spark源码学习(七);task任务的提交分析
spark入门学(七)task任务的提交分析
spark虽然在计算速度上比hadoop要强势很多,但是这两个框架在底层的数据流都要经过shuffle。由此,shuffle把spark的job分成两个阶段,一个叫做shuffleMaptask,另外一个是resultTask。前者主要是把运算所得的数据结果写到指定的位置,后者是从对应的位置读取数据然后再把运行的结果提交给客户端,为了详细,我们看看官方的源码介绍。
shufflemaptask
A ShuffleMapTask divides the elements of an RDD into multiple buckets (based on a partitioner * specified in the ShuffleDependency
resulttask
A task that sends back the output to the driver application.
那么问题是,这些任务到底是怎样提交的呢?我们知道task的最终运行时在executor中运行的。再standalone模式下,executor和driver的通信只要是依靠CoarseGrained-ExecutorBackend来维护的,他继承于ExecutorBackend这个特质,ExecutorBackend这个类的说明如下,也就是driver和executor交互的接口,executor在接受任务和执行完任务都要进行状态的更新,就是实现了statusUpdate这个方法。
A pluggable interface used by the Executor to send updates to the cluster scheduler.
在CoarseGrained-ExecutorBackend的onstart方法实现如下;我们会看到和driver互动的信息。
override def onStart() {
logInfo("Connecting to driver: " + driverUrl)
......
ref.ask[RegisteredExecutor.type](//向driver发送注册命令
RegisterExecutor(executorId, self, hostPort, cores, extractLogUrls))
}(ThreadUtils.sameThread).onComplete {
case Success(msg) =>
case Failure(e) =>
另外还要注意onstart方法中的信息,new executor和launchtask函数
override def receive: PartialFunction[Any, Unit] = {
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
val (hostname, _) = Utils.parseHostPort(hostPort)
//最关键的代码信息,只有在driver回复注册信息成功之后,才会开始创建executor
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
// 从driver收到的回复信息
case RegisterExecutorFailed(message) =>
case LaunchTask(data) =>
case KillTask(taskId, _, interruptThread) =>
<span style="white-space:pre"> </span>executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
case StopExecutor =>
} 我们进入launchtask函数,他是属于task的函数进入task。launchtask函数看看;其中创造一个taskrunner类。我们可以认为taskrunner是在executor中负责任务的运行的。之后把tr放到runningtask集合中,继而在线程池中运行任务
那就进去taskrunner去看看吧,他也是executor的一个内部类嘛。taskrunner是一个进程类,实现了runnable接口,这个时候当然要去看看它里面的run函数啦,对吧。

下面进入run函数,有些地方进行的缩减
override def run(): Unit = {
logInfo(s"Running $taskName (TID $taskId)")//开始运行task
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)//状态的更新为running
updateDependencies(taskFiles, taskJars)//下载任务所需的文件和jar包
try {
...各种反序列化
logDebug("Task " + taskId + "'s epoch is " + task.epoch)
env.mapOutputTracker.updateEpoch(task.epoch)//主要是更新次数和清除由于失败map任务产生的mapstatus
//最核心的地方,看看,task.run终于为运行任务啦
val value = try {
task.run(taskAttemptId = taskId, attemptNumber = attemptNumber)
}
进入这里的task.run方法,就会进入task.scala类中,哈哈,看看这里的run方法,最重要的就是其中runtask函数,runtask函数是一个被子类实现的函数,例如在shufflemaptask和resulttask中都有自己的实现。前者是先把数据划分到不同的bucket种,然后是写数据到指定的文件中去。后者读特定文件取数据之后把执行的结果提交给driver端。具体的如下图所示,分别是两种任务的runtask函数;

仔细的话,你会看到rdd.iterator这两个迭代器,他是什么呢?iterator主要就是在对rdd的每个partition上没别执行任务,一个partition对应一个task嘛。具体的就来看看源码;

细心的话,你会看到有两个特别特别重要的方法,getorcompute函数和computeorreadcheckpoint函数。第一个函数getorcompute就是在没有定义存级别的时候我们去重新计算,定义的话就直接get啦。computeorreadcheckpoint就是再有checkpoint的时候直接读取,否则执行compute函数。具体如下;
getorcompute函数在get的时候,从远程和本地得到blockid,然后再判断是否得到了 blockResult还是non。没有得到partition的话就去用上面的那个函数进行运算。
上面的这些也就仅仅谈到了task提交的大致运行过程,其中我们也就是了解基本的框架,要是层层递归,的确有些麻烦。说了这么多,来看看一副图片吧,就可以包含上面的一切:
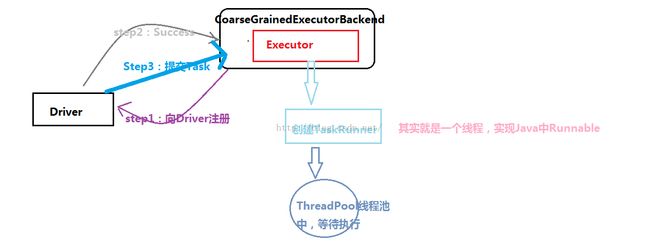
上面还有和shuffle数据的写入和读取等一些细节的分析,下次再具体分析。