界的感知(Perception);
一个头戴式显示器以呈现虚拟的影像 (Display) 。
我会分感知部分和显示部分来分别阐释Magic Leap的相关技术。
一、显示部分
先简单回答这个问题:
Q1. Hololens和Magic Leap有什么区别?Magic Leap的本质原理是什么?
在感知部分,其实Hololens和Magic Leap从技术方向上没有太大的差异,都是空间感知定位技术。本文之后会着重介绍。Magic Leap与Hololens最大的不同应该来自显示部分,Magic Leap是用光纤向视网膜直接投射整个数字光场(Digital Lightfield)产生所谓的Cinematic Reality(电影级的现实)。Hololens采用一个半透玻璃,从侧面DLP投影显示,虚拟物体是总是实的,与市场上Espon的眼镜显示器或Google Glass方案类似,是个2维显示器,视角还不大,40度左右,沉浸感会打折扣。
本质的物理原理是:光线在自由空间中的传播,是可以由4维光场唯一表示的。成像平面的每个像素中包含到这个像素所有方向的光的信息,对于成像平面来讲,方向是二维的,所以光场是4维的。平时成像过程只是对四维光场进行了一个二维积分(每个像素上所有方向的光的信息都叠加到一个像素点上),传统显示器显示这个2维的图像,是有另2维方向信息损失的。而Magic Leap是向你的视网膜直接投射整个4维光场, 所以人们通过Magic Leap看到的物体和看真实的物体从数学上是没有什么区别的,是没有信息损失的。理论上,使用Magic Leap的设备,你是无法区分虚拟物体和现实的物体的。
使用Magic Leap的设备,最明显的区别于其他技术的效果是人眼可以直接选择聚焦(主动选择性聚焦)。比如我要看近的物体,近的物体就实,远的就虚。注意:这不需要任何的人眼跟踪技术,因为投射的光场还原了所有信息,所以使用者直接可以做到人眼看哪实哪,和真实物体一样。举个例子:在虚拟太阳系视频的27秒左右(如下面这个gif图),摄影机失焦了,然后又对上了,这个过程只发生在摄影机里,和Magic Leap的设备无关。换句话说,虚拟物体就在那,怎么看是观察者自己的事。这就是Magic Leap牛逼的地方,所以Magic Leap管自己的效果叫Cinematic Reality。

Q2. 主动选择性聚焦有什么好处?传统的虚拟显示技术中,为什么你会头晕?Magic Leap是怎么解决这个问题的?
众所周知,人类的眼睛感知深度主要是靠两只眼睛和被观察物体做三角定位(双目定位,triangulation cue)来感知被观察物体的与观察者的距离的。但三角定位并不是唯一的人类感知深度的线索,人脑还集成了另一个重要的深度感知线索:人眼对焦引起的物体锐度(虚实)变化(sharpness or focus cue) 。但传统的双目虚拟显示技术(如Oculus Rift或Hololens)中的物体是没有虚实的。举个例子,如下图,当你看到远处的城堡的时候,近处的虚拟的猫就应该虚了,但传统显示技术中,猫还是实的,所以你的大脑就会引起错乱,以为猫是很远的很大的一个物体。但是这和你的双目定位的结果又不一致,经过几百万年进化的大脑程序一会儿以为猫在近处,一会儿以为猫在远处,来来回回你大脑就要烧了,于是你要吐了。而Magic Leap投影了整个光场,所以你可以主动选择性聚焦,这个虚拟的猫就放在了近处,你看它的时候就是实的,你看城堡的时候,它就是虚的,和真实情况一样,所以你不会晕。演讲中Gary调侃对于Jean-Yves这种带10分钟Oculus就吐的家伙来说,现在他一天带16个小时Magic Leap都不会晕。
补充:有人问为什么网上说虚拟现实头晕是因为帧率不够原因?
帧率和延时虽然是目前的主要问题,但都不是太大的问题,也不是导致晕得决定性因素。这些问题用更快的显卡,好的IMU和好的屏幕,还有头部动作预测算法都能很好解决。我们要关心一些本质的晕眩问题。
这里要说到虚拟现实和增强现实的不同。
虚拟现实中,使用者是看不到现实世界的,头晕往往是因为人类感知重力和加速度的内耳半规管感受到的运动和视觉看到的运动不匹配导致的。所以虚拟现实的游戏,往往会有晕车想吐的感觉。这个问题的解决不是靠单一设备可以搞定的,如果使用者的确坐在原定不动,如果图像在高速移动,什么装置能骗过你的内耳半规管呢?一些市场上的方案,比如Omni VR,或者HTC Vive这样的带Tracking的VR系统让你实际行走才解决这个不匹配的问题,但这类系统是受场地限制的。不过THE VOID的应用就很好的利用了VR的局限,不一定要跑跳,可以用很小的空间做很大的场景,让你以为你在一个大场景里就好了。现在大部分虚拟现实的体验或全景电影都会以比较慢得速度移动视角,否则你就吐了。
但是Magic Leap是AR增强现实,因为本来就看的到现实世界,所以不存在这个内耳半规管感知不匹配的问题。对于AR来讲,主要挑战是在解决眼前投影的物体和现实物体的锐度变化的问题。所以Magic Leap给出的解决方案是很好地解决这个问题的。但都是理论上的,至于实际工程能力怎么样就靠时间来证明了。
Q3. 为什么要有头戴式显示器?为什么不能裸眼全息?Magic Leap是怎么实现的?
人类希望能凭空看到一个虚拟物体,已经想了几百年了。各种科幻电影里也出现了很多在空气中的全息影像。
但其实想想本质就知道,这事从物理上很难实现:纯空气中没有可以反射或折射光的介质。显示东西最重要的是介质。很多微信上的疯传,以为Magic Leap不需要眼镜,我估计是翻译错误导致的,视频中写了Shot directly through Magic Leap tech.,很多文章错误的翻译成“直接看到”或“裸眼全息",其实视频是相机透过Magic Leap的技术拍的。
目前全息基本还停留在全息胶片的时代(如下图,我在光场研讨会上看到的这个全息胶片的小佛像),或者初音未来演唱会那种用投影阵列向特殊玻璃(只显示某一特定角度的图像,而忽略其他角度的光线)做的伪全息。
Magic Leap想实现的是把整个世界变成你的桌面这样的愿景。所以与其在世界各个地方造初音未来那样的3D全息透明屏做介质或弄个全息胶片,还不如直接从人眼入手,直接在眼前投入整个光场更容易。其实Nvidia也在做这种光场眼镜。
Nvidia采用的方法是在一个二维显示器前加上一个微镜头阵列Microlens array来生成4维光场。相当于把2维的像素映射成4维,自然分辨率不会高,所以这类光场显示器或相机(Lytro)的分辨率都不会高。本人亲测,效果基本就是在看马赛克画风的图案。
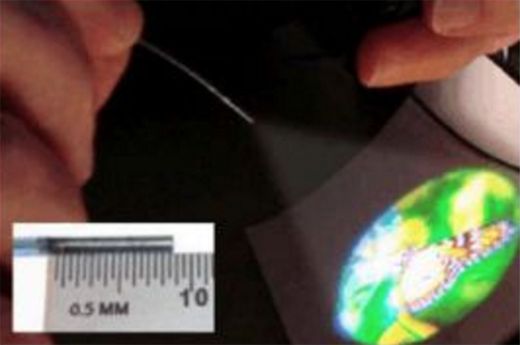
而Magic Leap采用完全不同的一个方法实现光场显示,它采用光纤投影。不过,Magic Leap用的光纤投影的方式也不是什么新东西。在Magic Leap做光纤投影显示(Fiber optic projector)的人是Brian Schowengerdt,他的导师是来自华盛顿大学的教授Eric Seibel,致力于做超高分辨率光纤内窥镜8年了。简单原理就是光纤束在一个1mm直径管道内高速旋转,改变旋转的方向,然后就可以扫描一个较大的范围。Magic Leap的创始人比较聪明的地方,是找到这些做高分辨率光纤扫描仪的,由于光的可逆性,倒过来就能做一个高分辨率投影仪。如图,他们6年前的论文,1mm宽9mm长的光纤就能投射几寸大的高清蝴蝶图像。现在的技术估计早就超过那个时候了。
而这样的光纤高分辨率投影仪还不能还原光场,需要在光纤的另一端放上一个微镜头阵列microlens array,来生成4维光场。你会疑问这不就和Nvidia的方法一样了么?不,因为光纤束是扫描性的旋转,这个microlens array不用做得很密很大,只要显示扫描到的区域就好了。相当与把大量数据在时间轴上分布开了,和通讯中的分时一样,因为人眼很难分辨100帧上的变化,只要扫描帧率够高,人眼就分辨不出显示器是否旋转显示的。所以Magic Leap的设备可以很小,分辨率可以很高。
他本人也来Stanford给过一个Talk,Near-to-Eye Volumetric 3D Displays using Scanned Light。这个Talk讲的应该就是Magic Leap早期的原型。(相关内容可参考: Fiber Scanned Displays)
二、感知部分
Q4. 首先为什么增强现实要有感知部分?
是因为设备需要知道自己在现实世界的位置(定位),和现实世界的三维结构(地图构建),才能够在显示器中的正确位置摆放上虚拟物体。举个最近的Magic Leap Demo视频的例子,比如桌子上有一个虚拟的太阳系,设备佩戴者的头移动得时候,太阳系还呆在原地,这就需要设备实时的知道观看者视角的精确位置和方向,才能反算出应该在什么位置显示图像。同时,可以看到桌面上还有太阳的反光,这就要做到设备知道桌子的三维结构和表面信息,才能正确的投射一个叠加影像在桌子的影像层上。难点是如何做到整个感知部分的实时计算,才能让设备穿戴者感觉不到延时。如果定位有延时,佩戴者会产生晕眩,并且虚拟物体在屏幕上漂移会显得非常的虚假,所谓Magic Leap宣称的电影级的真实(Cinematic Reality)就没有意义了。
三维感知部分并不是什么新东西,计算机视觉或机器人学中的SLAM(Simultaneous Localization And Mapping,即时定位与地图构建)就是做这个的,已经有30年的历史了。设备通过各种传感器(激光雷达,光学摄像头,深度摄像头,惯性传感器)的融合将得出设备自己在三位空间中的精确位置,同时又能将周围的三位空间实时重建。

最近SLAM技术尤其火爆,去年到今年两年时间内巨头们和风投收购和布局了超级多做空间定位技术的公司。因为目前最牛逼的3大科技技术趋势:无人车,虚拟现实,无人机,他们都离不开空间定位。SLAM是完成这些伟大项目基础中的基础。我也研究SLAM技术,所以接触的比较多,为了方便大家了解这个领域,这里简单提几个SLAM界最近的大事件和人物:
1、(无人车)Stanford的机器人教授Sebastian Thrun是现代SLAM技术的开创者,自从赢了DARPA Grand Challenge的无人车大赛后,去了Google造无人车了。SLAM学术圈的大部分研究派系都是Sebastian徒子徒孙。
2、(无人车)Uber在今年拿下了卡耐基梅隆CMU的NREC(国家机器人工程研发中心),合作成立高等技术研发中心ATC。这些原来做火星车的定位技术的研究人员都去Uber ATC做无人车了。
3、(虚拟现实)最近Surreal Vision被Oculus Rift收购,其中创始人Richard Newcombe是大名鼎鼎的DTAM,KinectFusion(HoloLens的核心技术)的发明人。Oculus Rift还在去年收购了13th Labs(在手机上做SLAM的公司)。
4、(虚拟现实)Google Project Tango 今年发布世界上第一台到手就用的商业化SLAM功能的平板。Apple五月收购Metaio AR,Metaio AR 的 SLAM 很早就用在了AR的app上了。Intel 发布Real Sense,一个可以做SLAM的深度摄像头,在CES上Demo了无人机自动壁障功能和自动巡线功能。
5、(无人机)由原来做Google X Project Wing 无人机的创始人MIT机器人大牛Nicholas Roy 的学生Adam Bry创办的Skydio,得到A16z的两千万估值的投资,挖来了Georgia Tech的SLAM大牛教授Frank Dellaert 做他们的首席科学家。(相关内容:http://www.cc.gatech.edu/~dellaert/FrankDellaert/Frank_Dellaert/Frank_Dellaert.html)
SLAM作为一种基础技术,其实全世界做SLAM或传感器融合做得好的大牛可能不会多于100人,并且大都互相认识。这么多大公司抢这么点人,竞争激烈程度可想而知,所以Magic Leap作为一个创业公司一定要融个大资,才能和大公司抢人才资源。
Q5. Magic Leap的感知部分的技术是怎么样的?
这张照片是Gary教授在Magic Leap Stanford 招聘会中展示了Magic Leap在感知部分的技术架构和技术路线。可以看到以Calibration为中心,展开成了4支不同的计算机视觉技术栈。

1、从图上看,整个Magic Leap感知部分的核心步骤是Calibration(图像或传感器校准),因为像Magic Leap或Hololens这类主动定位的设备,在设备上有各种用于定位的摄像头和传感器, 摄像头的参数和摄像头之间关系参数的校准是开始一切工作的第一步。这步如果摄像头和传感器参数都不准,后面的定位都是无稽之谈。从事过计算机视觉技术的都知道,传统的校验部分相当花时间,需要用摄像头拍摄Chess Board,一遍一遍的收集校验用的数据。但Magic Leap的Gary,他们发明了一种新的Calibration方法,直接用一个形状奇特的结构体做校正器,摄像头看一遍就完成了校正,极为迅速。这个部分现场不让拍照。
2、有了Calibration部分后,开始最重要的三维感知与定位部分(左下角的技术栈),分为4步。
2.1 首先是Planar Surface Tracking(平面表面跟踪)。大家可以在虚拟太阳系的Demo中看到虚拟太阳在桌子上有反光,且这个反光会随着设备佩戴者的移动而改变位置,就像是太阳真的悬在空中发出光源,在桌子表面反射产生的。这就要求设备实时地知道桌子的表面在哪里,并且算出虚拟太阳与平面的关系,才能将太阳的反光的位置算出来,叠在设备佩戴者眼镜相应的位子上,并且深度信息也是正确的。难点在平面检测的实时性和给出平面位置的平滑性(否则反光会有跳变)从Demo中可以看出Magic Leap在这步上完成得很好。

2.2 然后是Sparse SLAM(稀疏SLAM);Gary在Info Session上展示了他们实时的三维重构与定位算法。为了算法的实时性,他们先实现了高速的稀疏或半稀疏的三维定位算法。从效果上看,和目前开源的LSD算法差不了太多。
2.3 接着是Sensors; Vision and IMU(视觉和惯性传感器融合)。
导弹一般是用纯惯性传感器做主动定位,但同样的方法不能用于民用级的低精度惯性传感器,二次积分后一定会漂移。而光靠视觉做主动定位,视觉部分的处理速度不高,且容易被遮档,定位鲁棒性不高。将视觉和惯性传感器融合是最近几年非常流行的做法。
举例:
Google Tango在这方面就是做IMU和深度摄像头的融合,做的很好;大疆的无人机Phantom 3或Inspire 1将光流单目相机和无人机内的惯性传感器融合,在无GPS的情况下,就能达到非常惊人的稳定悬停;Hololens可以说在SLAM方面是做得相当好,专门定制了一个芯片做SLAM,算法据说一脉相承了KinectFusion的核心,亲自测试感觉定位效果很赞(我可以面对白色无特征的墙壁站和跳,但回到场中心后定位还是很准确的,一点都不飘。)
2.4 最后是3D Mapping and Dense SLAM(3D地图重建)。下图展示了Magic Leap山景城办公室的3D地图重建:仅仅是带着设备走了一圈,就还原了整个办公室的3D地图,并且有很精致的贴图。书架上的书都能重建的不变形。

因为AR的交互是全新的领域,为了让人能够顺利地和虚拟世界交互,基于机器视觉的识别和跟踪算法成了重中之重。全新人机交互体验部分需要大量的技术储备做支持。
接下来的三个分支,Gary没有细讲,但是可以看出他们的布局。我就随便加点注解,帮助大家理解。
3.1 Crowdsourcing众包。用于收集数据,用于之后的机器学习工作,要构建一个合理的反馈学习机制,动态的增量式的收集数据。
3.2 Machine Learning & Deep Learning机器学习与深度学习。需要搭建机器学习算法架构,用于之后的识别算法的生产。
3.3 Scenic Object Recognition场景物体识别。识别场景中的物体,分辨物体的种类,和特征,用于做出更好的交互。比如你看到一个小狗的时候,会识别出来,然后系统可以把狗狗p成个狗型怪兽,你就可以直接打怪了。
3.4 Behavior Recognition行为识别 。识别场景中的人或物的行为,比如跑还是跳,走还是坐,可能用于更加动态的游戏交互。顺便提一下,国内有家Stanford校友办的叫格林深瞳的公司也在做这个方面的研究。
跟踪方面
4.1 Gesture Recognition手势识别。用于交互,其实每个AR/VR公司都在做这方面的技术储备。
4.2 Object Tracking物体追踪。这个技术非常重要,比如Magic Leap的手捧大象的Demo,至少你要知道你的手的三维位置信息,实时Tracking,才能把大象放到正确的位子。
4.3 3D Scanning三维扫描。能够将现实物体,虚拟化。比如你拿起一个艺术品,通过三维扫描,远处的用户就能够在虚拟世界分享把玩同样的物体。
4.4 Human Tracking人体追踪。比如:可以将现实中的每个人物,头上可以加个血条,能力点之类。
5.1 Eye Tracking眼动跟踪。Gary解释说,虽然Magic Leap的呈像不需要眼动跟踪,但因为要计算4维光场,Magic Leap的渲染计算量巨大。如果做了眼动跟踪后,就可以减少3D引擎的物体渲染和场景渲染的压力,是一个优化的绝佳策略。
5.2 Emotion Recognition情感识别。如果Magic Leap要做一个Her电影中描绘的人工智能操作系统,识别主人得情感,可以做出贴心的情感陪护效果。
5.3 Biometrics生物识别。比如要识别现实场景中的人,在每个人头上显示个名字啥的。人脸识别是其中一种,国内有家清华姚班师兄弟们开得公司Face++就是干这个干的最好的。
总结:简单来讲感知这个部分Magic Leap其实和很多其他的公司大同小异,虽然有了Gary的加盟,野心非常的宽广,但这部分竞争非常激烈。
Q6: 就算Magic Leap已经搞定了感知和显示,那么接下来的困难是什么?
1、计算设备与计算量
Magic Leap要计算4维光场,计算量惊人。不知道Magic Leap现在是怎么解决的。如果Nvidia不给造牛逼的移动显卡怎么办?难道自己造专用电路?背着4块泰坦X上路可不是闹着玩的。
下图是,今年我参加SIGGraph 2015里,其中一个VR演示,每个人背着个大电脑包玩VR。10年后的人类看今天的人类追求VR会不会觉得很好笑,哈哈。

2、电池!电池!电池!所有电子设备的痛
3、一个操作系统
说实话,如果说“世界就是你的新桌面”是他们的愿景,现在的确没有什么操作系统可以支持Magic Leap愿景下的交互。他们必须自己发明轮子。
4、为虚拟物体交互体验增加物理感受
为了能有触感,现在交互手套,交互手柄都是 VR 界大热的话题。从目前的专利上看,并没有看出Magic Leap会有更高的见地。说不定某个Kickstarter最后能够独领风骚,Magic Leap再把他收了。
【版权声明】本文经作者本人同意,并以CC协议:BY-NC-ND 4.0进行授权(点击可查询协议文本),原文发布于知乎(点击查看原文)。