caffe学习入门:pycaffe的使用
caffe学习入门:pycaffe的使用
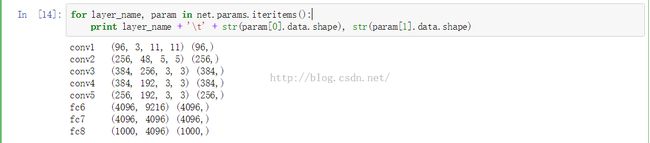
caffe的官方完美的支持python语言的兼容,提供了pycaffe的接口。用起来很方便,首先来看一下最常用到的:caffe的一个程序跑完之后会在snapshot所指定的目录下产生一个后缀名为caffemodel的文件,这里存放的就是我们在训练网络的时候得到的每层的参数信息,具体访问由net.params['layerName'][0].data访问权重参数(num_filter,channel,weight,high),net.params['layerName'][1].data访问biase,格式是(biase,)。如下图所示:这里的net.params使用的是字典格式
当然还有保存网络结构的字典类型net.blobs['layerName'].data。这里最常用的也就是net.blobs['data']相关的使用,例如得到输入图片的大小net.blobs['data'].data.shape。改变输入图片的大小net.blobs['data'].reshape(0,3,227,227),把图片fed into网络。net.blob['data'].data[...]=inputImage,注意,这里最后一个data是一个数组,要是只有一张图片就这样net.blob['data'].data[0]=inputImage。如下图所示:
下面用python实现一个使用自己的图片的例子:
import numpy as np
import sys,os
# 设置当前的工作环境在caffe下
caffe_root = '/home/xxx/caffe/'
# 我们也把caffe/python也添加到当前环境
sys.path.insert(0, caffe_root + 'python')
import caffe
os.chdir(caffe_root)#更换工作目录
# 设置网络结构
net_file=caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt'
# 添加训练之后的参数
caffe_model=caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
# 均值文件
mean_file=caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy'
# 这里对任何一个程序都是通用的,就是处理图片
# 把上面添加的两个变量都作为参数构造一个Net
net = caffe.Net(net_file,caffe_model,caffe.TEST)
# 得到data的形状,这里的图片是默认matplotlib底层加载的
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
# matplotlib加载的image是像素[0-1],图片的数据格式[weight,high,channels],RGB
# caffe加载的图片需要的是[0-255]像素,数据格式[channels,weight,high],BGR,那么就需要转换
# channel 放到前面
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
# 图片像素放大到[0-255]
transformer.set_raw_scale('data', 255)
# RGB-->BGR 转换
transformer.set_channel_swap('data', (2,1,0))
# 这里才是加载图片
im=caffe.io.load_image(caffe_root+'examples/images/cat.jpg')
# 用上面的transformer.preprocess来处理刚刚加载图片
net.blobs['data'].data[...] = transformer.preprocess('data',im)
#注意,网络开始向前传播啦
out = net.forward()
# 最终的结果: 当前这个图片的属于哪个物体的概率(列表表示)
output_prob = output['prob'][0]
# 找出最大的那个概率
print 'predicted class is:', output_prob.argmax()
# 也可以找出前五名的概率
top_inds = output_prob.argsort()[::-1][:5]
print 'probabilities and labels:'
zip(output_prob[top_inds], labels[top_inds])
# 最后加载数据集进行验证
imagenet_labels_filename = caffe_root + 'data/ilsvrc12/synset_words.txt'
labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t')
top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
for i in np.arange(top_k.size):
print top_k[i], labels[top_k[i]]