关于NoSQL数据库LiteDB的分页查询解决过程
1.关于数据库排序与分页
2.LiteDB的查询排序
3.LiteDB分页之渐入佳境
4.LiteDB的疑问
5.资源
在文章:这些.NET开源项目你知道吗?让.NET开源来得更加猛烈些吧!(第二辑) 与 .NET平台开源项目速览(3)小巧轻量级NoSQL文件数据库LiteDB中,介绍了LiteDB的基本使用情况以及部分技术细节,我还没有在实际系统中大量使用,但文章发布后,有不少网友( loogn)反应在实际项目中使用过,效果还可以吧。同时也有人碰到了关于LiteDB关于分页的问题,还不止一个网友,很显然这个问题从我的思考上来说,作者不可能不支持,同时也翻了一下源码,发现Find方法有skip和limite参数,直觉告诉我,这就是的。但是网友进一步提问,这个方法并不是很好用,它也没有实现的分页的情况。所以就亲自操刀,看看到底是神马情况?不看不知道,这个过程还真的不是那么回事,不过还是能解决啊。
.NET开源目录:【目录】本博客其他.NET开源项目文章目录
本文原文地址:.NET平台开源项目速览(7)关于NoSQL数据库LiteDB的分页查询解决过程
1.关于数据库排序与分页
在实际的项目中,对于关系型数据库,数据查询与排序都应该好办,升序或者降序呗,但是对数据库的分页应该不是直接的函数支持,也需要自己的应用程序中进行处理,然后使用top或者limite之类的来查询一定范围内的数据,作为一页,给前台。例如下面的SQL语句:
|
1
2
|
Select
top
PageSize *
from
TableA
where
Primary_Key
not
in
(
select
top
(n-1)*PageSize Primary_Key
from
TableA )
|
数据的分页过程中,我们也看到在根据指定条件查询后,就是记录集的筛选,所以对于NoSQL数据库来说,因为没有了SQL,这些问题不会像常规关系型数据库那么突出,毕竟你选择了NoSQL,在大数据面前,如果动不动就查几千条数据来分页,也是明显不合适的。在我的观点中,要尽量避免无谓的查询浪费,也不会有人专门去看几千甚至几万条记录,如果有,也只是从中找到一部分数据,既然这样何必不一开始就增加条件,过滤掉那些没用的数据呢。所以数据库的那些事,业务的合理性也很重要,数据库也是机器,他们能力也有限,动不动就仍那么多沉重的任务给它,也会受不了啊。
2.LiteDB的查询排序
2.1 测试前准备工作
为了便于本文的相关代码演示,我们使用如下的一个实体类,注意Id的问题我们在前面一篇文章中已经说过了,默认是自增的,不需要处理。加进来是为了方便查询和分页。实体类基本代码如下:
|
1
2
3
4
5
6
7
8
9
|
public
class
Customer
{
/// <summary>自增Id,编号</summary>
public
int
Id {
get
;
set
; }
/// <summary></summary>
public
int
Age {
get
;
set
; }
/// <summary>姓名</summary>
public
string
Name {
get
;
set
; }
}
|
然后我们使用如下的方法插入20条记录,注意该函数是数据初始化,只需要运行一次即可。会在bin目录生成Sample数据库文件。我们只拿这些数据做测试。至于以后大数据的查询以及分页效率问题,暂时不考虑,我们只单独处理分页的情况。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
static
void
InitialDB()
{
//打开或者创建新的数据库
using
(
var
db =
new
LiteDatabase(
"sample.db"
))
{
//获取 customers 集合,如果没有会创建,相当于表
var
col = db.GetCollection<Customer>(
"customers"
);
for
(
int
i = 0; i < 20; i++)
{
//创建 customers 实例
var
customer =
new
Customer
{
//名字循环改变
Name = i % 2 == 1 ?
"Jim1_"
+ i.ToString() :
"Jim2"
+ i.ToString(),
Age = i,
};
// 将新的对象插入到数据表中,Id是自增,自动生成的
col.Insert(customer);
}
}
}
|
上面的Name是交替改变的,Jim1和Jim2加上编号,而Age是默认逐步增加了,主要是为了测试排序的情况。
2.2 基本查询与分页问题
我们在前面介绍LiteDB的基础文章。。中,对基本查询做了介绍。方法很灵活。针对上面的例子,我们假设一个查询分页的需求:
查Customer表中,Name以"Jim1"开头的人集合,按Age降序排列,每3条记录一页,打印每一页的Age列表。
针对上面问题,我们需要先简单分析一下问题:
1.查询获取记录的总数,可以使用Find或者Count方法直接获取;
2.查询条件的是Name,可以使用Linq或者Query来进行;
3.由于LiteDB是NoSQL的,所以不支持内部直接排序了,只能使用Linq的OrderBy或者OrderByDescending了;
4.关于分页,还是选择和SQL数据库类型的方法,使用linq的skip方法来跳过一些记录。这里留个疑问,因为自己技术有限,平时也只使用基本的linq操作,所以只想到了Skip,知道的朋友接着往下看,别吐槽。解决问题的最终结果可能很简单,但是过程还是值得回味的,一步步也是学习和总结优化的过程。
3.LiteDB分页之渐入佳境
由于Linq的Take以前不知道,所有走了一些弯路,同时LiteDB的Find方法中的重载函数之一,skip参数也有一些问题,下一节讲到具体问题。
3.1 第一次小试牛刀
考虑到类似SQL的limite和top查询,我们也在LiteDB中使用这种方式。由于Linq有一个Skip方法,所以选择它来完成具体数据的选择,相当于每次都选择最后几条。看代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
//打开或者创建新的数据库
using
(
var
db =
new
LiteDatabase(
"sample.db"
))
{
//获取 customers 集合,如果没有会创建,相当于表
var
col = db.GetCollection<Customer>(
"customers"
);
//1.计算总的数量
var
totalCount = col.Count(Query.StartsWith(
"Name"
,
"Jim1"
));
//2.计算总的分页数量
Int32 pageSize = 3 ;
//每一页的数量
var
pages = (
int
)Math.Ceiling((
double
)totalCount / (
double
)pageSize);
//3.循环获取每一页的数据
Int32 current =
int
.MaxValue;
for
(
int
i = 0; i < pages; i++)
{
//查找条件,附加了Id的范围,第一次是最大,后面进行更新
var
data = col.Find(n => n.Name.StartsWith(
"Jim1"
) && n.Id < current)
.OrderBy(n => n.Age)
//要求是降序,由于要选择最后的,只能先升序
.Skip(totalCount - (i + 1) * pageSize)
//跳过前面页的记录
.OrderByDescending(n => n.Age);
//降序排列
current = data.Last().Id;
//更新当前查到的最大Id
//把Id按照页的顺序打印出来
String res = String.Empty;
foreach
(
var
item
in
data.Select(n => n.Age)) res += (item.ToString() +
" , "
);
Console.WriteLine(res);
}
}
|
结果如下:
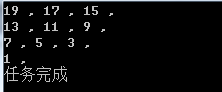
最后1也只有1条记录,总共10条记录也是正常的,总共20条,交替插入的。缺点有几个:
1.效率比较低,每次都选最后的
2.只能从第1页获取,不能获取单独页的,因为上一次的Id不能得到
3.2 完全使用Linq分页
后来发现了Take方法,虽然我猜测应该有,但苦于自己疏忽,导致寻找的时候错过了,后来自己打算重新写一个的时候,又去确认一遍的时候才发现。因为skip都可以实现,没道理Take不实现啊,原理都是一样的。如果实现也很简单的。那看看改进版的基于Linq的分页。没有上面那么麻烦了:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
//根据页面号直接获取
static
void
SplitPageByPageIndex(
int
index)
{
using
(
var
db =
new
LiteDatabase(
"sample.db"
))
{
var
col = db.GetCollection<Customer>(
"customers"
);
//1.计算总的数量
var
totalCount = col.Count(Query.StartsWith(
"Name"
,
"Jim1"
));
//2.计算总的分页数量
Int32 pageSize = 3;
//每一页的数量
var
pages = (
int
)Math.Ceiling((
double
)totalCount / (
double
)pageSize);
//查询条件
var
data = col.Find(n => n.Name.StartsWith(
"Jim1"
))
.OrderByDescending(n => n.Age)
//降序
.Skip(index * pageSize)
//跳过前面页数数量的记录
.Take(pageSize);
//选择前面的记录作为当前页
//把id按照顺序打印出来
String res = String.Empty;
foreach
(
var
item
in
data.Select(n => n.Age)) res += (item.ToString() +
" , "
);
Console.WriteLine(res);
}
}
|
结果如下:
和上面是一样的,但这个显然要简洁多了。更加灵活,而且不用降序和升序直接转换,一次就够。
3.3 终极解决之扩展分页方法
根据上面方法,我们可以扩展到LiteDB中去,虽然我一直认为这一点可以做到,但是研究了很久的源码,测试一直不成功,详细内容第4节介绍。
我选择直接在源代码里面扩展,当然也可以单独写一个扩展方法,不过源码里面更好用,相当于给Find增加一个重载方法,我们在源代码的Find.cs中增加下面的方法,详细看注释:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
/// <summary>分页获取记录</summary>
/// <typeparam name="TOder">排序字段类型</typeparam>
/// <param name="predicate">linq查询表达式</param>
/// <param name="orderSelector">排序表达式</param>
/// <param name="isDescending">是否降序,true降序</param>
/// <param name="pageSize">每页大小</param>
/// <param name="pageIndex">要获取的页码,从1开始</param>
/// <returns>分页后的数据</returns>
public
IEnumerable<T> FindBySplitePage<TOder>(Expression<Func<T,
bool
>> predicate,
Func<T, TOder> orderSelector, Boolean isDescending,
int
pageSize,
int
pageIndex)
{
var
allCount = Count(predicate);
//计算总数
var
pages = (
int
)Math.Ceiling((
double
)allCount / (
double
)pageSize);
//计算页码
if
(pageIndex > pages)
throw
new
Exception(
"页面数超过预期"
);
if
(isDescending)
//降序
{
return
Find(predicate)
.OrderByDescending(orderSelector)
.Skip((pageIndex - 1) * pageSize)
.Take(pageSize);
}
else
//升序
{
return
Find(predicate)
.OrderBy(orderSelector)
.Skip((pageIndex - 1) * pageSize)
.Take(pageSize);
}
}
|
下面还是使用上面的例子,直接进行调用:
|
1
2
3
4
5
6
7
8
9
|
var
db =
new
LiteDatabase(
"sample.db"
);
var
col = db.GetCollection<Customer>(
"customers"
);
//取第二页,降序
var
data = col.FindBySplitePage<Int32>(n => n.Name.StartsWith(
"Jim1"
), n => n.Age,
true
, 3, 2).ToList();
//把id按照顺序打印出来
String res = String.Empty;
foreach
(
var
item
in
data.Select(n => n.Age)) res += (item.ToString() +
" , "
);
Console.WriteLine(res);
Console.WriteLine(
"任务完成"
);
|
结果如下,调用总体比较简单,直接使用linq,输入页面数量和页码就可以了。当然不需要排序也可以,大家可以根据实际情况优化一下。
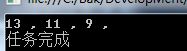
到这里,分页的问题基本是解决了,但还得说一下研究LiteDB遇到的坑。
4.LiteDB的疑问
先看看下面一段普通的代码,查询出来的记录的Id的变化情况,没有排序:
|
1
2
3
4
5
6
7
8
9
|
using
(
var
db =
new
LiteDatabase(
"sample.db"
))
{
var
col = db.GetCollection<Customer>(
"customers"
);
var
data = col.Find(n => n.Name.StartsWith(
"Jim1"
));
//普通查询
//把Id按照页的顺序打印出来
String res = String.Empty;
foreach
(
var
item
in
data.Select(n => n.Id)) res += (item.ToString() +
" , "
);
Console.WriteLine(res);
}
|
结果如下:
|
1
|
2 , 12 , 14 , 16 , 18 , 20 , 4 , 6 , 8 , 10 ,
|
是不是很奇怪?没有想象的是按照顺序输出。所以这个坑花了我好长时间,怎么试就是不行,既然这样的话,那么使用LiteDB自带的下面这个方法:
|
1
|
public
IEnumerable<T> Find(Expression<Func<T,
bool
>> predicate,
int
skip = 0,
int
limit =
int
.MaxValue)
|
就有问题。这个方法skip的是按照上述顺序的。所以追根到底,还是因为直接的使用排序的方法?这里打个问号吧,说不定有,我没找到。如果有人比较熟悉的,可以告知一下,非常感谢。但是使用linq的方式也很容易的解决问题,应该差不了多少。
5.资源
本文的代码比较简单,所有代码都已经贴在上面了。所以就不放具体代码了,我打算好好把LiteDB的源码研究一下,为以后正式的抛弃Sqlite做准备。大家关注博客,如果研究比较深入,会把相关代码托管到github。这里研究还不够深入,代码比较简单,就省略了吧。