规则引擎研究(一)——Rete算法(4)——Rete算法的特例Uni-Rete算法
(注:本文参考自
Tambe, M., Kalp, D., and Rosenbloom,P. (1991). Uni-Rete: Specializing the Rete match algorithm for the unique-attribute representation. Technical Report CMU-CS-91-180,School of Computer Science, Carnegie Mellon University.
Tambe, M., Kalp, D., and Rosenbloom,P. S. (1992). An effcient algorithm for production systems with linear-time match. In Proceedings of the Fourth IEEE International Conference on Tools with Artiial Intelligence, pages 36-43.)
Uni-Rete:一种特有属性表示法(unique-value)的特殊Rete匹配算法
一、 Uni-Rete简介
产生式系统(基于规则的系统)中的组合匹配(the combinatorial match)在许多应用领域中带来了问题:如在实时系统中,人类认知建模,并行系统等。特有属性表示法(unique-attribute representation)可以有效的解决组合匹配问题。Uni-Rete是对Rete匹配算法进行约束,使用了特有属性表示法,实验结果显示其匹配过程的速度比Rete算法快10倍。
[Tambe and Rosenbloom 1989]通过引入特有属性表示法(unique-attribute representation)消除了产生式匹配中的组合问题。使用特有属性,匹配的时间与规则数目成线性关系。Uni-Rete是Rete算法的特例化,在Soar系统中,Uni-Rete比Rete快10倍。
二、 Rete算法
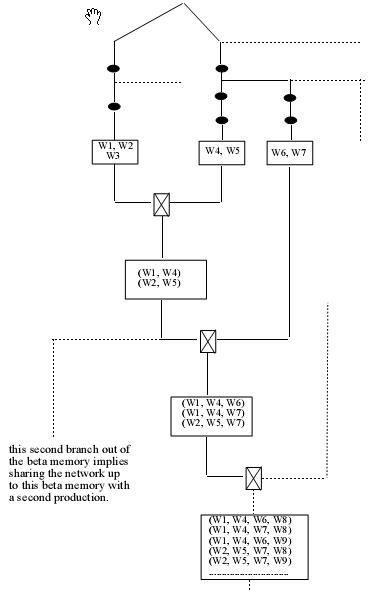
上图是一个通过使用Rete算法进行匹配的例子。
但是,在一个实际的产生式系统中,规则的数目非常多,从而整Rete网络很复杂,如下图所示。从图中可见,网络中的beta内存中可能存在大量的tokens。产生式匹配中的组合问题指beta内存中tokens的组合个数。在最糟糕的情况下,一条产生式可能产生O(WC)个tokens,其中W是事实个数,C是条件个数。Beta内存中有可能存放如此多的tokens,而tokens的数目在编译时无法确定,Rete使用如链表这样的动态结构来存储tokens。通过使用hash表可以对Rete算法进行优化。尽管如此,匹配过程中的主要花费的时间集中在对beta内存的处理中。
三、 特有属性表示法(The Unique-attribute Representation)
产生式匹配过程中的组合问题的是因为不知道到底哪一个事实最终可以匹配某个条件。在一个有很多条件的产生式中,这样的不确定性带来的级联效应(cascading effect)有可能带来与条件个数成指数关系的匹配时间。这种不确定性表现在当对某个条件进行匹配时有可能出现很多对此条件的部分匹配,每个部分匹配都是一个token。采用特有属性表示法可以消除在匹配过程中的不确定性。使用特有属性表示法,每个条件最多只对应着一个token,从而可以消除产生式匹配过程中的组合匹配问题。
这里我们采用(class object attribute value)这样的四元组来表示一个条件,下图所示即为这样的一个产生式。
所谓的特有属性表示法指:给定某个class, object和atrribute,只允许对应某个特定的value。下面a图所示的三个事实不是特有属性表示法,因为三个条件的class,object,attribute均相同,而B1, B2, B3却是三个不同的value。正是因为给定前三个部分相同的字段(field),而却有不同value导致了匹配过程中的不确定性。b图中显示的是特有属性表示法。
另外,特有属性表示法,对产生式中的条件也有约束,即,在object出现的变量必须预先绑定(pre-bound),即,必须在此更前面的条件中出现。
特有属性表示法通过对事实和条件的约束,保证了匹配代价与条件个数成线性关系。即beta内存中最多含有一个token。
特有属性表示法已经成功地运用到Soar中的各种任务中,包括了一些含有500或更多产生式的任务。在这些任务中,特有属性表示法改善了问题解决的性能,去除了代价很高的学习型规则,因此,使研究人员摆脱了产生式系统的效率问题。当然,对Uni-Rete的进一步加速仍然是必要的。
一般来说,特有属性表示法通过牺牲一些表达能力来获得匹配中的效率。这主要表现在两方面,一方面,使用特有属性表示法很难对工作内存中的非结构化数据进行编码,另一方面,特有属性表示法可能削弱学习型产生式(learned production)的归纳能力。
四、 Uni-Rete算法
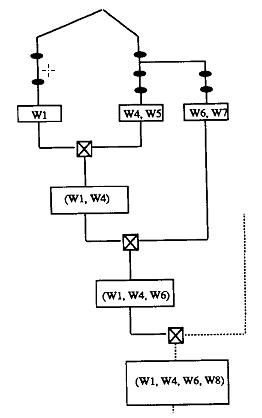
下面的左图示意了使用Rete算法对使用的特有属性表示法的规则系统处理的过程。图中,每一个beta内存仅包括一个token。尽管如此,Rete算法仍然像以前一样的创建存储tokens,并且同样进行了大量的内存管理。
Uni-Rete充分利用了每一个bete内存中最多有一个token的性质,减少了对token的内存管理。仅有小部分的token存储在给定内存中,大部分的都存储在其前面的beta内存中。如下面的右图所示。左图中存储(w1, w4)的beta内存,在右图中仅仅存储了(w4),因为此beta内存的前面的alpha仅仅包括单独一个事实(w1)。相似的,在左图中存储(w1, w4, w6)的token,在右图中,仅需要存储(w6),剩下的部分隐含在其前面的beta内存之中。因此,通过仅仅存储一个单独的事实,来存储整个token。另外,存储所需的空间可以事先分配好,因为仅含有一个事实,从而可以避免rete算法中的动态内存管理。
Uni-Rete算法仅仅适用于使用特有属性表示法的系统中,因为,如果beta内存中有多个tokens,那么就无法确定哪些事实构成某个token。因此,Uni-Rete的这种隐含存储(implicit storage)不能用在非限制的产生式系统中。
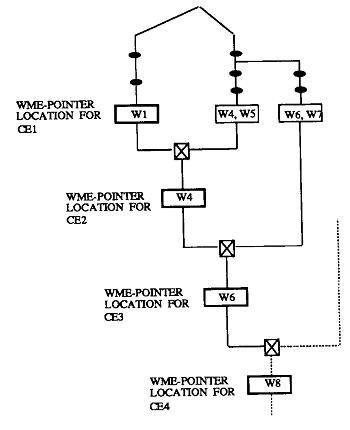
使用上面的右图来说明Uni-Rete的添加和删除某个事实的操作。假设图中的事实w6和w8尚未添加,下面加入事实w6:
第一步,对w6进行常量测试(constant tests),把w6存入右图所示的alpha内存中。
第二步,检查前一个条件的事实指针是否为空。如果是空则添加事实操作结束,不空则进入第三步,如检查w6对应条件的前一个条件的事实指针,此处指向w4,非空,进入第三步。
第三步,与前面的条件对应的事实进行一致性测试。如,检查w4和w6是否含有一致绑定。
第四步,存储指向新事实的指针。如果第三步检测成功,在相应位置存储指向新事实的指针。如,w4, w6是一致绑定,则存储指向w6的指针。如果测试失败,不进行任何下一步操作。
第五步,匹配下一个条件。检查下一个条件对应的alpha内存,是否匹配。若成功,则存储指向那个事实的指针。如,例子中,检查w6和条件4对应的事实是否一致绑定。如果成功,则存储指向条件4对应的那个事实的指针。重复第五步直道下一个条件不匹配。
如果出现指向最后一个条件的指针,则匹配成功。
当删除某个事实时:
第一步,从alpha内存中删除此事实。例如,删除w6时,通过常量检测发现w6,并从alpha内存中删除。
第二步,检测时候有指针指向被删除的事实。如,检测是否有指针指向w6,如果有,进入下一步,没有,则删除操作结束。
第三步,置被删除事实的对应的指针为空。如,置指w6的指针为空指针。
第四步,置所有后继的指针为空。
对token内存的优化,是Uni-Rete算法对Rete算法对主要的优化。通过此优化,有三方面优点,第一,beta内存节点的空间可以事先分配,避免了Rete算法中的内存分配回收操作。第二,beta内存节点仅仅存储指向事实的指针,从而避免了复制大量事实到当前beta内存中。第三,避免了对tokens的hashing操作。
五、 Uni-Rete网络的双线性(bilinear)组织
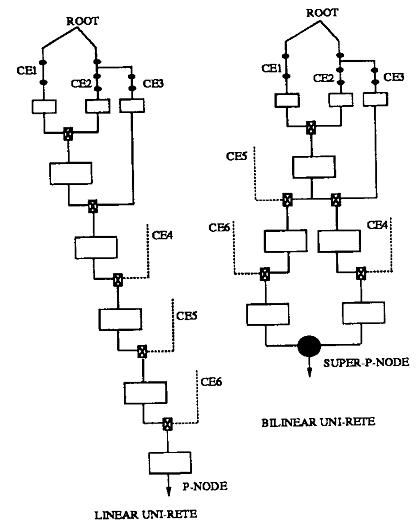
以上所讨论的Uni-Rete算法都是基于线性的网络。即,每一个条件加入网络时都是加入到一条产生式的所有前面的条件之后。但是,可以把这个网络组织成双线性(bilinear)的形式。即可以把某个条件加入到其部分前驱条件之前,而不必是所有的前驱条件前。下图说示即为线性Uni-Rete与双线性Uni-Rete的对比图。双线性Uni-Rete中,包括两部分条件链,(CE1,CE2,CE3,CE4)和(CE1,CE2,CE3,CE4)。这两部分被一个super-p-node连接起来。Super-p-node进行在biliner中未能进行的一致性检查。
使用biliner结构的好处实现是更大程度的共享。缺点是增加了在super-p-node 中的一致性检测的操作。
在一般情况下,采用biliner一般会降低Rete算法的性能,这是因为,1、增加了匹配活动;2、实现复杂;3、共用程度可能没有在使用特有属性表示法的系统高。

六、 评论
Uni-Rete是Rete的一个特殊情况,可以很容易的与Rete结合使用。Uni-Rete可以用在部分含有特有属性表示法的系统中。可以有两种方法把Uni-Rete和Rete结合起来使用,一种是把Uni-Rete用于特有属性的产生式,把Rete用于其它产生式;另一种是在一条产生式中,把Uni-Rete用于特有属性表示的条件中,而把Rete用于其它条件中。
Uni-Rete的一个贡献是通过减少对tokens的动态内存管理而提高性能。像Rete这样的匹配算法都假定tokens的数目在匹配时无法确定,因此需要动态分配内存。而在很多情况下,token内存的大小可以预测,Uni-Rete便利用这一特点使用静态数据结构来提高性能。