从内存角度深入看结构体(window/linux)大小
今天我们来看一下windows(32, 64)(dev-c++,vc),linux(32, 64)不同系统下,
它们求结构体大小时,编译器到底给它们分配了哪些内存,又为什么这样分配,为啥子编译器给它们有时空闲3个内存块,有时候又空闲7个内存块,为什么啊,为什么啊
当你们读了上面的内容,还想继续往下看的时候,就说明你开始关注内存的分配问题了,哈哈!!!
关于内存对齐:
简单地理解就是:程序中,数据结构中的变量等等都需要占用内存,系统采用内存对齐,就可以提高访问速度(为了访问未对齐的内存,处理器需要作两次内存访问,而经过内存对齐一次就可以了)
大家看下面这个程序:
#include <stdio.h>
struct stu{
char a;
int b;
char c;
};
int main(){
struct stu ss;
printf("%d\n", sizeof(ss));
printf("%p\n", &ss.a);
printf("%p\n", &ss.b);
printf("%p\n", &ss.c);
return 0;
}
当前结构体里面的成员类型是:(char , int, char)
下面大家看程序运行结果:
结果一:
win7,32位,vc中
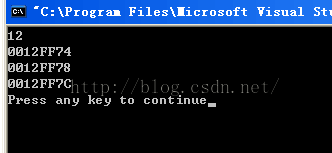
win7,64位,vc中
结果二:
win7,32位,dev-c++中
win7,64位,dev-c++中
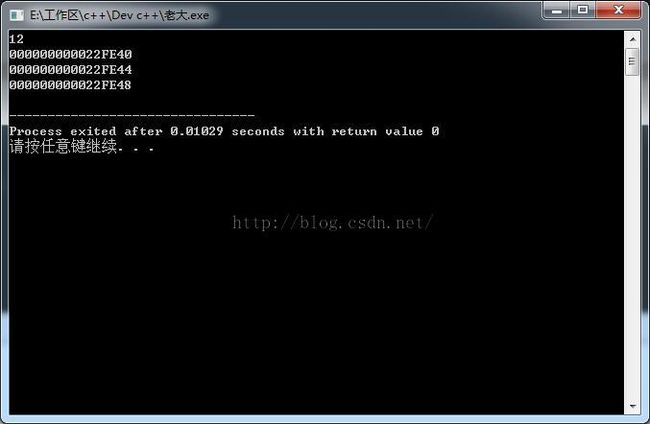
我们知道这涉及一个概念——偏移量
网上给出的解释是:它指的是结构体变量中成员的地址和结构体变量地址的差。
结构体大小的定义是:结构体的大小等于最后一个成员的偏移量加上最后一个成员的大小
哈哈,听饶了吧!
其实,当前偏移量的大小就是编译器为前面变量所分配的内存个数。
大家先看一下上面结构体在内存中(下面的是在dev中分配的)的情况
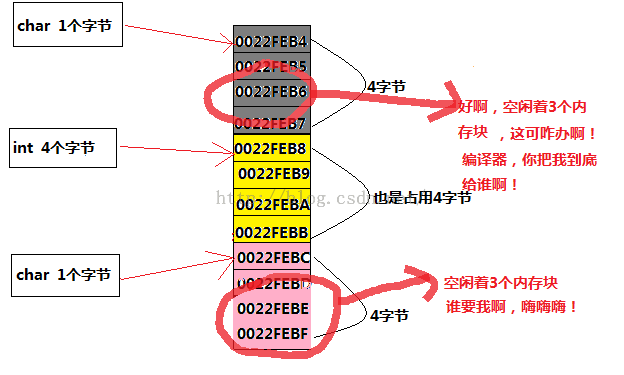
首先,我们知道编译器给一些变量分配内存的时候,它是一个连续的块,它是以一个4字节简单对其的
如上图所示:
编译器首先分配了一块地址也就是:0022FEB4给了结构体的首地址(也就是结构体中的成员a)因为它是一个字符,它占用一个内存地址,第二个是int类型,它占用4个字节,第一组已经用掉一格,还剩3格,肯定无法放下int型,考虑到内存对齐,所以不得不把它放到第二个组块(0022feb8),第三个类型是char类型,跟第一个类似,占用一个存储块(0022febc),(又因为它是4字节简单对齐方式),所以空闲的三个存储块也同样分给了当前这个结构体。
好,我们接下来继续分析:
看代码2:
#include <stdio.h>
struct stu{
char a;
char b;
int c;
};
int main(){
struct stu ss;
printf("%d\n", sizeof(ss));
printf("%p\n", &ss.a);
printf("%p\n", &ss.b);
printf("%p\n", &ss.c);
return 0;
}哈哈,可别看错了,我可跟上面的代码不一样哎!!!!!
(结构体里面定义的成员是: char, char , int)
好,下面大家看一下运行结果:
win7,32位,vc中
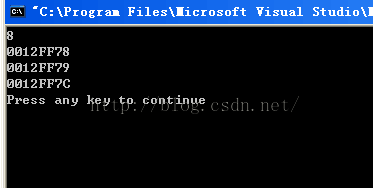
win7,32位,vc中
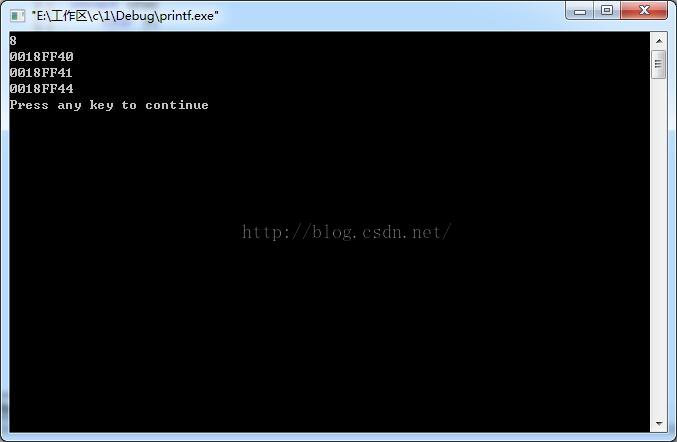
结果二:
win7,32位,dev-c++中
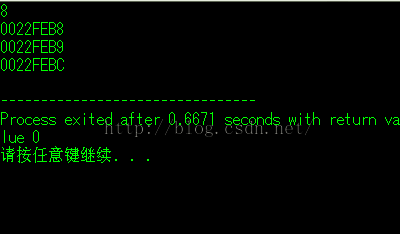
win7,32位,dev-c++中

来,不要急,我们接着看内存,分析分析它:
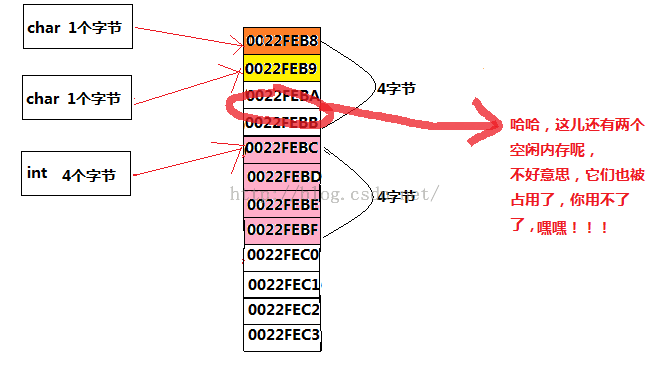
同样的道理:当前结构体中,第一个类型是char类型,它占用一个字节(也就是0022FEB8),然后,接下来第二个类型还是char,占用一个字节,又因为上一组4个字节(其中0022FEB9,0022FEBA, 0022FEBB均空着)还空着3个,可以放下第二个char,所以第二个char就放在了内存(0022FEB9)处,然后碰到int类型中,占用4个字节,上一组4个字节中还剩下两个空闲(其中0022FEBA, 0022FEBB),不够放int类型,所以,新找了另一组连续的4个字节。所以说:当前结构体总总共占用8个字节。
哈哈,所以说:结构体中,编译器为所分配的所有空闲内存(满足4字节简单对齐)都算在内,总的结构体大小也就相应的出来了。
简单的说:结构体的成员变量类型(如1:char, int , char 如2:char, char, int),它们成员一样,但顺序不一样,编译器给分配的内存也不一样,我们应尽可能的使其内存占用的少一点,这样,总的来说对我们的程序运行只有好处。
这回大家明白的差不多了吧!接下来我们分析一个不一样的东西
看代码3:
#include <stdio.h>
struct stu{
char a;
double b;
char c;
};
int main(){
struct stu ss;
printf("%d\n", sizeof(ss));
printf("%p\n", &ss.a);
printf("%p\n", &ss.b);
printf("%p\n", &ss.c);
return 0;
}
我们可以很清楚的看明白上面这个结构体的成员变量是(char , double , char)
所以我们的运行结果是:
win7,32位,vc中:
win7,64位,vc中:
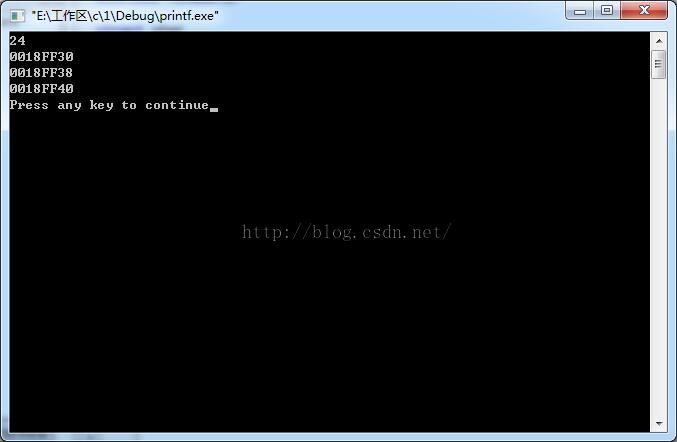
结果二:
win7,32位,dev-c++中
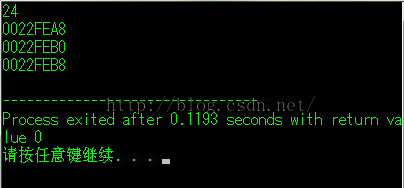
win7,64位,dev-c++中
接下来再看一个小的程序:
代码4:
#include <stdio.h>
struct stu{
char a;
int e;
double b;
char c;
};
int main(){
struct stu ss;
printf("%d\n", sizeof(ss));
printf("%p\n", &ss.a);
printf("%p\n", &ss.e);
printf("%p\n", &ss.b);
printf("%p\n", &ss.c);
return 0;
}
我们也可以直接看到:这个结构体成员是(char , int , double , char )
好,我们在看一下简单地运行结果:
win7, 32, dev:
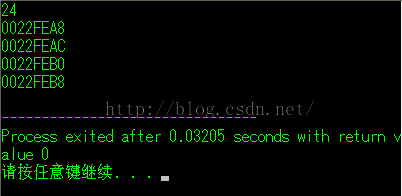
win7, 64, dev:
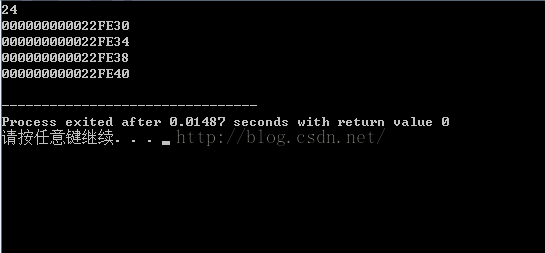
下面是win7,32,vc
下面是win7,32,vc

哈哈,不要害怕它们为什么都是24,,接下来我们需要在看一下他们的内存分配情况,
下面这个图是代码3的图:
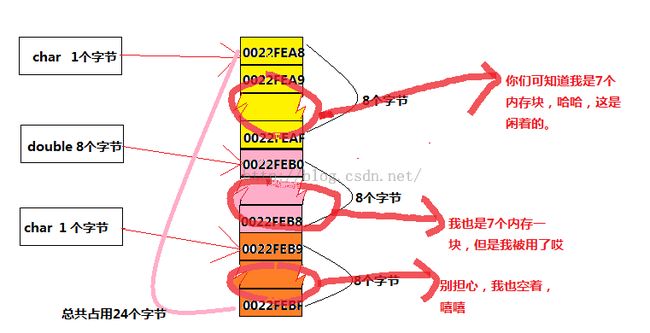
代码4的这个内存图(将代码1和代码2的内存图给结合起来了),
哈哈,太难画了,我在这里就不画了啊,大家应该可以理解的
好,接着继续分析内存情况
我们前面提到的在代码1,代码2中内存是简单地4字节对齐,所以我们一直在找4个字节来存放他们(也就是简单地说,char后面如果跟着int类型,那么就会出现3个空闲),
而到了我们这个代码3, 4, 内存就是简单地8字节对齐,所以我们一直在找8个字节来存放他们,(也就是简单地说,char后面如果跟着double类型,那么就会出现7个空闲)
这又是为了什么?
这里我们又要提一下内存的自然对齐了
自然对齐就是说:每一种数据类型都必须放在内存地址中的整数倍上,举一个简单地例子
(地址4)可以放char类型的,也可以放int类型,也可以放short,但是但是就是不可用存放double类型,仅仅只是因为它不是8的整数倍,OK, 就是这么简单。
(地址3)可以用来存放char类型,但是不可用用来存放int, short, double ,也只是因为它们不是整数倍关系
(声明一点,地址0是任何类型整数倍的, 这一点,我们可以这样记着,理解为,可以存放任何数据类型)
所以说:在windows下:
所以,此时也就很好解释上面的几种情况了,哪些空闲的内存块,就是因为它们本身不是数据类型的整数倍,所以被留了下来,在加上为了访问便利,所以才出现了内存对齐这么一说的吧!(个人简单理解),其实我们这样想想,也就这么回事
那么在linux下又是什么样子的呢????
接下来我们继续看:
代码5(在linux下):
#include <stdio.h>
#include <sys/cdefs.h>
struct str{
char a;
int b;
char c;
};
int main(){
struct str A;
printf("%u\n", sizeof(A));
printf("%p\n", &(A.a));
printf("%p\n", &(A.b));
printf("%p\n", &(A.c));
return 0;
}
这样看,我们知道此时结构体里面的成员类型是: char ,int , char
好,我们大家一起看运行结果:
linux(ubuntu),64位,:
linux(ubuntu),32位
这时,我们可以看到上面的内存分配是一样的。就是说他们遵从的基本准则是一样的(可以简单的理解为:跟window下面是一样的,(简单的四字节对齐))
好了,我们接下来继续看另外一种情况:
代码6(在linux下)
#include <stdio.h>
#include <sys/cdefs.h>
struct str{
char a;
double b;
char c;
};
int main(){
struct str A;
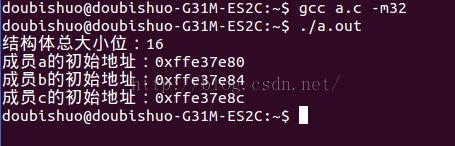
printf("结构体总大小位:%lu\n", sizeof(A));
printf("成员a的初始地址:%p\n", &(A.a));
printf("成员b的初始地址:%p\n", &(A.b));
printf("成员c的初始地址:%p\n", &(A.c));
return 0;
}
这时,我们也可以很清楚的看到当前结构体的成员变量类型是: char , double , char
好了,我们接着往下看:运行结果:
liunx(ubuntu下),64位:

linux(ubuntu下), 32位:
哈哈,不一样了吧,懵了吗?不要紧,接着继续看内存分配:
(下图是64位的简单内存分配图)

下面是(32位的简单内存分配图)
好了,这回我们也看到了,在编译器的分配下,
linux(64位) :它是跟window底下的说法是一样的,对于double这个类型,它的初始地址就是仅仅只能在8的倍数的地方,也就是上面我们所说的遵从的是内存的自然对齐,所以(char后面是double的话,它会出现7个空闲区)
linux(32位):它是跟window是不一样的,但是也很好理解,就是说,它的所有东西都是遵从(基本的4字节对齐),而32位的编译器,将其(double)处理成了两个4字节,所以才会出现上面的情况,或者说对于double而言编译器不考虑它的自然对齐,(所以说char后面出现double的话,它会出现3个空闲区)
好了,大家伙:
现在我们来总结一下:
对于windows,关于结构体也就是说,我们不用考虑什么偏移量,什么加什么啊,那些都太麻烦了,只需要明白内存的自然对齐就ok了,(不管什么32,64位)
然而,对于linux下,对于64位:跟window一样就ok了,
而linux下,32位:就用简单的4字节对齐就0k了,遇到double的话,简单的将其当作两个4字节就ok了。
(ps,哎呀吗,太累了,画图太多了,真心不容易啊,但是么事,心不累,哈哈!!!)
上面的内容全是个人理解(均经过内存验证),若有不理解,或是疑问,欢迎指出.