spark源码学习(九):map端计算结果缓存处理(一)
spark源码学习(九):map端计算结果缓存处理(一)
在前面我们谈到了在map任务结束之后,map任务会对结果进行三种方式的处理,这里来看看具体的代码,就是进入ExternalSorter的insertAll方法去看看。这里的代码主要分为三个部分,三个if代码块儿分别对应着在map端执行局合,直接写入partition的存储块儿,简单的对计算结果进行缓存。代码如下所示:
def insertAll(records: Iterator[_ <: Product2[K, V]]): Unit = {
val shouldCombine = aggregator.isDefined
if (shouldCombine) {
// 使用 AppendOnlyMap在内存中执行聚合
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
//使用到的key-value对
var kv: Product2[K, V] = null
//定义一个偏函数update,最重要的函数
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
//这里主要用于从records中读取数据
addElementsRead()
kv = records.next()
//数据格式((partitionIndex,key),update(boolean,oldValue)
map.changeValue((getPartition(kv._1), kv._1), update)
//如果内存使用过大,就会把数据写入磁盘,同时新建SizeTrackingAppendMapOnly
maybeSpillCollection(usingMap = true)
}
}
else if (bypassMergeSort) {
//直接把结果写到partition文件中去
if (records.hasNext) {
spillToPartitionFiles(
WritablePartitionedIterator.fromIterator(records.map { kv =>
((getPartition(kv._1), kv._1), kv._2.asInstanceOf[C])
})
)
}
}
else {
//对map端的结果数据进行简单的缓存
while (records.hasNext)
{
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
}
发现在代码的刚刚开始的地方出现;aggregator.get.***,这是什么东西,进入源码看看如下
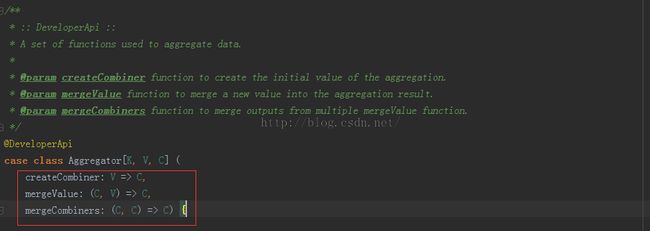
这里会发现,其实他的三个构造参数都是三个函数,主要是用来对key,value数据块儿进行操作的,具体的不解释,上面的注释写的很清楚。如果进一步去看的话,你会发现这个class会出现在shuffleRDD中,会有一个setAggregator的方法,很明朗,我们这里在定义Aggregator的时候使用的是case class,会自动的提供set,get方法。要是继续的深入去看,我们就应该去看看PairRDDFunctions中的combinByKey函数啦,这个方法会显示出函数式编程的巨大威力。在这里不进行讨论combinebykey,点击这里去看看其他大神的介绍。
上面的代码中的第一个代码块儿已经介绍过了,就是把数据在map端就直接进行合并排序,这样可以大幅度减少reduce的压力,那么接下来就继续看看第二代码块儿的内容--不适用map端的缓存,也不执行聚合和排序,而是直接把数据spill到各自对应的partition中去,让reduce来处理。如图所示:

从图上可以看到,我们就是把数据写到写到临时的block文件内,block的数量等于partition的数量,然后把这些block在统一写入磁盘,让recude去磁盘上读取数据去吧。这里最核心的代码当然就是SpillToPartitionFiles啦,主要用于溢出分区文件,就是把数据从缓存写到磁盘上。代码如下
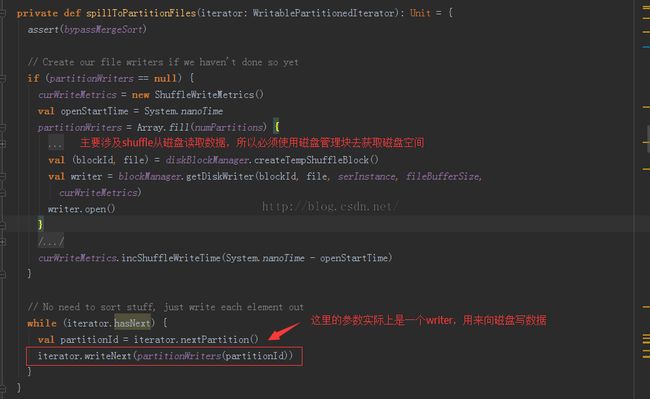
进入上面代码的最后一句,看看这个迭代器是干什么的:
回到最上面的代码块儿,我们在来看看那个fromIterato的用法和具体的参数:
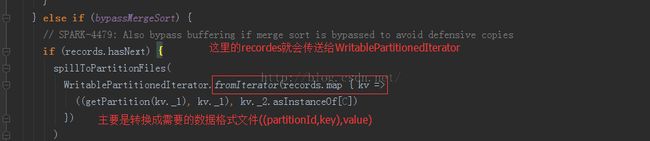
你会发现,这里的recordes也是一个iterator,只不过加上了视图界定而已。
还要注意这句话:writer.write(cur._1._2, cur._2)写如的数据格式,在代码fromiterator中的数据格式是Iterator[((Int, _), _)这样的,但是在写write方法的时候却直接忽略了partitionIndex,直接key,value写入磁盘,没有理会分区索引,所以,最终的结果如下图所示:
哈哈,不再有分区partition了吧。这种情况会把bucket合并到同一个文件,节约了磁盘I/O,最终才能提升性能,到这里,刚开始的那块儿代码的第二个判断宽块儿就介绍完了。第三个下片继续。