hdu【最长回文子串——Manacher算法】POJ 3974/HDU 3068
转载
原文地址:
http://zhuhongcheng.wordpress.com/2009/08/02/a-simple-linear-time-algorithm-for-finding-longest-palindrome-sub-string/
其实原文说得是比较清楚的,只是英文的,我这里写一份中文的吧。
首先:大家都知道什么叫回文串吧,这个算法要解决的就是一个字符串中最长的回文子串有多长。这个算法可以在O(n)的时间复杂度内既线性时间复杂度的情况下,求出以每个字符为中心的最长回文有多长,
这个算法有一个很巧妙的地方,它把奇数的回文串和偶数的回文串统一起来考虑了。这一点一直是在做回文串问题中时比较烦的地方。这个算法还有一个很好的地方就是充分利用了字符匹配的特殊性,避免了大量不必要的重复匹配。
算法大致过程是这样。先在每两个相邻字符中间插入一个分隔符,当然这个分隔符要在原串中没有出现过。一般可以用‘#’分隔。这样就非常巧妙的将奇数长度回文串与偶数长度回文串统一起来考虑了(见下面的一个例子,回文串长度全为奇数了),然后用一个辅助数组P记录以每个字符为中心的最长回文串的信息。P[id]记录的是以字符str[id]为中心的最长回文串,当以str[id]为第一个字符,这个最长回文串向右延伸了P[id]个字符。
原串: w aa bwsw f d
新串: # w # a # a # b # w # s # w # f # d #
辅助数组P: 1 2 1 2 3 2 1 2 1 2 1 4 1 2 1 2 1 2 1
这里有一个很好的性质,P[id]-1就是该回文子串在原串中的长度(包括‘#’)。如果这里不是特别清楚,可以自己拿出纸来画一画,自己体会体会。当然这里可能每个人写法不尽相同,不过我想大致思路应该是一样的吧。
好,我们继续。现在的关键问题就在于怎么在O(n)时间复杂度内求出P数组了。只要把这个P数组求出来,最长回文子串就可以直接扫一遍得出来了。
由于这个算法是线性从前往后扫的。那么当我们准备求P[i]的时候,i以前的P[j]我们是已经得到了的。我们用mx记在i之前的回文串中,延伸至最右端的位置。同时用id这个变量记下取得这个最优mx时的id值。(注:为了防止字符比较的时候越界,我在这个加了‘#’的字符串之前还加了另一个特殊字符‘$’,故我的新串下标是从1开始的)
好,到这里,我们可以先贴一份代码了。
这里,我介绍一下O(n)回文串处理的一种方法。Manacher算法.
O(n)回文子串算法
这里,我介绍一下O(n)回文串处理的一种方法。Manacher算法.原文地址:
http://zhuhongcheng.wordpress.com/2009/08/02/a-simple-linear-time-algorithm-for-finding-longest-palindrome-sub-string/
其实原文说得是比较清楚的,只是英文的,我这里写一份中文的吧。
首先:大家都知道什么叫回文串吧,这个算法要解决的就是一个字符串中最长的回文子串有多长。这个算法可以在O(n)的时间复杂度内既线性时间复杂度的情况下,求出以每个字符为中心的最长回文有多长,
这个算法有一个很巧妙的地方,它把奇数的回文串和偶数的回文串统一起来考虑了。这一点一直是在做回文串问题中时比较烦的地方。这个算法还有一个很好的地方就是充分利用了字符匹配的特殊性,避免了大量不必要的重复匹配。
算法大致过程是这样。先在每两个相邻字符中间插入一个分隔符,当然这个分隔符要在原串中没有出现过。一般可以用‘#’分隔。这样就非常巧妙的将奇数长度回文串与偶数长度回文串统一起来考虑了(见下面的一个例子,回文串长度全为奇数了),然后用一个辅助数组P记录以每个字符为中心的最长回文串的信息。P[id]记录的是以字符str[id]为中心的最长回文串,当以str[id]为第一个字符,这个最长回文串向右延伸了P[id]个字符。
原串: w aa bwsw f d
新串: # w # a # a # b # w # s # w # f # d #
辅助数组P: 1 2 1 2 3 2 1 2 1 2 1 4 1 2 1 2 1 2 1
这里有一个很好的性质,P[id]-1就是该回文子串在原串中的长度(包括‘#’)。如果这里不是特别清楚,可以自己拿出纸来画一画,自己体会体会。当然这里可能每个人写法不尽相同,不过我想大致思路应该是一样的吧。
好,我们继续。现在的关键问题就在于怎么在O(n)时间复杂度内求出P数组了。只要把这个P数组求出来,最长回文子串就可以直接扫一遍得出来了。
由于这个算法是线性从前往后扫的。那么当我们准备求P[i]的时候,i以前的P[j]我们是已经得到了的。我们用mx记在i之前的回文串中,延伸至最右端的位置。同时用id这个变量记下取得这个最优mx时的id值。(注:为了防止字符比较的时候越界,我在这个加了‘#’的字符串之前还加了另一个特殊字符‘$’,故我的新串下标是从1开始的)
好,到这里,我们可以先贴一份代码了。
- void pk()
- {
- int i;
- int mx = 0;
- int id;
- for(i=1; i<n; i++)
- {
- if( mx > i )
- p[i] = MIN( p[2*id-i], mx-i );
- else
- p[i] = 1;
- for(; str[i+p[i]] == str[i-p[i]]; p[i]++)
- ;
- if( p[i] + i > mx )
- {
- mx = p[i] + i;
- id = i;
- }
- }
- }
代码是不是很短啊,而且相当好写。很方便吧,还记得我上面说的这个算法避免了很多不必要的重复匹配吧。这是什么意思呢,其实这就是一句代码。
if
(
mx
>
i
)
p
[
i
]
=
MIN
(
p
[
2
*
id
-
i
],
mx
-
i
);
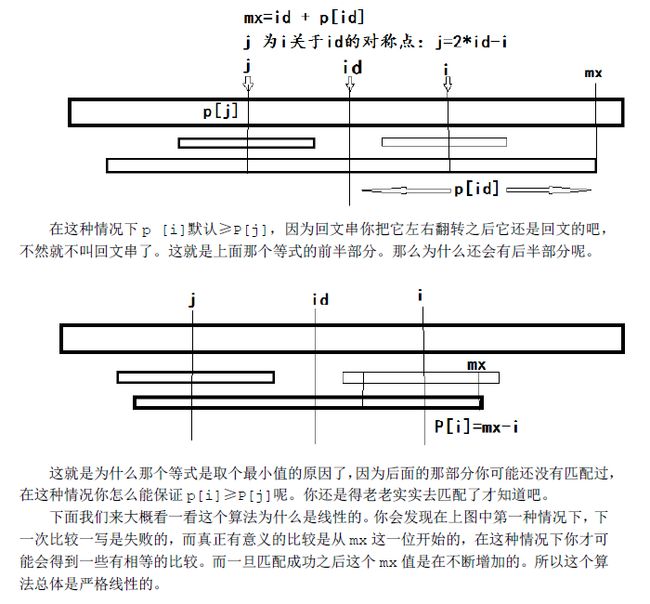
就是当前面比较的最远长度mx>i的时候,P[i]有一个最小值。这个算法的核心思想就在这里,为什么P数组满足这样一个性质呢?
(下面的部分为图片形式)
看完这个算法,你有可能会觉得这种算法在哪会用到呢?其实回文串后缀数组也可以做。只是复杂度是O(n log n)的,而且一般情况下也不会刻意去卡一个log n的算法。可正好hdu就有这么一题,你用后缀数组写怎么都得T(当然应该是我写得太烂了)。不信的话大家也可以去试试这题。
http://acm.hdu.edu.cn/showproblem.php?pid=3068O
(
n
)回文子串算法
原文地址:
http://zhuhongcheng.wordpress.com/2009/08/02/a-simple-linear-time-algorithm-for-finding-longest-palindrome-sub-string/
其实原文说得是比较清楚的,只是英文的,我这里写一份中文的吧。
首先:大家都知道什么叫回文串吧,这个算法要解决的就是一个字符串中最长的回文子串有多长。这个算法可以在O(n)的时间复杂度内既线性时间复杂度的情况下,求出以每个字符为中心的最长回文有多长,
这个算法有一个很巧妙的地方,它把奇数的回文串和偶数的回文串统一起来考虑了。这一点一直是在做回文串问题中时比较烦的地方。这个算法还有一个很好的地方就是充分利用了字符匹配的特殊性,避免了大量不必要的重复匹配。
算法大致过程是这样。先在每两个相邻字符中间插入一个分隔符,当然这个分隔符要在原串中没有出现过。一般可以用‘#’分隔。这样就非常巧妙的将奇数长度回文串与偶数长度回文串统一起来考虑了(见下面的一个例子,回文串长度全为奇数了),然后用一个辅助数组P记录以每个字符为中心的最长回文串的信息。P[id]记录的是以字符str[id]为中心的最长回文串,当以str[id]为第一个字符,这个最长回文串向右延伸了P[id]个字符。
原串: w aa bwsw f d
新串: # w # a # a # b # w # s # w # f # d #
辅助数组P: 1 2 1 2 3 2 1 2 1 2 1 4 1 2 1 2 1 2 1
这里有一个很好的性质,P[id]-1就是该回文子串在原串中的长度(包括‘#’)。如果这里不是特别清楚,可以自己拿出纸来画一画,自己体会体会。当然这里可能每个人写法不尽相同,不过我想大致思路应该是一样的吧。
好,我们继续。现在的关键问题就在于怎么在O(n)时间复杂度内求出P数组了。只要把这个P数组求出来,最长回文子串就可以直接扫一遍得出来了。
由于这个算法是线性从前往后扫的。那么当我们准备求P[i]的时候,i以前的P[j]我们是已经得到了的。我们用mx记在i之前的回文串中,延伸至最右端的位置。同时用id这个变量记下取得这个最优mx时的id值。(注:为了防止字符比较的时候越界,我在这个加了‘#’的字符串之前还加了另一个特殊字符‘$’,故我的新串下标是从1开始的)
好,到这里,我们可以先贴一份代码了。
- void pk()
- {
- int i;
- int mx = 0;
- int id;
- for(i=1; i<n; i++)
- {
- if( mx > i )
- p[i] = MIN( p[2*id-i], mx-i );
- else
- p[i] = 1;
- for(; str[i+p[i]] == str[i-p[i]]; p[i]++)
- ;
- if( p[i] + i > mx )
- {
- mx = p[i] + i;
- id = i;
- }
- }
- }
代码是不是很短啊,而且相当好写。很方便吧,还记得我上面说的这个算法避免了很多不必要的重复匹配吧。这是什么意思呢,其实这就是一句代码。
if
(
mx
>
i
)
p
[
i
]
=
MIN
(
p
[
2
*
id
-
i
],
mx
-
i
);
就是当前面比较的最远长度mx>i的时候,P[i]有一个最小值。这个算法的核心思想就在这里,为什么P数组满足这样一个性质呢?
(下面的部分为图片形式)
看完这个算法,你有可能会觉得这种算法在哪会用到呢?其实回文串后缀数组也可以做。只是复杂度是O(n log n)的,而且一般情况下也不会刻意去卡一个log n的算法。可正好hdu就有这么一题,你用后缀数组写怎么都得T(当然应该是我写得太烂了)。不信的话大家也可以去试试这题。
http://acm.hdu.edu.cn/showproblem.php?pid=3068
#include <map>
#include <set>
#include <list>
#include <queue>
#include <deque>
#include <stack>
#include <string>
#include <time.h>
#include <cstdio>
#include <math.h>
#include <iomanip>
#include <cstdlib>
#include <limits.h>
#include <string.h>
#include <iostream>
#include <fstream>
#include <algorithm>
using namespace std;
//HDU 3068
#define LL long long
#define MIN INT_MIN
#define MAX INT_MAX
#define PI acos(-1.0)
#define FRE freopen("input.txt","r",stdin)
#define FF freopen("output.txt","w",stdout)
#define N 210010
char str[N];
int p[N];
char s[N];
void pk (int n) {
int i,j;
int mx = 0;
int id;
for (i = 1; i < n; i++) {
if (mx > i) {
p[i] = min(p[2*id - i], mx - i);
} else p[i] = 1;
for (; str[i - p[i]] == str[i + p[i]]; p[i]++);
if (p[i] + i > mx) {
mx = p[i] + i;
id = i;
}
}
}
void gao(int n) {
int i,j;
int mx = 0;
for (i = 1; i < n; i++) {
if (p[i] > mx) {
mx = p[i];
}
}
printf("%d\n",mx-1);
}
int main () {
while (scanf("%s",s+1) != -1) {
int i,j;
int len = strlen(s+1);
str[0] = '@';
str[1] = '#';
for (i = 2, j = 1; j <= len ; j++) {
str[i++] = s[j];
str[i++] = '#';
}
str[i] = '\0';
//cout<<str<<endl;
pk(i);
gao(i);
}
return 0;
}
[cpp] view plaincopy
#include <map>
#include <set>
#include <list>
#include <queue>
#include <deque>
#include <stack>
#include <string>
#include <time.h>
#include <cstdio>
#include <math.h>
#include <iomanip>
#include <cstdlib>
#include <limits.h>
#include <string.h>
#include <iostream>
#include <fstream>
#include <algorithm>
using namespace std;
//POJ 3974
#define LL long long
#define MIN INT_MIN
#define MAX INT_MAX
#define PI acos(-1.0)
#define FRE freopen("input.txt","r",stdin)
#define FF freopen("output.txt","w",stdout)
#define N 2000020
char str[N];
int p[N];
char s[N/2];
void pk (int n) {
int i,j;
int mx = 0;
int id;
for (i = 1; i < n; i++) {
if (mx > i) {
p[i] = min(p[2*id - i], mx - i);
} else p[i] = 1;
for (; str[i - p[i]] == str[i + p[i]]; p[i]++);
if (p[i] + i > mx) {
mx = p[i] + i;
id = i;
}
}
}
void gao(int n) {
int i,j;
int mx = 0;
for (i = 1; i < n; i++) {
if (p[i] > mx) {
mx = p[i];
}
}
printf("%d\n",mx-1);
}
int main () {
int ca = 1;
while (scanf("%s",s+1)) {
if (strcmp(s+1,"END") == 0) break;
int i,j;
int len = strlen(s+1);
str[0] = '@';
str[1] = '#';
for (i = 2, j = 1; j <= len ; j++) {
str[i++] = s[j];
str[i++] = '#';
}
str[i] = '\0';
printf("Case %d: ",ca++);
pk(i);
gao(i);
}
return 0;
}
#include<cstdio>
#include<iostream>
#include<cstring>
#include<cmath>
#include<algorithm>
using namespace std;
const int LEN=2200050;
int p[LEN];
char str[LEN], dstr[LEN];
int getstring(int n)
{
int i, mx=0, size=0;
for(i=1; i<n; i++)
{
if( mx>i )
p[i]=min(p[2*size-i], mx-i);
else
p[i]=1;
for(; dstr[i+p[i]]==dstr[i-p[i]]; p[i]++);
if( i+p[i]>mx )
{
mx=p[i]+i;
size=i;
}
}
mx=-1;
for(i=1; i<n; i++)
{
if( mx<p[i] )
{
mx=p[i];
}
}
return mx;
}
int main()
{
int i, j, len, cases=1;
while( scanf("%s", str+1)!=EOF )
{
if( strcmp(str+1, "END")==0 )
break;
len=strlen(str+1);
dstr[0]='@';
dstr[1]='#';
for(i=2, j=1; j<=len; dstr[i++]=str[j++], dstr[i++]='#');
dstr[i]='\0';
int ans=getstring(i);
printf("Case %d: %d\n",cases++, ans-1);
}
return 0;
}