连通图的割点、割边(桥)、块、缩点,有向图的强连通分量
连通图的割点、割边(桥)、块、缩点,有向图的强连通分量
【本文摘选自百度文库】
一、基本概念
无向图
割点:删掉它之后(删掉所有跟它相连的边),图必然会分裂成两个或两个以上的子图。
块:没有割点的连通子图
割边:删掉一条边后,图必然会分裂成两个或两个以上的子图,又称桥。
缩点:把没有割边的连通子图缩为一个点,此时满足任意两点间都有两条路径相互可达。
求块跟求缩点非常相似,很容易搞混,但本质上完全不同。割点可以存在多个块中(假如存在k个块中),最终该点与其他点形成k个块,对无割边的连通子图进行缩点后(假设为k个),新图便变为一棵k个点由k-1条割边连接成的树,倘若其中有一条边不是割边,则它必可与其他割边形成一个环,而能继续进行缩点。
有割点的图不一定有割边,如:
3是割点,分别与(1,2)和(4,5)形成两个无割点的块
有割边的图也不定有割点,如:
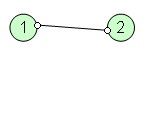
w(1,2)为割边,
有向图
强连通分量:有向图中任意两点相互可达的连通子图,其实也相当于无向图中的缩点
二、算法
无向图
借助两个辅助数组dfn[],low[]进行DFS便可找到无向图的割点和割边,用一个栈st[]维护记录块和“缩点”后连通子图中所有的点。
dfn[i]表示DFS过程中到达点i的时间,low[i]表示能通过其他边回到其祖先的最早时间。low[i]=min(low[i],dfn[son[i]])
设 v,u之间有边w(v,u),从v->u:
如果low[u]>=dfn[v],说明v的儿子u不能通过其他边到达v的祖先,此时如果拿掉v,则必定把v的祖先和v的儿子u,及它的子孙分开,于是v便是一个割点,v和它的子孙形成一个块。
如果low[u]>dfn[v]时,则说明u不仅不能到达v的祖先,连v也不能通过另外一条边直接到达,从而它们之间的边w(v,u)便是割边,求割边的时候有一个重边的问题要视情况处理,如果v,u之间有两条无向边,需要仍视为割边的话,则在DFS的时候加一个变量记录它的父亲,下一步遇到父结点时不扩展回去,从而第二条无向重边不会被遍历而导致low[u]==dfn[v] ,而在另外一些问题中,比如电线连接两台设备A,B 如果它们之间有两根电线,则应该视为是双连通的,因为任何一条电线出问题都不会破坏A和B之间的连通性,这个时候,我们可以用一个used[]数组标记边的id,DFS时会把一条无向边拆成两条有向边进行遍历,但我们给它们俩同一个id号,在开始遍历v->u前检查它的id是否在上一次u->v时被标记,这样如果两点之间有多条边时,每次遍历都只标记其中一条,还可以通过其他边回去,形成第二条新的路
求割点的时候,维护一个栈st 每遍历到一个顶点v则把它放进去,对它的子孙u如果dfn[u]为0,则表示还没有遍历到则先DFS(u),之后再判断low[u]和dfn[v],如果low[u]>=dfn[v],则把栈中从栈顶到v这一系列元素弹出,这些点与v形成一个块,如果u的子孙x也是一个割点,这样做会不会错把它们和v,u放在一起形成一个块呢,这种情况是不会发生的,如果发现x是一个割点,则DFS到x那一步后栈早就把属于x的子孙弹出来了,而只剩下v,u的子孙,它们之间不存在割点,否则在回溯到v之前也早就提前出栈了!画一个图照着代码模拟一下可以方便理解。
求割边也是一样的。
有向图
有向图强连通分量的算法有两个,一个是Kosaraju,另一个是Tarjan,前者需要两次DFS,代码量偏大但容易理解,后者只需要一次DFS和维护一个栈便可以,实现简单
强连通分量 Kosaraju PK Tarjan
| Kosaraju算法 对每个不在树中的点开始DFS一次,并记录离开各点的时间,这里是离开的时间,而不是到达时的,比如有图1->2 2->3 则1,2,3分别对应的时间是3 2 1,因为3没有出边,所以最先离开,其次是2,最后是1, DFS后,在同一棵树中的点,如果dfn[v]>dfn[u]则说明点从v有可能到达u,而这棵树中的dfn[]最大的点,肯定可以到达每个点,从而在原图的逆图中,每次都选没有访问过的最大的dfn值开始DFS,如果可达点x 则说明它们是强连通的 void DFS_T(int u)
{
int i,v;
if(used[u])return ;
used[u]=1;id[u]=scc;
for(i=q[u];i!=-1;i=Tedge[i].pre)
{
v=Tedge[i].d;
if(!used[v])DFS_T(v);
}
}
void DFS(int v){
int i,u;
if(used[v])return ;
used[v]=1;
for(i=p[v];i!=-1;i=edge[i].pre)
{
u=edge[i].d;
if(!used[u])DFS(u);
}
order[++num]=v;
}
int Kosaraju()
{
int i,j,k,v,u;
memset(used,0,sizeof(used));num=0;
for(i=1;i<=n;++i)if(!used[i])DFS(i);
memset(used,0,sizeof(used));
memset(id,0,sizeof(id));scc=0;
for(i=num;i>=1;--i)if(!used[order[i]])scc++,DFS_T(order[i]);
}Tarjan算法 dfn[v]记录到达点v的时间,跟上面的离开不同,low[v]表示通过它的子结点可以到达的所有点中时间最小值,即low[i]=min(low[i],low[u]),u为v的了孙,初始化时low[v]=dfn[u]。如果low[v]比dfn[v]小,说明v可以通过它的子结点u,u1,u2...到达它的祖先v',则存在环,这个环上所有的点组成的子图便是一个强连通分量。换一个角度看,如果当low[v]==dfn[v]时,则它的子树中所有low[u]==dfn[v]的点都与v构成一个环,维护一个栈,DFS过程中,每遍历一个点则把它放入栈中,当发现low[v]==dfn[v]则依次把栈里的元素都弹出来,当栈顶元素为v时结束,这些点便构成一个以v为树根的强连通分量。 仍以上图为例,首先遍历点1,并dfn[1]=low[1]=++num, num表示按先后访问时间编号 ,同时1入栈 a.从3深入 dfn[3]=low[3]=2; 3入栈 b.从3到5 dfn[5]=low[5]=3; 5入栈 c.从5到6 dfn[6]=low[6]=4; 6入栈 d.发现6没有子结点可走,这时判断dfn[6]==low[6],于是开始弹栈,当遇到6时则break,即共弹出一个元素,于是6便是一个强连通分量 e.回溯至5,同样判断和弹栈,发现5也是一个强连通分量 f.再回溯至3,发现有边3->4,dfn[4]=low[4]=5,4入栈 g.4有边到1,由于1已经在栈里面,所以用dfn[1]更新low[4] 即low[4]=min(low[4],dfn[1])=1 h.回溯更新4的父亲3的low值 low[3]=min(low[3],low[4])=1 i.再回溯至1,发现有边1->2 继续深度遍历,2入栈,发现它的子结点4已经在栈中,直接更新low[2]=min(low[2],dfn[4]); j.回溯至1,从而1所有出发的边都走了一遍,这时再比较low[1]与dfn[1],发现相等,于是开始弹栈,找到2,4,3,1这四个元素,构成一个连通分量。 void Tarjan(int v){
dfn[v]=low[v]=++num;
used[v]=1;
st[++numSt]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(!dfn[u])//还没有标号的点
{
Tarjan(u);//先遍历它的子结点
GetMin(low[v],low[u]);//用子结点更新当前点的low值
}
else if(used[u]&&GetMin(low[v],dfn[u]));
}
if(dfn[v]==low[v]){
scc++;
while(1){
int u(st[numSt--]);
id[u]=scc;
used[u]=0;
if(v==u)break;
}
}
}
int main(){
for(int i=1;i<=n;++i)if(!dfn[i])Tarjan(i);
} 这里有一个疑问,为什么当发现一个点v的子结点u已经在栈中时用dfn[u]来更新low[v],而不是用low[u],感觉好象两个都可以用,因为只要保证low[v]尽可能变小就行了, |
三、代码实现
割点和块
求割点的时候由于不知道最开始选的树根是不是只有一个儿子,这样在DFS过来中不会满足low[u]>=dfn[v]而判为割点,但有两个或两个以上儿子的根肯定也是一个割点,所以要特判!
void CutBlock(int v){
dfn[v]=low[v]=++cnt;
st[++top]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(dfn[u]==0){
CutBlock(u);
GetMin(low[v],low[u]);
if(low[u]>=dfn[v]){ //V是一个割点
block[0]=0;
while (true) {
block[++block[0]]=st[top];
if (st[top--] == u) //只能弹到u为止,v还可以在其他块中
break;
}
block[++block[0]]=v;//割点属于多个块,一定要补进去
Count(block);
}
}
else GetMin(low[v],dfn[u]);
}
}
割边和缩点
<span style="font-family: Arial, Helvetica, sans-serif;">void CutEdge(int v,int fa){</span>
dfn[v]=low[v]=++cnt;
st[++top]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(u==fa)continue;
if(!dfn[u]){
CutEdge(u,v);
GetMin(low[v],low[u]);
if(low[u]>dfn[v]){//边v->u为一条割边
cutE[++numE]=E(v,u);
// 将u及与它形成的连通分量的所有点存起来
++numB;
while(1){
id[st[top]]=numB;
if(st[top--]==u)break;
}
}
}
else GetMin(low[v],dfn[u]);
}
}
有向图强连通分量
void Tarjan(int v){
dfn[v]=low[v]=++num;
used[v]=1;
st[++numSt]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(!dfn[u])//还没有标号的点
{
Tarjan(u);//先遍历它的子结点
GetMin(low[v],low[u]);//用子结点更新当前点的low值
}
else if(used[u]&&GetMin(low[v],dfn[u]));
}
if(dfn[v]==low[v]){
scc++;
while(1){
int u(st[numSt--]);
id[u]=scc;
used[u]=0;
if(v==u)break;
}
}
}
这里需要注意一个地方,上面标记为紫色的那行代码,相比上面两个代码,这里加了一个used[]判断点是否在栈中,为什么前面的不要,而这里需要呢,举个例子
根据dfn可以看出搜索的顺序是1->2->5->6形成一个强连通分量(2,5,6),于是开始退栈,回溯到1从3出发到达4,此时如果直接用dfn[2]更新low[4]的话,会得到low[4]=2,变小后而与dfn[4]不再相等,不能退栈,这与最后的4形成一个单独强连通分量是不符合的,所以,不在栈中的点,不能用来更新当前点的low[]值,为什么无向图不用标记呢,那时因为,边是无向的,有边从4->2同时也必有边2->4由于2之前被标记过,而遍历到当前结点4又不是通过w(2,4)这条边过来的,则必还存在另一条路径可以使2和4是相通的,(即图中的4-3-1-2),从而2,4是双连通的。
其实以上三个算法都源于Tarjan,只是根据dfn[]和low[]判断条件不同而得到不同的结果,无限Orz Trajan !!!
于是,顺便总结一下LCA的离线算法
离线是指把所有的问题都存起来,类似邻接表的形式,能根据点v找到它关的点u,处理完后一次性回答所有的答案。
DFS到v时,用used[]标记为已访问,下面分两部分完成
1、在Q个查询中对所有与v相关连的ui,uj,uk,如果检查发现used[]为真,则说明它们的最近公共祖先为ui当前能往上最大程度找到的祖先,这个可借助并查集实现,记录结果用以后面输出。
2、对v所有子结点u(不同于上面的u),进行DFS() ,DFS结束后,设置u的父亲为v,即fa[u]=v;
时间复杂度为O(m+Q ),Q为查询的总数,dist[]记录根到当前点的距离,如果最后要求任意两点v和u之间的距离,则为dist[v]+dist[u]-2*dist[lca(v,u)]
void LcaTarjan(int v){
used[v]=1;
fa[v]=v;
for(int i=q[v];i!=-1;i=e[i].pre){ //对跟v相关每个问题,尝试进行回答
int u(e[i].d),id(e[i].id);
if(used[u])ans[id]=Find(u);
}
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d),w(edge[i].w);
if(!used[u]){
dist[u]=dist[v]+w;
LcaTarjan(u);
fa[u]=v;
}
}
}
四、例题
pku1523>>
先求割点,第二问其实就是求块,一个割点存在k个块中,删掉后,便形成k个子图
pku2942>>
求块后,对每块有:如果存在奇圈,则可以分开开会,否则全T掉,判断奇圈可以用DFS二分染色的方法,当前点染为白色,它所有相邻点染为黑色,如果最后发现某条边两个端点同色,则存在奇圈。
pku3694>>
求割边后,并标记,这时新图形成一棵树,但并不需要缩点,否则反而不好处理,每加一条边w(v,u)进去,必会形成一个圈,剩下的问题但是如何找圈,事先求出v,u的最小公共祖先,加入边w(v,u)后,则这个圈的一部分便是从v到lca(v,u)之间的树边,另一部分是u到lca(v,u)之间的树边,由于一个图中割边的总条数不会超过n,所以可用割边关联的两个顶点中的一个来记录它的位置,这样在沿v或u向lca(v,u)往上找时,快速判断它与它父亲之间相连的边是否为割边,是的话ans-- 并标记为非,因为w(v,u)的加入形成了环,环中原来所有的割边都会变成非割边。用fa[v]表示v的父亲,set[v]表示v的祖先,虽然初始都表示v的父亲,但在LCA时要区分使用,一个只记录它的直接父亲,另一个并查集时压缩路径会改变。
pku 3352>> pku3177>>
求割边,缩点后,形成一棵树,统计度为1的点个数t,需要连的边数则为(t+1)/2 ,pku3177只是多了重边处理,方法见上。
hdu3394>> 求块,如果一个块的顶点数等于边数,则这个块只有一个环,如果边数大于点数,则必有多个环,容易知道在一个K环的块中,每条边也必属于K个环,这样可以计算出在一个环和多个环里的边总数,剩下的便是不在环中的边。
hdu 3394 Railway 无向图求块
2010-06-02 22:07
| hdu 3394 >> 求在0个环、1个环、多个环里的边的条数 问题转化为无向图求块,即缩块。块是不存在割点的连通子图,如果一个块的顶点数等于边数,则这个块只有一个环,如果边数大于点数,则必有多个环,容易知道在一个K环的块中,每条边也必属于K个环,这样可以计算出在一个环和多个环里的边总数,剩下的便是不在环中的边。 #define arr 10010
#define brr 500010
struct Edge{
int d,pre;
Edge(){}
Edge(int d1,int pre1):d(d1),pre(pre1){}
}edge[brr];
int p[arr];
int pn;
int dfn[arr];
int low[arr];
bool used[arr];
int cnt;
int block[arr];
int n,m;
int none,one,two;
int st[arr];
int top;
int fa[arr];
void Insert(int v,int u){
edge[++pn]=Edge(u,p[v]);p[v]=pn;
edge[++pn]=Edge(v,p[u]);p[u]=pn;
}
void Count(int* block){
FF(i,block[0])used[block[i]]=1;
int sum(0);
FF(i,block[0]){
int v(block[i]);
for(int j=p[v];j!=-1;j=edge[j].pre){
int u(edge[j].d);
if(used[u])sum++;
}
}
sum/=2;
if(sum==block[0])//点和边总数一样多,刚好一个环
one+=sum;
else if(sum>block[0])//边比点多,存在多个环
two+=sum;
else none+=sum;
FF(i,block[0])used[block[i]]=0;
}
void DFS(int v){
dfn[v]=low[v]=++cnt;
st[top++]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(dfn[u]==0){
fa[u]=v;
DFS(u);
GetMin(low[v],low[u]);
if(low[u]>=dfn[v]){
block[0]=0;
while (true) {
block[++block[0]]=st[top-1];
if (st[--top] == u)
break;
}
block[++block[0]]=v;
Count(block);
}
}
else if(u!=fa[v]) GetMin(low[v],dfn[u]);
}
}
void Work(){
clr(dfn,0);clr(low,0);
clr(used,0);
cnt=none=one=two=top=0;
FF(i,n){
if(dfn[i]==0)DFS(i);
}
printf("%d %d\n",none,two);
}
int main(){
while(scanf("%d%d",&n,&m)!=EOF){
if(n+m==0)break;
clr(p,-1);pn=0;
FF(i,m){
int v,u;
scanf("%d%d",&v,&u);
v+=1;u+=1;
Insert(v,u);
}
Work();
}
return 0;
} |
二、算法
无向图
借助两个辅助数组dfn[],low[]进行DFS便可找到无向图的割点和割边,用一个栈st[]维护记录块和“缩点”后连通子图中所有的点。
dfn[i]表示DFS过程中到达点i的时间,low[i]表示能通过其他边回到其祖先的最早时间。low[i]=min(low[i],dfn[son[i]])
设 v,u之间有边w(v,u),从v->u:
如果low[u]>=dfn[v],说明v的儿子u不能通过其他边到达v的祖先,此时如果拿掉v,则必定把v的祖先和v的儿子u,及它的子孙分开,于是v便是一个割点,v和它的子孙形成一个块。
如果low[u]>dfn[v]时,则说明u不仅不能到达v的祖先,连v也不能通过另外一条边直接到达,从而它们之间的边w(v,u)便是割边,求割边的时候有一个重边的问题要视情况处理,如果v,u之间有两条无向边,需要仍视为割边的话,则在DFS的时候加一个变量记录它的父亲,下一步遇到父结点时不扩展回去,从而第二条无向重边不会被遍历而导致low[u]==dfn[v] ,而在另外一些问题中,比如电线连接两台设备A,B 如果它们之间有两根电线,则应该视为是双连通的,因为任何一条电线出问题都不会破坏A和B之间的连通性,这个时候,我们可以用一个used[]数组标记边的id,DFS时会把一条无向边拆成两条有向边进行遍历,但我们给它们俩同一个id号,在开始遍历v->u前检查它的id是否在上一次u->v时被标记,这样如果两点之间有多条边时,每次遍历都只标记其中一条,还可以通过其他边回去,形成第二条新的路
求割点的时候,维护一个栈st 每遍历到一个顶点v则把它放进去,对它的子孙u如果dfn[u]为0,则表示还没有遍历到则先DFS(u),之后再判断low[u]和dfn[v],如果low[u]>=dfn[v],则把栈中从栈顶到v这一系列元素弹出,这些点与v形成一个块,如果u的子孙x也是一个割点,这样做会不会错把它们和v,u放在一起形成一个块呢,这种情况是不会发生的,如果发现x是一个割点,则DFS到x那一步后栈早就把属于x的子孙弹出来了,而只剩下v,u的子孙,它们之间不存在割点,否则在回溯到v之前也早就提前出栈了!画一个图照着代码模拟一下可以方便理解。
求割边也是一样的。
有向图
有向图强连通分量的算法有两个,一个是Kosaraju,另一个是Tarjan,前者需要两次DFS,代码量偏大但容易理解,后者只需要一次DFS和维护一个栈便可以,实现简单
强连通分量 Kosaraju PK Tarjan
2010-04-22 16:23
| Kosaraju算法 对每个不在树中的点开始DFS一次,并记录离开各点的时间,这里是离开的时间,而不是到达时的,比如有图1->2 2->3 则1,2,3分别对应的时间是3 2 1,因为3没有出边,所以最先离开,其次是2,最后是1, DFS后,在同一棵树中的点,如果dfn[v]>dfn[u]则说明点从v有可能到达u,而这棵树中的dfn[]最大的点,肯定可以到达每个点,从而在原图的逆图中,每次都选没有访问过的最大的dfn值开始DFS,如果可达点x 则说明它们是强连通的 void DFS_T(int u)
{
int i,v;
if(used[u])return ;
used[u]=1;id[u]=scc;
for(i=q[u];i!=-1;i=Tedge[i].pre)
{
v=Tedge[i].d;
if(!used[v])DFS_T(v);
}
}
void DFS(int v){
int i,u;
if(used[v])return ;
used[v]=1;
for(i=p[v];i!=-1;i=edge[i].pre)
{
u=edge[i].d;
if(!used[u])DFS(u);
}
order[++num]=v;
}
int Kosaraju()
{
int i,j,k,v,u;
memset(used,0,sizeof(used));num=0;
for(i=1;i<=n;++i)if(!used[i])DFS(i);
memset(used,0,sizeof(used));
memset(id,0,sizeof(id));scc=0;
for(i=num;i>=1;--i)if(!used[order[i]])scc++,DFS_T(order[i]);
}Tarjan算法 dfn[v]记录到达点v的时间,跟上面的离开不同,low[v]表示通过它的子结点可以到达的所有点中时间最小值,即low[i]=min(low[i],low[u]),u为v的了孙,初始化时low[v]=dfn[u]。如果low[v]比dfn[v]小,说明v可以通过它的子结点u,u1,u2...到达它的祖先v',则存在环,这个环上所有的点组成的子图便是一个强连通分量。换一个角度看,如果当low[v]==dfn[v]时,则它的子树中所有low[u]==dfn[v]的点都与v构成一个环,维护一个栈,DFS过程中,每遍历一个点则把它放入栈中,当发现low[v]==dfn[v]则依次把栈里的元素都弹出来,当栈顶元素为v时结束,这些点便构成一个以v为树根的强连通分量。 仍以上图为例,首先遍历点1,并dfn[1]=low[1]=++num, num表示按先后访问时间编号 ,同时1入栈 a.从3深入 dfn[3]=low[3]=2; 3入栈 b.从3到5 dfn[5]=low[5]=3; 5入栈 c.从5到6 dfn[6]=low[6]=4; 6入栈 d.发现6没有子结点可走,这时判断dfn[6]==low[6],于是开始弹栈,当遇到6时则break,即共弹出一个元素,于是6便是一个强连通分量 e.回溯至5,同样判断和弹栈,发现5也是一个强连通分量 f.再回溯至3,发现有边3->4,dfn[4]=low[4]=5,4入栈 g.4有边到1,由于1已经在栈里面,所以用dfn[1]更新low[4] 即low[4]=min(low[4],dfn[1])=1 h.回溯更新4的父亲3的low值 low[3]=min(low[3],low[4])=1 i.再回溯至1,发现有边1->2 继续深度遍历,2入栈,发现它的子结点4已经在栈中,直接更新low[2]=min(low[2],dfn[4]); j.回溯至1,从而1所有出发的边都走了一遍,这时再比较low[1]与dfn[1],发现相等,于是开始弹栈,找到2,4,3,1这四个元素,构成一个连通分量。 void Tarjan(int v){
dfn[v]=low[v]=++num;
used[v]=1;
st[++numSt]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(!dfn[u])//还没有标号的点
{
Tarjan(u);//先遍历它的子结点
GetMin(low[v],low[u]);//用子结点更新当前点的low值
}
else if(used[u]&&GetMin(low[v],dfn[u]));
}
if(dfn[v]==low[v]){
scc++;
while(1){
int u(st[numSt--]);
id[u]=scc;
used[u]=0;
if(v==u)break;
}
}
}
int main(){
for(int i=1;i<=n;++i)if(!dfn[i])Tarjan(i);
}这里有一个疑问,为什么当发现一个点v的子结点u已经在栈中时用dfn[u]来更新low[v],而不是用low[u],感觉好象两个都可以用,因为只要保证low[v]尽可能变小就行了, |
三、代码实现
割点和块
求割点的时候由于不知道最开始选的树根是不是只有一个儿子,这样在DFS过来中不会满足low[u]>=dfn[v]而判为割点,但有两个或两个以上儿子的根肯定也是一个割点,所以要特判!
void CutBlock(int v){
dfn[v]=low[v]=++cnt;
st[++top]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(dfn[u]==0){
CutBlock(u);
GetMin(low[v],low[u]);
if(low[u]>=dfn[v]){ //V是一个割点
block[0]=0;
while (true) {
block[++block[0]]=st[top];
if (st[top--] == u) //只能弹到u为止,v还可以在其他块中
break;
}
block[++block[0]]=v;//割点属于多个块,一定要补进去
Count(block);
}
}
else GetMin(low[v],dfn[u]);
}
}
割边和缩点
void CutEdge(int v,int fa){
dfn[v]=low[v]=++cnt;
st[++top]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(u==fa)continue;
if(!dfn[u]){
CutEdge(u,v);
GetMin(low[v],low[u]);
if(low[u]>dfn[v]){//边v->u为一条割边
cutE[++numE]=E(v,u);
// 将u及与它形成的连通分量的所有点存起来
++numB;
while(1){
id[st[top]]=numB;
if(st[top--]==u)break;
}
}
}
else GetMin(low[v],dfn[u]);
}
}
有向图强连通分量
<span style="font-family: Arial, Helvetica, sans-serif;">void Tarjan(int v){</span>
dfn[v]=low[v]=++num;
used[v]=1;
st[++numSt]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(!dfn[u])//还没有标号的点
{
Tarjan(u);//先遍历它的子结点
GetMin(low[v],low[u]);//用子结点更新当前点的low值
}
else if(used[u]&&GetMin(low[v],dfn[u]));
}
if(dfn[v]==low[v]){
scc++;
while(1){
int u(st[numSt--]);
id[u]=scc;
used[u]=0;
if(v==u)break;
}
}
}
这里需要注意一个地方,上面标记为紫色的那行代码,相比上面两个代码,这里加了一个used[]判断点是否在栈中,为什么前面的不要,而这里需要呢,举个例子
根据dfn可以看出搜索的顺序是1->2->5->6形成一个强连通分量(2,5,6),于是开始退栈,回溯到1从3出发到达4,此时如果直接用dfn[2]更新low[4]的话,会得到low[4]=2,变小后而与dfn[4]不再相等,不能退栈,这与最后的4形成一个单独强连通分量是不符合的,所以,不在栈中的点,不能用来更新当前点的low[]值,为什么无向图不用标记呢,那时因为,边是无向的,有边从4->2同时也必有边2->4由于2之前被标记过,而遍历到当前结点4又不是通过w(2,4)这条边过来的,则必还存在另一条路径可以使2和4是相通的,(即图中的4-3-1-2),从而2,4是双连通的。
其实以上三个算法都源于Tarjan,只是根据dfn[]和low[]判断条件不同而得到不同的结果,无限Orz Trajan !!!
于是,顺便总结一下LCA的离线算法
离线是指把所有的问题都存起来,类似邻接表的形式,能根据点v找到它关的点u,处理完后一次性回答所有的答案。
DFS到v时,用used[]标记为已访问,下面分两部分完成
1、在Q个查询中对所有与v相关连的ui,uj,uk,如果检查发现used[]为真,则说明它们的最近公共祖先为ui当前能往上最大程度找到的祖先,这个可借助并查集实现,记录结果用以后面输出。
2、对v所有子结点u(不同于上面的u),进行DFS() ,DFS结束后,设置u的父亲为v,即fa[u]=v;
时间复杂度为O(m+Q ),Q为查询的总数,dist[]记录根到当前点的距离,如果最后要求任意两点v和u之间的距离,则为dist[v]+dist[u]-2*dist[lca(v,u)]
void LcaTarjan(int v){
used[v]=1;
fa[v]=v;
for(int i=q[v];i!=-1;i=e[i].pre){ //对跟v相关每个问题,尝试进行回答
int u(e[i].d),id(e[i].id);
if(used[u])ans[id]=Find(u);
}
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d),w(edge[i].w);
if(!used[u]){
dist[u]=dist[v]+w;
LcaTarjan(u);
fa[u]=v;
}
}
}
四、例题
pku1523>>
先求割点,第二问其实就是求块,一个割点存在k个块中,删掉后,便形成k个子图
pku2942>>
求块后,对每块有:如果存在奇圈,则可以分开开会,否则全T掉,判断奇圈可以用DFS二分染色的方法,当前点染为白色,它所有相邻点染为黑色,如果最后发现某条边两个端点同色,则存在奇圈。
pku3694>>
求割边后,并标记,这时新图形成一棵树,但并不需要缩点,否则反而不好处理,每加一条边w(v,u)进去,必会形成一个圈,剩下的问题但是如何找圈,事先求出v,u的最小公共祖先,加入边w(v,u)后,则这个圈的一部分便是从v到lca(v,u)之间的树边,另一部分是u到lca(v,u)之间的树边,由于一个图中割边的总条数不会超过n,所以可用割边关联的两个顶点中的一个来记录它的位置,这样在沿v或u向lca(v,u)往上找时,快速判断它与它父亲之间相连的边是否为割边,是的话ans-- 并标记为非,因为w(v,u)的加入形成了环,环中原来所有的割边都会变成非割边。用fa[v]表示v的父亲,set[v]表示v的祖先,虽然初始都表示v的父亲,但在LCA时要区分使用,一个只记录它的直接父亲,另一个并查集时压缩路径会改变。
pku 3352>> pku3177>>
求割边,缩点后,形成一棵树,统计度为1的点个数t,需要连的边数则为(t+1)/2 ,pku3177只是多了重边处理,方法见上。
hdu3394>> 求块,如果一个块的顶点数等于边数,则这个块只有一个环,如果边数大于点数,则必有多个环,容易知道在一个K环的块中,每条边也必属于K个环,这样可以计算出在一个环和多个环里的边总数,剩下的便是不在环中的边。
hdu 3394 Railway 无向图求块
| hdu 3394 >> 求在0个环、1个环、多个环里的边的条数 问题转化为无向图求块,即缩块。块是不存在割点的连通子图,如果一个块的顶点数等于边数,则这个块只有一个环,如果边数大于点数,则必有多个环,容易知道在一个K环的块中,每条边也必属于K个环,这样可以计算出在一个环和多个环里的边总数,剩下的便是不在环中的边。 #define arr 10010
#define brr 500010
struct Edge{
int d,pre;
Edge(){}
Edge(int d1,int pre1):d(d1),pre(pre1){}
}edge[brr];
int p[arr];
int pn;
int dfn[arr];
int low[arr];
bool used[arr];
int cnt;
int block[arr];
int n,m;
int none,one,two;
int st[arr];
int top;
int fa[arr];
void Insert(int v,int u){
edge[++pn]=Edge(u,p[v]);p[v]=pn;
edge[++pn]=Edge(v,p[u]);p[u]=pn;
}
void Count(int* block){
FF(i,block[0])used[block[i]]=1;
int sum(0);
FF(i,block[0]){
int v(block[i]);
for(int j=p[v];j!=-1;j=edge[j].pre){
int u(edge[j].d);
if(used[u])sum++;
}
}
sum/=2;
if(sum==block[0])//点和边总数一样多,刚好一个环
one+=sum;
else if(sum>block[0])//边比点多,存在多个环
two+=sum;
else none+=sum;
FF(i,block[0])used[block[i]]=0;
}
void DFS(int v){
dfn[v]=low[v]=++cnt;
st[top++]=v;
for(int i=p[v];i!=-1;i=edge[i].pre){
int u(edge[i].d);
if(dfn[u]==0){
fa[u]=v;
DFS(u);
GetMin(low[v],low[u]);
if(low[u]>=dfn[v]){
block[0]=0;
while (true) {
block[++block[0]]=st[top-1];
if (st[--top] == u)
break;
}
block[++block[0]]=v;
Count(block);
}
}
else if(u!=fa[v]) GetMin(low[v],dfn[u]);
}
}
void Work(){
clr(dfn,0);clr(low,0);
clr(used,0);
cnt=none=one=two=top=0;
FF(i,n){
if(dfn[i]==0)DFS(i);
}
printf("%d %d\n",none,two);
}
int main(){
while(scanf("%d%d",&n,&m)!=EOF){
if(n+m==0)break;
clr(p,-1);pn=0;
FF(i,m){
int v,u;
scanf("%d%d",&v,&u);
v+=1;u+=1;
Insert(v,u);
}
Work();
}
return 0;
} |