spark入门笔记(二)spark的stanalone模式
hadoop是企业中是运行在yarn模式上的,他也有自己的本地运行模式,也就是只有一个JVM进程。除了yarn之外,还提供了Mesos 集群资源管理。但是spark还提供了standalone模式,可以手动的在该模式集群下启动master和work节点,还可以仅仅在单节点的环境下运行这些进程,该模式又分为两种方式,cluster模式和client模式。spark-shell是不支持cluster模式的。具体的我们分析了两种模式的不同之处出后再分析。
在集群上安装standalone模式
首先,我们当然需要在各个节点上安装相同版本的spark环境,然后在根据节点的硬件环境去配置运行时需要的环境。注意任何的配置信息都是在程序中设定的最重要的,集群配置次之,shell环境下输入的最轻。
Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_IP, 绑定spark运行是master的ip地址# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, master运行在该IP环境下的端口号已经在web上浏览时的端口号# - SPARK_MASTER_OPTS, t设置和master相关的属性配置# - SPARK_WORKER_CORES, 每一个节点上我们运行多少个spark进程# - SPARK_WORKER_MEMORY,每个节点上运行的内存大小# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, 每个work运行的端口和web上的端口# - SPARK_WORKER_INSTANCES, 通常我们设置为1其他的我们可以保存成为默认的配置。还需要在salves下配置为每个节点的hostname名称或者IP地址
手动的启动集群
首先在环境变量中配置spark的安装目录,然后进入安装目录下运行
./sbin/start-master.sh当你一旦启动该命令,master就会打印出spark://HOST:PORT,对应的IP地址和对应的端口号,该信息可以用于启动work节点的命令,或者把当前的master传送给sparkContext的参数。当然,你也可以在spark运行的web界面上发现这些信息。
你可以在各个节点上运行命令连接这个master
一旦你启动了该命令,你可以从web界面上观看集群运行的信息,内存和节点个数等等。./sbin/start-slave.sh <master-spark-URL>下面的一些启动命令可以帮助你配置启动集群的相关参数
Argument Meaning -h HOST,--host HOST主机的名称 -i HOST,--ip HOST同上。但是过时啦 -p PORT,--port PORT每个主机运行对应的端口号,master默认是7077,worker对应的是随机分配的 --webui-port PORTweb端口。master默认8080.worker默认对应8081 -c CORES,--cores CORES这个配置信息是仅仅针对worker节点的。每个work对应的核数 -m MEM,--memory MEM该配置信息也是仅仅针对于worker的,是配置运行时的内存大小 -d DIR,--work-dir DIR也是仅仅针对于worker的。就是说worker对应的工作目录咋哪里,默认是安装目录/worker --properties-file FILE一些特定属性的配置。 standalone两种模式的说明
分为集群模式和客户端模式,简单你的来说,我们看一下下面的连个图片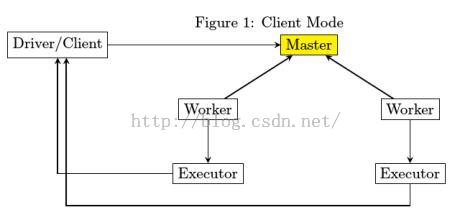 我们会发现图1的客户端模式是有一个单独的节点抽出来来向master启动命令,进而才会启动两个worker上的executor进程,也就是说当集群启动之后,如果客户端进程崩溃是不会影响各个exexutor进程的。然而在图2.我们会发现,刚开始的时候先从属节点上随机的找一个节点充当driver来启动整个集群,这点和客户端模式是不同的。这就解释了为什么spark—shell没有集群模式,因为他是一个仅仅会在一个节点上运行的进程,根本没有那些所谓的从属节点。
我们会发现图1的客户端模式是有一个单独的节点抽出来来向master启动命令,进而才会启动两个worker上的executor进程,也就是说当集群启动之后,如果客户端进程崩溃是不会影响各个exexutor进程的。然而在图2.我们会发现,刚开始的时候先从属节点上随机的找一个节点充当driver来启动整个集群,这点和客户端模式是不同的。这就解释了为什么spark—shell没有集群模式,因为他是一个仅仅会在一个节点上运行的进程,根本没有那些所谓的从属节点。