Solr+Hbase多条件查(优劣互补)
为什么要使用solr+hbase组合:
某电信项目中采用HBase来存储用户终端明细数据,供前台页面即时查询。HBase无可置疑拥有其优势,但其本身只对rowkey支持毫秒级的快速检索,对于多字段的组合查询却无能为力。针对HBase的多条件查询也有多种方案,但是这些方案要么太复杂,要么效率太低,本文只对基于Solr的HBase多条件查询方案进行测试和验证。
solr+habse组合的原理:
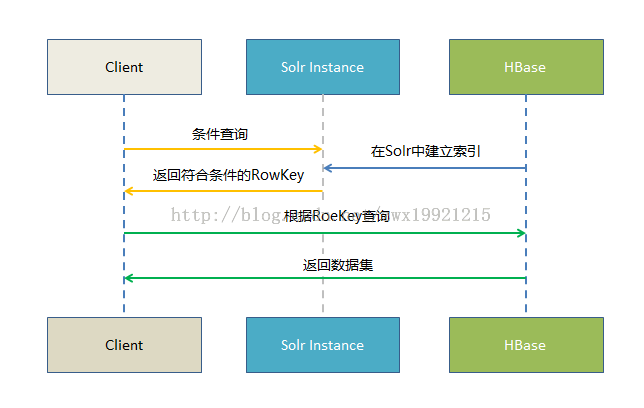
基于Solr的HBase多条件查询原理很简单,将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。
环境
1. 已搭建好的hadoop集群,3节点hadoop测试集群(见文档hadoop2.5完全分布式集群搭建)
2. 在hadoop集群之上搭建hbase集群(文档中hadoop2.5分布式中已包含)
3. 已搭建好的solrcloud集群,3节点solrcloud集群(见文档solrcloud分布式集群)
4. 从oracle中导入数据到hbase中(可以通过普通java代码或mapreduce,也可以直接使用工具sqoop)
5. 使用sqoop将oracle中的数据导入hbase中
sqoop实现数据从oracle导入hdfs(hbase)
sqoop import --append --connect jdbc:oracle:thin:@192.168.0.20:1521:orcl --username yqdev --password yq --m 1 --table c_text --columns id,url,title --hbase-create-table --hbase-table c_text --hbase-row-key id --column-family textinfo
注:需要在hbase中先创建c_text表,创建列族textinfo;我只导入了id,url,title三列,其中id为rowkey.
6. 创建索引
从hbase中读取数据,将需要用作查询字段添加索引到solr中(例如title)
/**
* create solrIndex
*
* @throws IOException
* @throws SolrServerException
*/
public static void addIndex() throws IOException, SolrServerException {
// hbase
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(FAMILY_NAME));
// scan.setCaching(500);
scan.setCacheBlocks(false);
ResultScanner rs = table.getScanner(scan);
System.out.println("start......");
Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
Long totalCount = 0l;
for (Result r : rs) {
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", new String(r.getRow()));
for (KeyValue kv : r.raw()) {
String fieldName = new String(kv.getQualifier());
String fieldValue = new String(kv.getValue());
if (fieldName.equalsIgnoreCase("id")
|| fieldName.equalsIgnoreCase("title")
|| fieldName.equalsIgnoreCase("url")) {
doc.addField(fieldName, fieldValue);
}
docs.add(doc);
}
if (docs.size() >= 1000) {
cloudSolrServer.add(docs);
cloudSolrServer.commit();
totalCount = totalCount + docs.size();
docs = new ArrayList<SolrInputDocument>();
System.out.println("already deal with : " + totalCount);
}
}
}
7. 查询测试
/**
* 1.query solrIndex pass some condition 2.query data from hbase pass rowkey
*
* @throws IOException
* @throws SolrServerException
*/
public static void query() throws IOException, SolrServerException {
Get get = null;
List<Get> list = new ArrayList<Get>();
SolrQuery query = new SolrQuery("title:基金");
query.setStart(0);
query.setRows(40);
QueryResponse response = cloudSolrServer.query(query);
SolrDocumentList docs = response.getResults();
System.out.println("total:" + docs.getNumFound());
System.out.println("query time:" + response.getQTime());
//get rowkey from solr
for (SolrDocument doc : docs) {
get = new Get(Bytes.toBytes((String) doc.getFieldValue("id")));
list.add(get);
}
//order rowkey query data from hbase
for (Get gt : list) {
Result result = table.get(gt);
byte[] value = result.getValue("textinfo".getBytes(),
"title".getBytes());
System.out.println("title------- \t" + new String(value));
}
}
hbase+solr多条件查询的设计方案:
(利用hbase的大数据存储和solr的强大的索引,达到互补的效果)
基于Solr的HBase多条件查询原理很简单,将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。
参考:http://www.cnblogs.com/chenz/articles/3229997.html